The RedPajama project aims to create a set of leading open-source models and to rigorously understand the ingredients that yield good performance. A few weeks ago we released the RedPajama base dataset based on the LLaMA paper, which has galvanized the open-source community. The 5 terabyte dataset has been downloaded hundreds of times and used to train models like MPT, OpenLLaMA, OpenAlpaca. Today we are excited to release RedPajama-INCITE models, including instruct-tuned and chat versions.
Today’s release includes our first models trained on the RedPajama base dataset: a 3 billion and a 7B parameter base model that aims to replicate the LLaMA recipe as closely as possible. In addition we are releasing fully open-source instruction-tuned and chat models. Our key takeaways:
The 3B model is the strongest in its class, and the small size makes it extremely fast and accessible (it even runs on a RTX 2070 released over 5 years ago).
The instruction-tuned versions of the models achieve strong performance on HELM benchmarks. As expected, on HELM the 7B model performance is higher than the base LLaMA model by 3 points. We recommend using these models for downstream applications with few-shot, entity extraction, classification, or summarization tasks.
The 7B model (which is 80% done training) is already outperforming the Pythia 7B model, which is showing the importance of a bigger dataset and the value of the RedPajama base dataset.
Based on our observations, we see a clear path for creating a better version of the RedPajama dataset, which we will release in the coming weeks, that will go beyond the quality of LLaMA 7B. We plan to build models at larger scale with this new dataset.
We expect differences between the LLaMA 7B and our replication, which we have investigated below.
The biggest takeaway is the demonstration that performant LLMs can be built quickly by the open-source community. This work builds on top of our 1.2 trillion token RedPajama dataset, EleutherAI’s Pythia training code, FlashAttention from Stanford and Together, the HELM benchmarks from Stanford CRFM and generous support from EleutherAI & LAION for compute time on the Summit supercomputer within the INCITE program award "Scalable Foundation Models for Transferable Generalist AI”. We believe these kind of open collaborations, at larger scales, will be behind the best AI systems of the future.
“RedPajama 3B model is the strongest model in it’s class and brings a performant large language model to a wide variety of hardware.”
Today’s release includes the following models, all released under the permissive Apache 2.0 license allowing for use both in research and commercial applications.
Model designed for few-shot prompts, fine-tuned using the same formula as GPT-JT (but eliminate all datasets that overlap with the HELM benchmark) over the RedPajama-INCITE-Base-3B-v1 base model.
Early preview of our RedPajama 7B part way through training having completed 800 billion out of the planned 1 trillion tokens, as quality continues to improve in training.
Early preview of model designed for few-shot prompts trained on RedPajama-INCITE-Base-7B-preview.
In only a few weeks the support, suggestions, and feedback for RedPajama from the open-source community has been incredible. Based on our learnings, we are also already starting the next version of the RedPajama base dataset which will be nearly twice the size of the original v1 dataset. Thank you for your support, feedback and suggestions!
View fullsize3B model has stabilized at 800 billion tokens and the 7B model continues to improve as it completes training to 1 trillion tokens
During RedPajama model training we have shared regular updates, and both the 3B and 7B models have now been trained on 800 billion tokens. We are excited to see that the 3B model has stabilized at 800 billion tokens and the 7B model continues to improve as it completes training to 1 trillion tokens.
3B RedPajama Models
RedPajama-INCITE-Base-3B-v1 is trained over the RedPajama v1 dataset, with the same architecture as the popular Pythia model suite. We chose to start with the Pythia architecture to understand the value of training with the much larger RedPajama dataset with respect to the current leading open-source dataset, the Pile. Training on Summit leveraged the DeeperSpeed codebase developed by EleutherAI.
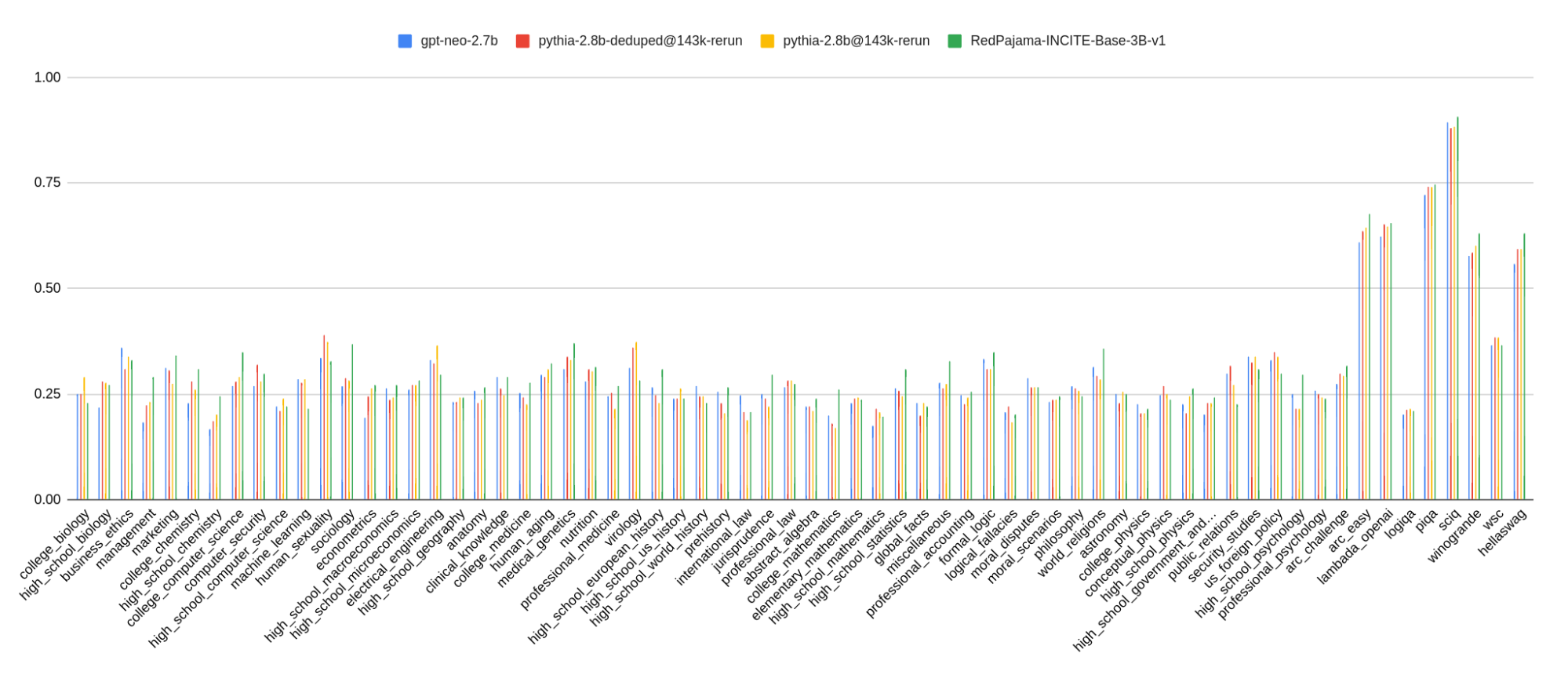
We are excited to see that at 800B tokens, RedPajama-Base-INCITE-3B has better few-shot performance (measured in HELM, as the average score over 16 core scenarios) and better zero-shot performance (measured in Eleuther’s LM evaluation harness) compared with open models of similar size, including the well-regarded GPT-Neo and Pythia-2.8B (trained with 420B and 300B tokens, respectively, with the Pile). On HELM, it outperforms these models by 3-5 points. On a subset of tasks from lm-evaluation-harness, outperforms these open models by 2-7 points.
Additionally, we are excited to release an instruction-tuned version of this 3B model, RedPajama-INCITE-Instruct-3B-v1, trained following Together’s GPT-JT recipe and removing any data in HELM benchmarks to ensure that there is no contamination with respect to HELM. This model shows excellent performance on few-shot tasks, even approaching the quality of LLaMA 7B in a much smaller model, as shown in the results below:
(Zero Shot) Results on a subset of lm-evaluation-harness, following LLM Worksheet’s selection of tasks & metrics. We didn’t run coqa because of an error as in this issue.
Lambada_openai (acc)
Hellaswag (acc_norm)
Winogrande (acc)
Piqa(acc)
average
GPT-Neo
0.6223
0.5579
0.5769
0.7219
0.6197
Pythia-2.8B
0.6466
0.5933
0.6006
0.7399
0.6451
Pythia-2.8B-dedup
0.6524
0.5941
0.5848
0.7404
0.6429
RedPajama-INCITE-Base-3B-v1
0.6541
0.6317
0.6322
0.7470
0.6662
Results on a subset of lm-evaluation-harness, tasks selected from what used to evaluate Pythia and GPT-J.
View fullsizeRedPajama 3B results on a subset of lm-evaluation-harness
Evaluating chat models is a challenging task, and we are in the process of conducting more quantitative evaluation based on human and community feedback, and are excited to share these results soon! Nevertheless, here are some examples comparing the behavior of different chat models. We see that in many examples, RedPajama-INCITE-Chat-3B-v1 has similar quality as Open Assistant as reported in the their paper.
RedPajama 3B chat model responses on example queries from the Open Assistant paper.
RedPajama-INCITE-Chat-3B-v1 (oasst1 + Dolly 2.0)
Pythia-2.8B + oasst1 + Dolly 2.0
Open Assistant (“pythia-12b-deduped fine-tuned on the OpenAssistant and Alpaca data” [Appendix E of https://arxiv.org/abs/2304.07327])
Imagine a world in which time travel has become possible. It would open up a whole new world of possibilities, including the ability to change the past, present, and future. This could have significant implications for our understanding of history, science, and the universe itself. Time travel has always been a fascinating concept, and the idea of being able to change the past, present, and future would be an incredible opportunity. However, it would also present many ethical and philosophical questions that would need to be addressed. One of the biggest concerns would be the impact that time travel would have on the laws of physics and causality. If we were able to travel back in time and change events, it could potentially create paradoxes and open up new possibilities for time travel. However, it would also mean that the future we have now is no longer guaranteed, and our actions and decisions could have long-lasting consequences. Another concern would be the potential impact on human history. If we were able to change the past, present, and future, it could potentially lead to new discoveries, inventions, and breakthroughs that would have significant impacts on our society and culture. However, it could also mean that we are no longer living in the same world that we know today, and that our understanding of history and the universe could be fundamentally altered. Another ethical concern would be the impact that time travel would have on the concept of free will. If we were able to change the past, present, and future, it could potentially lead to situations where we are no longer responsible for our actions and decisions. This could have significant implications for our sense of agency and autonomy, and could lead to a loss of personal responsibility and accountability. Finally, there would also be the question of what to do with the knowledge that we have access to time travel. If we were able to change the past, present, and future, it would mean that we have access to a vast amount of information and knowledge that we have never had before. This could lead to new discoveries and innovations, but it also could lead to a loss of privacy and a potential breakdown of the current social order.
In conclusion, time travel would be a complex and multifaceted issue that would require careful consideration of its ethical, philosophical, and societal implications. It would also require a deep understanding of the laws of physics and causality to ensure that it does not create paradoxes or open up new possibilities for time travel.
Imagine a world in which time travel has become possible. It would open up a whole new world of possibilities, including the ability to change the past, present, and future. This could have significant implications for our understanding of history, science, and the universe itself. In a world where time travel is possible, it opens up a whole new world of possibilities. One of the most significant implications would be the ability to change the past, present, and future. This could have significant implications for our understanding of history, science, and the universe itself. For example, if someone could travel back in time and prevent a certain event from occurring, then they could change the course of history and create a new reality. This could potentially lead to a world where different outcomes occur, and this could have significant implications for the way we understand history and the nature of reality.
Imagine a world in which time travel has become possible. It would open up a whole new world of possibilities, including the ability to change the past, present, and future. This could have significant implications for our understanding of history, science, and the universe itself. The potential consequences of having access to time travel are vast and far-reaching. One concern is that it could lead to unintended consequences for future generations if we alter events or change history without careful consideration. Additionally, there may be legal issues regarding ownership and rights over changes made through time travel. The ethical considerations would involve weighing the risks and benefits, as well as making sure that any changes made do not cause harm to anyone involved. Finally, it will also be important to ensure that time travelers adhere to all relevant laws and regulations when using their powers.
Why is Shakespeare such a renowned writer that is still studied so heavily today? Shakespeare is still studied so heavily today because of his mastery of the English language. His use of language is so beautiful and intricate that it has inspired many modern writers. His plays are still performed today, and many of his poems and sonnets are still read and enjoyed. His plays have been adapted for film and television, and his characters continue to be studied and analyzed by scholars and students.
Why is Shakespeare such a renowned writer that is still studied so heavily today? Shakespeare's plays are so well known because they are thought to be timeless and universal. Shakespeare's characters are relatable and his stories are thought to be universal in nature. Shakespeare is also known for his complex and nuanced writing style that is thought to be hard to imitate. Shakespeare's plays are still studied and performed to this day because of their great depth and complexity. Shakespeare's plays are often thought to be about the human condition and how we deal with the pressures of life.
Why is Shakespeare such a renowned writer that is still studied so heavily today? Shakespeare is one of the most influential writers in history, and his work continues to be studied and performed around the world. His plays are known for their powerful language, memorable characters, and timeless themes, which have made him a popular choice among playwrights, actors, and audiences alike. In addition to his literary merit, Shakespeare’s works also helped shape the English language and influenced many other authors who followed in his footsteps. Many of his lines continue to be quoted and used as examples of excellent writing. He remains an important figure in literature and culture, and his legacy will likely endure for generations to come.
What is the process of creating a successful YouTube channel, from developing a niche and creating content to building a community and monetizing the channel? Creating a successful YouTube channel requires a lot of hard work, dedication, and creativity. Here are some steps to help you develop a successful channel: 1. Develop a niche: Choose a topic or subject that you are passionate about and that you can consistently provide valuable and unique content on. This will help you build an engaged audience and establish yourself as an expert in your field. 2. Create high-quality content: Invest in high-quality equipment, editing software, and other resources to create high-quality videos that are engaging and informative. Make sure to use professional lighting and sound equipment to create a polished and professional look. 3. Build a community: Create a community around your channel by engaging with your audience and responding to their comments and feedback. This will help you build a loyal following and create a sense of community around your channel. 4. Monetize your channel: Consider monetizing your channel through ads, affiliate marketing, or other revenue-generating strategies. This will help you sustain your channel and create a sustainable income. 5. Promote your channel: Promote your channel through social media, email marketing, and other platforms to build your audience and drive traffic to your videos. 6. Grow your channel: Continuously produce high-quality content and engage with your audience to grow your channel and build a loyal following. 7. Monitor analytics: Use analytics tools to monitor your channel's performance and identify areas for improvement. This will help you make data-driven decisions and continuously improve your channel. 8. Continuously learn and grow: Continuously learn and grow in your field of expertise to stay relevant and provide valuable content to your audience. By following these steps, you can develop a successful YouTube channel that can generate income and build a community around your content.
What is the process of creating a successful YouTube channel, from developing a niche and creating content to building a community and monetizing the channel? To create a successful YouTube channel, it's important to have a niche and a clear focus. This will help you develop content that is specific to your audience and helps you build a community. Once you have a strong niche and a following, you can start monetizing your channel by creating ads, merchandise, and sponsorships. This will help you earn money from your videos and support your channel.
What is the process of creating a successful YouTube channel, from developing a niche and creating content to building a community and monetizing the channel? Creating a successful YouTube channel involves several steps. First, you need to select a niche that aligns with your target audience’s interests and passions. Once you have chosen a niche, it is important to create engaging content that resonates with your viewers. This can include videos on topics such as tutorials, reviews, vlogs, and more. To build a strong community around your channel, it is essential to engage with your subscribers by responding to comments, posting regular updates, and sharing relevant information. You should also use other social media platforms like Twitter and Facebook to promote your channel and interact with potential audiences. Finally, to make money off your channel, you will need to optimize your video titles, descriptions, tags, and thumbnails for search engine visibility, set up ads, and generate revenue through sponsorships or product integrations. Additionally, you may want to consider using YouTube analytics to track your channel’s performance and adjust strategies accordingly.
And, following are some additional examples comparing RedPajama 3B to the Pythia 2.8B model tuned on OASST1 and Dolly v2.0 datasets.
RedPajama-INCITE-Chat-3B-v1 (oasst1 + Dolly 2.0)
Pythia-2.8B + oasst1 + Dolly 2.0
Write an email to my friends inviting them to come to my home on Friday for a dinner party, bring their own food to share. Hi everyone, I'm excited to host a dinner party on Friday, and I hope you can join me! We'll be having a casual dinner with a twist, where we'll each bring a dish to share. I've made some appetizers, salads, and desserts, but I'm also excited to try some new dishes. I've got a big backyard, so we can all sit outside and enjoy the fresh air. I've got plenty of seating, and we can even set up a few tables in the living room if we have too many people. I hope you can join us, and I look forward to cooking and eating with you!
Write an email to my friends inviting them to come to my home on Friday for a dinner party, bring their own food to share. Dear {Friend}, I hope you had a great summer and are looking forward to a fun fall. I'm so excited to share some of my favorite things with you on Friday. I hope you can join us for a delicious dinner and a great conversation. I'm looking forward to seeing you there. Best, {Your Name}
Create a list of things to do in San Francisco San Francisco is a beautiful city with plenty of things to do. Here are some of the top things to do in San Francisco: 1. Visit Golden Gate Park: Golden Gate Park is the largest park in San Francisco and is home to the iconic Golden Gate Bridge, Japanese Tea Garden, and the San Francisco Botanical Garden. 2. Take a ferry ride to Alcatraz: Take a ferry ride to Alcatraz, a former federal prison that is now a popular tourist destination. 3. Visit the Golden Gate Bridge: The iconic Golden Gate Bridge is one of the most famous landmarks in San Francisco. Take a walk across the bridge for incredible views of the city and the bay. 4. Visit Chinatown: San Francisco's Chinatown is a vibrant neighborhood with traditional Chinese markets, restaurants, and temples. 5. Visit the Castro District: The Castro District is the heart of the LGBTQ+ community in San Francisco and is home to many bars, restaurants, and shops. 6. Take a cable car ride: Take a ride on the iconic cable cars, which have been operating in San Francisco since the late 19th century. 7. Visit the Palace of Fine Arts: The Palace of Fine Arts is a historic building in San Francisco's Marina District and is a popular spot for wedding ceremonies and photo shoots. 8. Visit the San Francisco Museum of Modern Art: The San Francisco Museum of Modern Art is one of the largest museums of modern and contemporary art in the United States. 9. Visit the San Francisco Zoo: The San Francisco Zoo is a popular destination for families and is home to a variety of animals, including lions, tigers, and gorillas. 10. Take a stroll along the waterfront: The waterfront in San Francisco is a great place to take a stroll