
Today we are announcing a new inference stack, which provides decoding throughput 4x faster than open-source vLLM, and outperforms commercial solutions including Amazon Bedrock, Azure AI, Fireworks, and Octo AI by 1.3x to 2.5x. The Together Inference Engine achieves over 400 tokens per second on Meta Llama 3 8B by building on the latest advances from Together AI, including FlashAttention-3, faster GEMM & MHA kernels, innovations in quality-preserving quantization, and speculative decoding.
We are also introducing new Together Turbo and Together Lite endpoints, starting today with Meta Llama 3, and expanding to other models soon. Together Turbo and Together Lite enable performance, quality, and price flexibility so enterprises do not have to compromise. They offer the most accurate quantization available on the market; with Together Turbo closely matching the quality of full-precision FP16 models. These advances make Together Inference the fastest engine for Nvidia GPUs, and the most accurate and cost efficient solution to build with Generative AI at production scale.
Today, over 100,000 developers and companies like Zomato, DuckDuckGo, and the Washington Post build and run their Generative AI applications on the Together Inference Engine.
"Our endeavour is to deliver exceptional customer experience at all times. Together AI has been our long standing partner and with Together Inference Engine 2.0 and Together Turbo models, we have been able to provide high quality, fast, and accurate support that our customers demand at tremendous scale."
—Rinshul Chandra, COO, Food Delivery, Zomato
Today’s release includes:
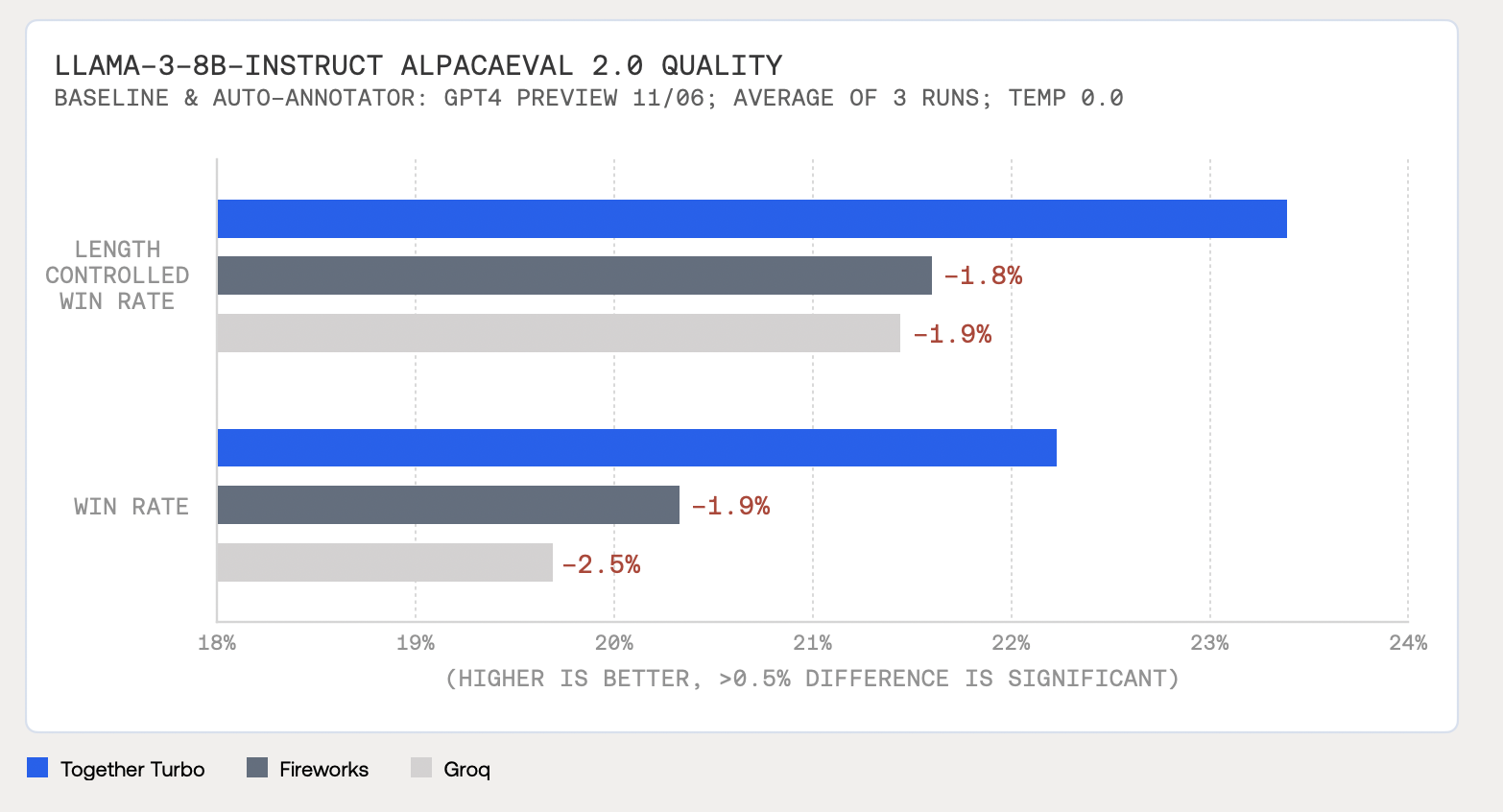
- Together Turbo endpoints, providing fast FP8 performance while maintaining quality, closely matching FP16 reference models and exceeding other FP8 solutions on AlpacaEval 2.0 by up to 1.9 points (length-corrected win rate) and up to 2.5 points (win rate) – making them the most accurate, cost efficient, and performant models available. Together Turbo endpoints are available at \$0.18 for 8B and \$0.88 for 70B, 17x lower cost than GPT-4o.
Try it now: 70B | 8B - Together Lite endpoints, which leverage a number of optimizations including INT4 quantization, provide the most cost-efficient and scalable Llama 3 models available anywhere, while maintaining excellent quality relative to full precision reference implementations. With Together Lite high-quality AI models are now more affordable than ever, with Llama 3 8B Lite priced at \$0.10 per million tokens, 6x lower cost than GPT-4o-mini.
Try it now: 70B | 8B - Together Reference endpoints, the fastest full-precision FP16 support for Meta Llama 3 models at up to 4x faster performance than vLLM.
Try it now: 70B | 8B
Together AI has been a leader in inference optimization research and is built on our own innovations, including FlashAttention-3 kernels, custom-built speculators based on RedPajama, and the most accurate quantization techniques available on the market.
Together Turbo endpoints
Together Turbo, our new flagship endpoints, provide the best combination of performance, quality, and cost-efficiency. Together Turbo endpoints leverage the most accurate quantization techniques and proprietary innovations to provide leading performance without compromising quality.
Quality
The below figures provide a comprehensive quality analysis of the Together Turbo endpoints on three leading quality benchmarks: HELM classic, WikiText/C4 and AlpacaEval 2.0. We compare Together Turbo models against our full precision reference implementation, as well as two commercial model providers, Fireworks and Groq, that provide quantized models by default.
- We ran the official HELM standard configuration which includes 1,000 instances with 3 trials for 17 tasks.
- We evaluated using the entire WikiText test set and the first one million tokens of the C4 validation set.
- Using AlpacaEval 2.0, we ran all 805 prompts 3 times and averaged the results.
Across these different quality evaluation perspectives, Together Turbo results closely match the Llama-3-8B full precision reference implementation.

Together Turbo also significantly outperforms other FP8 implementations, as shown in the following figures.


Performance
Together Turbo provides up to 4.5x performance improvement over vLLM (version 0.5.1) on Llama-3-8B-Instruct and Llama-3-70B-Instruct. Across common inference regimes with different batch sizes and context lengths, Together Turbo consistently outperforms vLLM. For Llama-3-8B-Instruct served on a single H100 GPU and Llama-3-70B-Instruct served on 8xH100 GPUs, Together Turbo achieves 2.8x-4.5x and 2.6x-4.3x decoding speedup over vLLM, respectively. Several factors contribute to these successful numbers:
- Our highly optimized and independent base engine design that encompasses our latest systems research that easily scales to new models,
- Proprietary kernels (eg: multi-head attention and GEMMs) that are optimized for quantized LLM inference serving by maximizing GPU’s hybrid core utilization and tuned for both prefill and decoding phases, and
- Our world-leading modeling and algorithmic innovations on alternative model architectures like Mamba, Hyena, and Linear Attention techniques, and our research on optimized speculative decoding methods.


Cost efficiency
Together Turbo endpoints are available through the Together API as serverless endpoints at more than 10x lower cost than GPT-4o, and provide significant efficiency benefits for customers hosting their own dedicated endpoints on the Together Cloud.
Together Turbo achieves up to 7x the capacity of vLLM (version 0.5.1), translating to up to a 7x reduction in costs.

Further, for dedicated endpoints customers switching from Together Reference to Together Turbo endpoints, on 4xH100 GPUs Together Turbo consistently achieves decoding throughput that is within 8% of Together Reference endpoints running on 8xH100 GPUs — a 2X reduction in costs.
Through innovative improvements throughout the stack Together Turbo provides leading performance, quality, and cost efficiency so you don’t have to compromise. Try Llama-3-70B-Turbo or Llama-3-8B-Turbo through the Together API now, or contact us to deploy your own dedicated endpoint on Together Cloud.
Together Lite endpoints
Together Lite endpoints are designed for applications demanding fast performance and high capacity at the lowest cost.
AlpacaEval2.0 (win rate) numbers for Together Lite and Groq show that on LC win rate Together Lite endpoints are almost identical to Groq. And for win rate, Together Lite endpoints are slightly better than Groq (+0.29%).

Compared to vLLM, Together Lite provides a 12x reduction in cost. On a range of common inference serving regimes, with only two A100 GPUs, Together Lite outperforms vLLM FP16 and FP8 running on eight H100 GPUs by up to 30%. This directly translates to the highest cost reduction and capacity improvement for the large scale production deployments.

In summary, Together Lite endpoints provide a highly economical solution with a modest compromise in quality. Try Llama-3-70B-Lite or Llama-3-8B-Lite through the Together API now, or contact us to deploy your own dedicated endpoint on Together Cloud.
Together Reference endpoints
Quality has always been at the heart of the Together Inference solution. Together Reference endpoints provide full precision FP16 quality consistent with model providers’ base implementations and reference architectures. Through continued innovation and optimization, these reference models are available with the fastest performance, in some cases even faster than quantized models.
Together Reference endpoints achieve 4x speedup over the state-of-the-art inference engine vLLM across normal serving regimes:

Further, based on third-party benchmarks from Artificial Analysis, Together Reference endpoints (FP16) perform with over 2x faster tokens per second than Amazon Bedrock, Microsoft Azure, or Octo AI; and over 30% faster than Fireworks FP8 models. This performance comes from a combination of an innovative base engine, more efficient memory management, and a low-overhead system architecture design.
This combination of full reference quality, with high performance, meets the needs of the most demanding enterprises. Together Reference endpoints are ideal for benchmarking, research, and applications demanding the utmost quality.
Together Inference Engine technical advances
The Together inference solution is a dynamic system that continuously incorporates cutting-edge innovations from both the community and our in-house research. These advancements span various areas, which include kernels (e.g., FlashAttention-3 and FlashDecoding), models and architectures (e.g., Mamba and StripedHyena), quality-preserving quantization, speculative decoding (e.g., Medusa, Sequoia, and SpecExec), and other innovative runtime and compiler techniques. To that end, Together Inference Engine builds on these technical advancements to deliver their economic benefits directly to our customers.
Attention Kernels that Power the World of Transformer Models. Designing the fastest kernels that optimize inference for the fastest and most efficient use of hardware is one of our key technical focuses. These include, but are not limited to, matrix multiplication in low precision, mixture-of-experts, and attention decoding. Last week, in collaboration with Colfax, Meta and NVidia, we released FlashAttention-3 to the open source community, achieving up to 75% of an H100 GPU's maximum capabilities. The Together Inference Engine integrates and builds upon kernels from FlashAttention-3 along with proprietary kernels for other operators.
Speculative Decoding. The Together Inference Engine integrates not only our latest research in speculative decoding algorithms, e.g., Medusa, Sequoia, and SpecExec; it also comes with custom-built draft models for speculative decoding. These draft models are trained over a carefully designed data mixture over the RedPajama dataset, an open 30T tokens dataset that enables state-of-the-art LLMs such as XGen (Salesforce), OpenELM (Apple), Arctic (Snowflake), OLMo (AI2). We conduct training of draft models often beyond 10x Chinchilla optimal, which forms a strong foundation for high acceptance draft models that could be readily tailored for each individual customer and specific use cases.
Quality-preserving Quantization. Quality is our core focus at Together, and the Together Inference Engine 2.0 integrates our latest results of quality-preserving quantization. Specifically, we deploy a multi-dimensional accuracy preservation strategy that understands how a small precision loss from quantization can impact the end-to-end system’s speed and accuracy. With quantization techniques based on incoherence processing (from QuIP) that “spreads out” outliers to carefully balance performance and preserve quality at each individual operator level.
Summary and looking forward
As a research-focused company, we will continue to push the envelope of AI acceleration. The Together Inference Engine is built for extensibility and rapid iteration, enabling us to quickly add support for new models, techniques, and kernels. Our most recent research publications like FlashAttention-3 show that there is continued headroom for optimization.
Together Turbo and Together Lite endpoints are available starting today for Llama 3 models, and will be rolling out across other models soon. We are also introducing new pricing for these endpoints, available on our pricing page, and you can access them now at api.together.ai.
Together, we hope these innovations give you the flexibility to scale your applications with the performance, quality, and cost-efficiency your business demands. We can’t wait to see what you build!