

A week ago we announced RedPajama, a project to create leading open-source models. We released the first step in the project a training dataset of over 1.2 trillion tokens following the LLaMA recipe. We are thrilled by the excitement and interest in this project. We have received lots of questions about progress in training models based on this dataset. We hope the updates below will help answer some of your questions.
Our goal is to train the LLaMA suite of models and make them available under a permissive open-source license so they can be used as a foundation for research and commercial applications. We expect the RedPajama project will venture beyond LLaMA, but we think LLaMA is a great initial target because LLaMA’s model weights are readily available for comparison, the dataset composition and model architectures are known, and quantitatively, a well trained model provides comparable quality to GPT-3.5 on several standard benchmarks.
Building high-quality large language models is a fairly delicate effort that requires careful planning, systematic benchmarking, and iterative improvements on data, model, and implementation. It is very useful to be able to isolate problems to data, architecture, code and scale. Therefore we are running several experiments in parallel, and building models at multiple scales.
Our goal is to train models following the LLaMA recipe, which consists of two parts — the dataset and the model architecture. To achieve this, we decouple the quantitative evaluation of our progress into several questions and hypotheses. The first question we want to answer, which is the focus of this blog post, is to understand how the RedPajama-Data-1T base dataset, independent of the model architecture, compare to the Pile dataset originally released by EleutherAI in 2020 that has been the leading standard for open pre-training data ever since.
“How does the RedPajama-Data-1T base dataset, independent of the model architecture, compares to the Pile dataset?”
To test this, we conducted a training run with exactly the same model architecture and tokenizer as Pythia-7B, a well-regarded and fully open model from EleutherAI trained on the Pile. If the RedPajama data provides additional value, we should expect RedPajama-Pythia-7B to outperform Pythia-7B (and serve as a useful artifact in its own right). Currently, we are 40% of the way through this experiment, and we can safely say that RedPajama-7B outperforms the Pile with respect to the Pythia-7B architecture.
To measure the quality of model checkpoints, we leveraged the robust Holistic Evaluation of Language Models (HELM)benchmarks from the Stanford Center for Research on Foundation Models. We ran all 16 HELM core scenarios every 80 to 100 billion tokens. We’ve now finished processing 440 billion tokens, and here is what we found. First, at 300 billion tokens, RedPajama-Pythia-7B has comparable quality to Pythia-7B, which was trained with 300 billion tokens on the Pile. At 440 billion tokens, we now have a model checkpoint that is better than Pythia-7B (0.416 HELM vs. 0.400 HELM) and StableLM-7B (0.283 HELM). This is quite promising given that we still have 600 billion tokens to go!
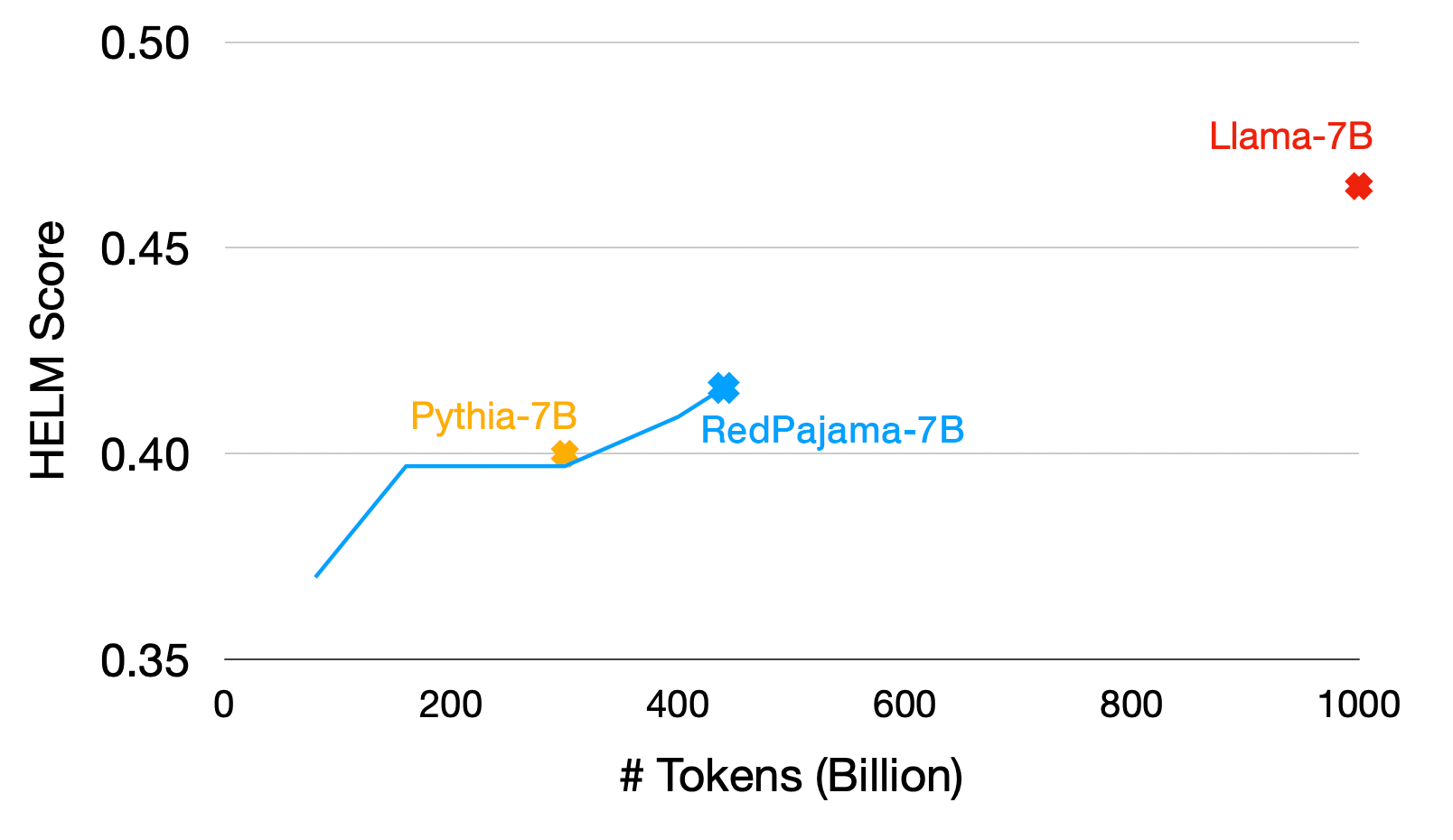
More encouragingly, we see the quality of the model checkpoint is still improving with more tokens. This holds for many HELM scenarios. Note that the fluctuations are because we still have a quite large learning rate at 400 billion tokens and we haven’t converged yet (the learning rate decay schedule is targeting for 1 trillion tokens).

At 440 billion tokens, we are still lagging behind LLaMA-7B, which has a HELM score 0.465. We hope this gap will be closed when we finish the remaining 60% training. In terms of training loss, we are also making progress and the model is still improving.

What’s next? One thing that we’re excited about is to continue to improve the data — we are conducting careful error analysis during training and generating a list of ways we can improve the base dataset. And we are exploring ways to bo beyond 1 trillion tokens by combining with other datasets such as The Pile. We would love to engage the community on this!
The RedPajama 7B model training is running on 3,072 V100 GPUs provided as part of the INCITE project on Scalable Foundation Models for Transferrable Generalist AI, with support from the Oak Ridge Leadership Computing Facility (OLCF) and INCITE program. We are also thankful to all the project team members helping to build the RedPajama dataset and supporting training including Ontocord.ai, ETH DS3Lab, AAI CERC, Université de Montréal, Stanford Center for Research on Foundation Models (CRFM), Stanford Hazy Research research group and LAION. We also appreciate the contributions by EleutherAI and Quentin Anthony for sharing the Pythia-7B model architecture and training code.
Our goal is to work with the open-source AI community to build the best large language models possible. It will take time and effort from the whole community to do this, but we are excited to see what we can achieve together in the weeks, months and years to come. As we identify ways we can improve the base dataset and models we will be creating a task list for members of the community to help with on GitHub. And we would love to hear your suggestions and feedback — join our Discord to chat with the core team.
The three main steps in the RedPajama project were first creating the base dataset, next training the base models and third instruction tuning. While this blog post is focused on the second step — training the RedPajama-7B base model, we are also working in parallel on instruction tuning which should also dramatically improve the quality of the models for chat-like tasks. More details to come on instruction tuning in the coming weeks.
Once we have more robust and safe checkpoints, we plan to have a wider group of participants access and test them on their applications. If you’d be interested in this, please drop us an email at redpajama@together.xyz.
Thank you!