
RAG fine-tuning combines code retrieval with model training, addressing the limitations of outdated knowledge and hallucinations in LLMs. Our experiments with fine-tuning Mistral 7B Instruct v0.2 on Together AI Platform show that RAG fine-tuned models achieve up to 16% better accuracy than Claude 3 Opus, while offering 3.7x faster speed and an astounding 150x cost reduction. Compared to GPT-4o, the models achieve up to 19% quality improvement, 1.1x faster speed at 37.5x cost reduction.
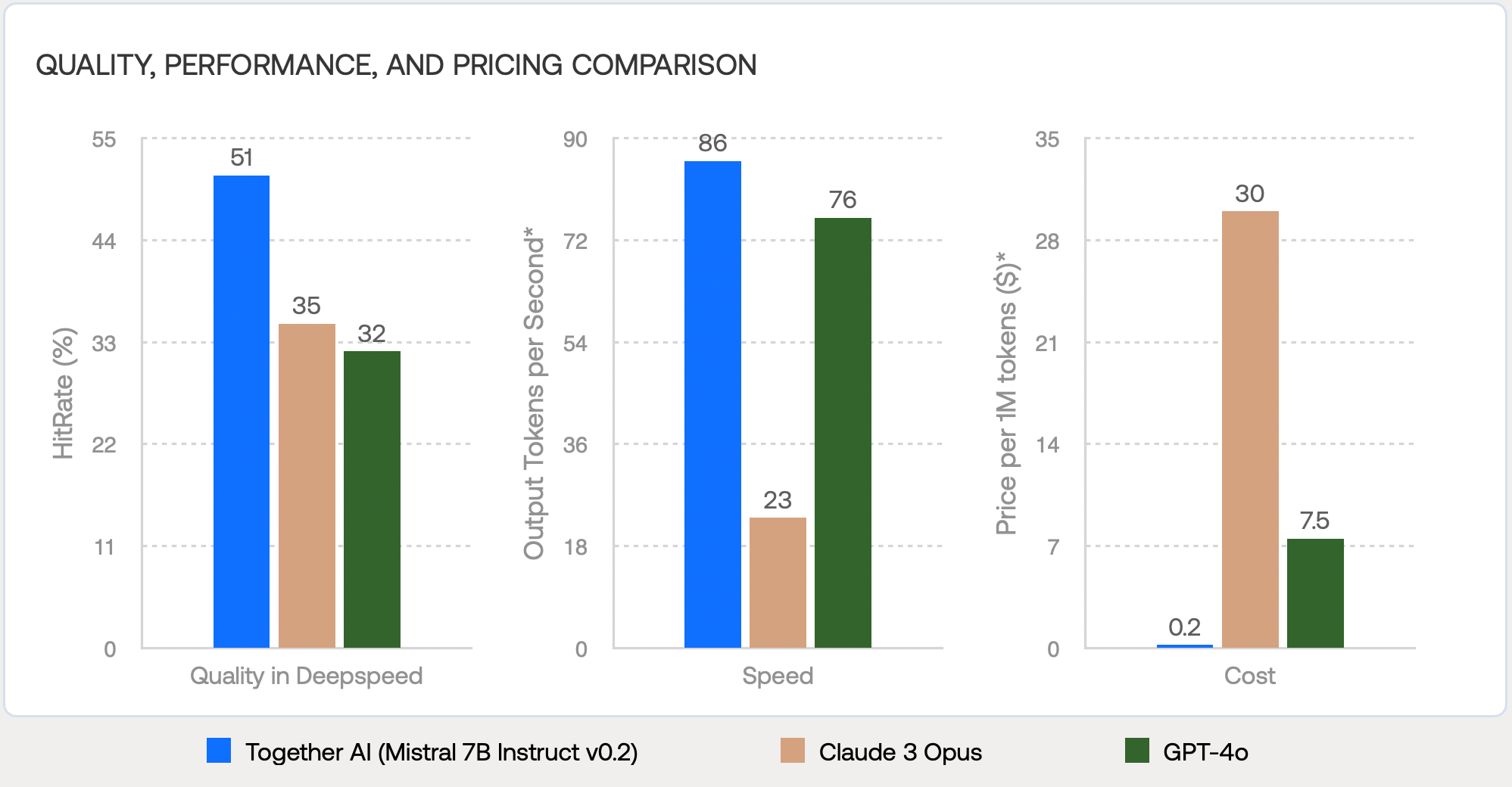
*The data presented in this graph was sourced from Artificial Analysis for serverless models.
Overview
Large Language Models (LLMs) have shown promising capabilities on multiple applications such as code generation, task planning, and document understanding. Despite the impressive performance, these models often fall short due to two main reasons: hallucinations and outdated knowledge in the models. For example, LLMs are limited on generating code referencing specific codebases as it requires up-to-date code and accurate code structures [1,2,3].
Retrieval-Augmented Generation (RAG) is a technique designed to address such limitations in language model capabilities by integrating retrieval methods into the text generation process. This approach involves two key phases: indexing and querying. In the indexing phase, which is typically conducted offline, external knowledge sources—such as internal documents—are divided into chunks. These chunks are then transformed into vectors using an embedding model then stored in a vector database. During the querying phase, relevant information is retrieved from this database and combined with the initial query in a specific format. This enriched input is then used by a generation model to produce the final output.
The success of RAG critically depends on the effectiveness of the indexing, retrieval, and generation processes using the retrieved context. To enhance the indexing and retrieval stages, we partnered with Morph Labs, leveraging their advanced technologies in codebase search and synthetic data generation. For the generation portion, it was vital to ensure that the system could accurately utilize the retrieved context. Thus, we fine-tuned Mistral 7B Instruct v0.2 using Together's Fine-tuning API to ensure the model's responses are up-to-date by incorporating the latest coding standards and practices. The results of this fine-tuning have been remarkable, showing significant enhancements in the model's performance. Many instances of our fine-tuned models have demonstrated at par or better capabilities than GPT-4o and Claude 3 Opus in popular AI open source codebases.
The Challenge of Code Generation with LLMs
When using LLMs to generate codes, they have two primary issues:
- Hallucination: Existing LLMs are trained on large amounts of data to improve the generalization. However, with large-scaled data, LLMs may also learn a lot of noisy information with inaccurate knowledge or alignment. Also, with more generalized capabilities, LLMs might sacrifice their domain-specific knowledge, such as knowledge on specific codebases. These noisy training data and over generalization cause the LLMs to generate plausible but incorrect codes based on users queries.
- Outdated Information: As codebases evolve, the static knowledge of an LLM becomes less relevant, leading to recommendations that may not comply with the latest programming practices or library updates.

Online repository-level fine-tuning with retrieval
RAG is a popular technique to address these limitations, but existing open-sourced models are limited to utilize the retrieved information in the prompt with domain-specific knowledge or format. To improve the RAG performance, we studied the RAG fine-tuning method and applied it to code generation tasks. Unlike standard fine-tuning, this approach first retrieves relevant code snippets from a code repository based on each query. Then, the snippets serve as contextual grounding during the model's training phase, ensuring that generated code is not only accurate but also contextually appropriate based on up-to-date codebases. Figure 2 shows the overall framework for the RAG fine-tuning on code generation.
Data Morph Labs generated synthetic datasets for training and evaluation where each sample contains a natural-language question and the correct answer. For each question, a set of code snippets retrieved via the Morph Code API are used as the RAG context and concatenated with the question-answer pairs. This allows the model to learn how to utilize real-time knowledge given in the query rather than relying on pre-existing data. The below example shows a sample for vLLM:
Context:
path: vllm/model_executor/layers/quantization/awq.py
name: AWQConfig.get_linear_method
def get_linear_method(self) -> "AWQLinearMethod":
return AWQLinearMethod(self)
path: vllm/model_executor/layers/quantization/awq.py
name: AWQLinearMethod.__init__
def __init__(self, quant_config: AWQConfig):
self.quant_config = quant_config
…
Question:
"How are MergedColumnParallelLinear and BaiChuanMLP related?"
Answer:
"MergedColumnParallelLinear is a class in the vllm library that implements a linear layer with column parallelism, where the weight matrix is concatenated along the output dimension. This class is used in the BaiChuanMLP class, which is a multi-layer perceptron (MLP) model in the vllm library. Specifically, MergedColumnParallelLinear is used in the initialization of the gate_up_proj layer of the BaiChuanMLP. The gate_up_proj layer is a linear layer that takes the hidden state as input and projects it to a larger intermediate space using the MergedColumnParallelLinear class. This allows for efficient computation of the MLP model on multiple GPUs using column parallelism."
In this study, we conducted experiments on five different codebases – Axolotl, Deepspeed, vLLM, Mapbox, WandB. These codebases offer comprehensive coverage of commonly used machine learning codebases spanning training, inference and interface. Although they are widely used by ML researchers, engineers, and practitioners, many existing LLMs show limited understanding of these codebases due to their complexity and rapidly evolving nature. Table 1 shows the number of training tokens per each codebase.
| Codebase | Number of samples per epoch | Number of tokens per epoch |
|---|---|---|
| Axolotl | 2,009 | 18,455,787 |
| Deepspeed | 20918 | 144,858,207 |
| vLLM | 5427 | 49,619,464 |
| Mapbox | 4,844 | 35,898,031 |
| WandB | 54,116 | 416,880,680 |
Fine-tuning To create a personalized code assistant, we fine-tuned a language generation model for each codebase on Together Fine-tuning API, using the next token prediction. In our experiment, we used the Mistral 7B Instruct v0.2 as a base model and with 4 epochs, batch size 12, and learning rate 4e-6.
Inference During the live query handling, the model performs an online retrieval via the Morph Code API to fetch the most relevant and recent code snippets for each query before generating the response.
Results
To evaluate the performance of generated examples, we used the HitRate (%) as the evaluation metric. For each query, we check whether a key identifier string is in the generated code. The identifier string is labeled by human annotators and if the generated code contains the identifier string, it indicates that the model has good understanding and reasoning capability for the codebase. We compared the RAG fine-tuned Mistral 7B Instruct v0.2 to 3 other models – Mistral 7B Instruct v0.2 (not fine-tuned), Claude 3 Opus, and GPT-4o. All of them are evaluated in the RAG setting (denoted as "RAG with" in Figure 3) where the retrieved context from the Morph Code API is incorporated in the query. Additionally, we evaluated GPT-4o without the retrieved context (i.e. "Closed-book").
Figure 3 shows that RAG fine-tuning achieves significant performance improvements of the original model on 4 out of 5 codebases under the RAG setting. The RAG fine-tuned models with 7 billion parameters even achieve at par or better performance compared to much larger models like GPT-4o and Claude 3 Opus except on WandB. Furthermore, beyond their benefits in quality, when you build and deploy the RAG fine-tuned models in the Together platform, they also offer significant economic advantages, up to 150x cheaper, while it's 3.7x faster during inference. Additionally, GPT-4o shows substantially lower accuracy in the closed-book setting which demonstrates that such models can often hallucinate classes and methods when the codebases are updated.

Conclusion
Our study on code-generation RAG fine-tuning provides a promising path for improved AI code assistants with repository-level context and fine-tuning an open source LLM. By leveraging the Together API and the Morph Code API, we can greatly improve the accuracy and applicability of LLM-generated code, making these models more practical and valuable tools in the hands of developers.
Generated Examples
User:
Modify the graph capture functionality of `DeepSpeedAccelerator` to support dynamic graph recompilation during runtime.
Answer:
To modify the graph capture functionality of `DeepSpeedAccelerator` to support dynamic graph recompilation during runtime, you can follow these steps:
1. Create a new class `DynamicGraph` that inherits from `torch.autograd.Function`. This class will be responsible for creating and managing the dynamic graphs.
```python
class DynamicGraph(torch.autograd.Function):
@staticmethod
def forward(ctx, *inputs):
# Capture the input tensors and create a new graph
# Set the `_captured` attribute of the input tensors to True
# Return the input tensors
pass
@staticmethod
def backward(ctx, *grads):
# Release the captured graph and reset the _captured attribute of the input tensors
# Return the gradients
pass
```
2. Modify the `capture_to_graph` method of `DeepSpeedAccelerator` to use the `DynamicGraph` class.
```python
def capture_to_graph(self, graph, pool=None, stream=None):
from deepspeed.runtime.utils import noop_context
if self.graph_capture_enabled:
# Create a new dynamic graph
graph = DynamicGraph.apply
return noop_context()
```
3. Modify the `DynamicGraph` class to support dynamic graph recompilation during runtime.
```python
class DynamicGraph(torch.autograd.Function):
# ...
@staticmethod
def recompile(new_inputs):
# Release the current graph and capture a new graph with the new inputs
pass
```
4. Modify the `DeepSpeedAccelerator` class to use the `recompile` method of the `DynamicGraph` class.
```python
def capture_to_graph(self, graph, pool=None, stream=None):
from deepspeed.runtime.utils import noop_context
if self.graph_capture_enabled:
# Release the current graph and capture a new graph with the new inputs
graph = DynamicGraph.recompile(new_inputs)
return noop_context()
```
5. Modify the `DynamicGraph` class to support the `backward` pass.
```python
class DynamicGraph(torch.autograd.Function):
# ...
@staticmethod
def backward(ctx, *grads):
# Release the captured graph and reset the _captured attribute of the input tensors
# Return the gradients
pass
```
6. Modify the `DeepSpeedAccelerator` class to support the `backward` pass with dynamic graphs.
```python
def backward(ctx, *grads):
# Release the current graph and capture a new graph with the new inputs
graph = DynamicGraph.apply(*grads)
# Compute the gradients using the new graph
# Release the new graph and reset the _captured attribute of the input tensors
return grads
```
By following these steps, you can modify the graph capture functionality of `DeepSpeedAccelerator` to support dynamic graph recompilation during runtime.
Reference
[1] Exploring and Evaluating Hallucinations in LLM-Powered Code Generation. Liu, F; Liu, Y; Shi, L; Huang, H; Wang, R; Yang, Z; and Zhang, L. arXiv:2404.00971
[2] Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. Liu, J; Xia, C; Wang, Y; and Zhang, L. arXiv:2305.01210
[3] Can ChatGPT replace StackOverflow? A Study on Robustness and Reliability of Large Language Model Code Generation. Zhong, L; and Wang, Z. arXiv:2308.10335.