
Summary
Zomato needed to provide instant, high-quality support for over a million daily food orders.
By deploying Zia, an AI chatbot built on Together AI’s optimized Llama models and a function-based response and action pipeline, they shifted from transactional menus to conversational, automated service.
The new system doubled CSAT, lowered average response time by 75% to under 10s, and scales smoothly past 1,000 messages per minute at lower cost.
This blog post has been adapted from a talk given by Yuvraj Gagneja, AI Engineer at Zomato AI, at the Fifth Elephant Conference 2024.
Each day, Zomato delivers over a million orders across India, with that number growing rapidly. To meet the challenge of providing efficient customer support at this scale, Zomato went on a journey to revolutionize their customer service using AI. Their goal wasn't just to improve support, but to transform it into a source of delight. In this article, they share how they built an AI-powered support bot that led to 2x improvement in customer satisfaction and 75% reduction in response times. By partnering with Together AI and leveraging their optimized Llama models and scalable infrastructure, Zomato was able to scale this solution to over 1000 messages per minute cost-effectively, while maintaining control over performance.
"Our endeavor is to deliver exceptional customer experience at all times. Together AI has been our long standing partner and with Together Inference Engine 2.0 and Together Turbo models, we have been able to provide high quality, fast, and accurate support that our customers demand at tremendous scale."
— Rinshul Chandra, COO, Food Delivery, Zomato
Pre AI: A transactional support system
Before integrating AI, Zomato's support system faced several challenges:
- Transactional, not conversational: Users had to navigate through a fixed set of options and rigid decision trees.
- Scripted responses: The system lacked flexibility to address unique situations.
- Unnecessary escalations: Even simple queries like "where is my order" were often directed to human agents.
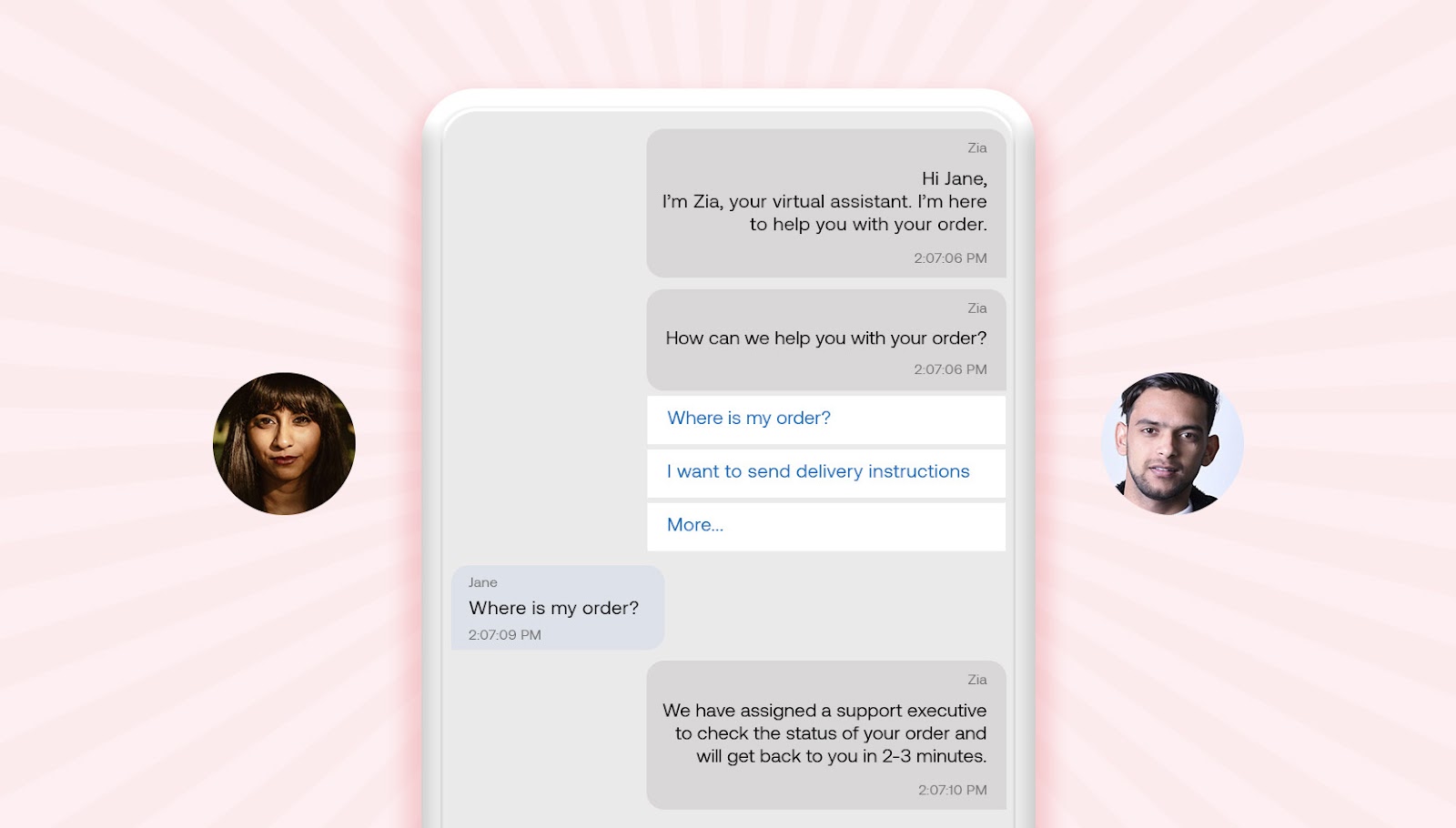
Requirements for the AI-driven solution
Using AI, Zomato wanted to create a chatbot that could provide more natural, human-like interactions.
They identified three key requirements:
- Conversational, not transactional: You should simply be able to type your concern, and the bot handles it smoothly.
- Deep intent understanding: You can express your need in plain language. You shouldn't need to click 3 buttons to say that you want to change your delivery time.
- Action-oriented: The system should smartly manage tasks like adding delivery instructions or canceling orders directly, reducing the need for human intervention and saving customers time.
To measure the success of their new AI-powered bot, they established the following key metrics:
- Chat ratings (Customer Satisfaction Scores): This would directly measure the improvement in customer satisfaction from the previous experience.
- Containment percentage: The percentage of chats the AI bot could handle without human escalation. For example if the containment percentage is 75%, that means that out of a hundred chats, 75 chats were handled by the bot itself 25 were escalated to a human.
- Cost efficiency: Balancing the cost of running the AI against the reduction in human agent involvement.
- Response time: They were aiming for a sub-10 second response time to resolve customer concerns quickly.
Building Zia – their AI-powered support agent

Response generation pipeline
At the core of Zomato's AI support system is a response generator that creates the contextually aware prompt to send to their Large Language Models (LLMs). They developed a function-based approach to efficiently retrieve and incorporate real-time order data.
The system works by:
- Analyzing the conversation to identify required data through function classification (e.g., "where's my order?" triggers retrieval of order status and location)
- Making targeted API calls to fetch only the necessary data via function-calling
- Transforming structured JSON responses into natural language
- Combining this with ongoing chat history and business guidelines in the final prompt
This approach helps them maintain accuracy while minimizing token usage. For example, when a customer asks about delivery timing, they only fetch location and ETA data, not the full order details. They implemented this function-based architecture before native function calling was widely available in LLM APIs, allowing them to build a more efficient and controllable system.
JSON to text conversion
Their APIs often return data in JSON format, which isn't ideal for feeding directly into an LLM. They developed a sophisticated transformation layer that converts JSON API responses into natural language. This not only makes it easier for the LLM to generate human-like responses but also allows them to control the narrative and format of the information presented to the user.

Action decisioning pipeline
Their chatbot combines conversation with action through a two-step verification system. Using multi-class classification, it first identifies potential actions (like modifying delivery locations or canceling orders) based on conversation context. It then verifies if the action should be taken by checking order status and user history.
Their action decisioning pipeline runs in parallel to response generation. When an action is identified, the system pauses response generation and presents the user with a verification popup before executing the action. For example, if a user complains about delivery delays, the system might give the user the option to cancel the order—but only after verification that the order is in fact delayed.
Guardrails and policy layer for business critical actions
While LLMs excel at understanding user intent, they can be overly accommodating to user requests, or hallucinate. For example, when they initially relied solely on LLMs for deciding whether to escalate to a human or not, their containment rates swung dramatically—from 80% to 50% day-to-day—making it difficult to effectively staff their support team.
To stabilize this, they implemented a policy layer that validates LLM decisions against system data. When the LLM suggests an escalation, it must tag it with a predefined reason (e.g., "DP_MOVEMENT_ISSUE" for delivery delays), which their system then verifies against actual order data. This combination of LLM intelligence and systematic verification helps maintain consistent service levels while preventing unnecessary escalations.

Migrating to open-source models with Together AI
Their initial version of Zia was built on closed-source models, but challenges with scaling costs and latency of larger models like GPT-4 pushed them to explore alternatives. The release of Llama 3 marked a turning point in open-source model quality, leading them to partner with Together AI.
The switch to Together AI's optimized Llama models reduced their latency and cut costs compared to GPT-4. Together AI's platform offers high-performance versions of open-source models through simple, OpenAI-compatible APIs and scalable infrastructure – enabling them to migrate seamlessly.
Working with the Together AI platform has enabled:
- Model experimentation: Easy A/B testing and swift deployment of different LLMs, with access to optimized versions of models like Llama—plus the ability to easily fine-tune these models for their specific customer support use cases.
- Flexible scaling: Hybrid deployment combining serverless for baseline traffic with dedicated endpoints for peaks—crucial for their meal-time traffic spikes.
- High performance: Together Turbo versions of open-source models deliver consistent fast speeds, while giving them full control over model configuration and deployment.
Optimizing for Latency, Scalability and Cost Efficiency
Because of their massive scale, they were keenly aware of the need to optimize their system for real-world deployment. Here's how they addressed these critical factors:
Latency
They set a target of sub-10-second response times for their system. To achieve this, they implemented several optimizations:
- Using Together AI's platform, they deployed different-sized models strategically—larger models (70B) for critical tasks like intent detection, and faster models (8B) for chat completion
- Their data filtering system via function classifiers significantly reduces the amount of tokens passed to the LLM, cutting down processing time
- They optimized their prompts to generate concise outputs, as they found that LLM response time scales linearly with the number of output tokens
Scalability
Their system was designed with scalability in mind from the outset. During Mother's Day, one of their busiest days, they successfully handled over 80,000 customers with peak volumes exceeding 1,000 messages per minute.
To achieve this level of scalability, they:
- Leveraged Together AI's hybrid deployment model—using serverless for baseline traffic and dedicated endpoints during their 10-50x meal-time spikes
- Used a mix of LLM sizes to balance between accuracy and throughput, allowing them to scale different components of their system independently based on demand
Cost Efficiency
To keep costs under control while maintaining high performance, they implemented several strategies:
- Their data filtering reduces the number of tokens processed by the LLM, directly translating to lower costs
- Together AI's platform enables them to use smaller models where appropriate, optimizing the performance-cost tradeoff
Results and impact: From transactional to delightful
Overall Zomato were able to see some pretty exciting results with the implementation of their AI-powered support system:
- Customer satisfaction: 2x improvement in Customer Satisfaction (CSAT) scores
- Cost efficiency and response times: AI allows them to handle more requests at a lower cost, with average response times dropping by 75% to under 10 seconds.
- Improved containment rate: More support requests are now fully handled by the AI agent. Shift in containment distribution, focusing on resolving more complex queries automatically
On Mother's Day—a peak day for orders at Zomato—their AI system managed more than 80,000 customers and over 1,000 messages per minute. Not only did the system handle the scale, but it also added a thoughtful touch, reminding customers to add cake to their Mother's Day orders, making the interaction feel personal and delightful.

How they do evaluation
To maintain quality at scale, Zomato implemented a comprehensive evaluation framework that combines human-in-the-loop quality checks with LLM-as-judge grading. Every change to their system undergoes human review, and a percentage of all their responses are sampled for human grading as well.
They track four key evaluation metrics:
- Factual Consistency: Ensures that AI responses align with their backend data.
- Information Relevance: Measures how well responses address specific user queries.
- Guideline Compliance: Verifies adherence to Zomato's business policies.
- Customer Pain Point Resolution: Assesses how effectively issues are resolved.
They've developed their own in-house library for evaluation, pushing these metrics to a centralized dashboard for daily monitoring. They also have a weekly digest on Slack that summarizes chat feedback and areas for improvement across their entire system.
Future developments
As they continue to innovate on their customer experience with AI, they've already started experimenting in a few areas:
- Using multimodal models for post-delivery issues like packaging or spillage
- Augmenting human support with AI for complex scenarios
- Further optimizing LLM selection and integration with continuing experiments with new open-source LLMs
Using AI, Zomato has improved their support metrics, cut costs, and made customer support more delightful. As they explore new ways to enhance their support experience with AI, they remain focused on providing the best possible experience for their users.
This project was made possible through the collaborative efforts of Zomato's AI, engineering, and customer experience teams.


