
At Together we are working to bring the world’s computation together in form of a decentralized cloud, to enable researchers and practitioners to leverage and improve artificial intelligence. The key bottleneck is network bandwidth due to the high volume of communication between GPUs during training. At NeurIPS 2022, we will present two papers focusing on addressing these challenges of decentralized training.
When the network bandwidth is 100x slower than data center networks, how can we train foundation models at scale?
Both papers focus on optimizing the efficiency of decentralized training over such slow networks. The first focuses on scheduling while the second focuses on communication compression (for communicating forward activations and backward gradients):
- Decentralized Training of Foundation Models in Heterogeneous Environments (Oral, ~1.8% submissions this year)
Binhang Yuan*, Yongjun He*, Jared Quincy Davis, Tianyi Zhang, Tri Dao, Beidi Chen, Percy Liang, Christopher Re, Ce Zhang
View publication ↗ - Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees
Jue Wang*, Binhang Yuan*, Luka Rimanic*, Yongjun He, Tri Dao, Beidi Chen, Christopher Re, Ce Zhang
View publication ↗
If you are at NeurIPS please drop by! We would love to hear your thoughts on these findings!
- November 29, 11:00 AM-1:00 PM (CST): Poster Session for Fine-tuning Language Models over Slow Networks using Activation Quantization with Guarantees
- November 30, 11:00 AM-1:00 PM (CST): Poster Session for Decentralized Training of Foundation Models in Heterogeneous Environments
- December 3, 11:30 AM-12:00 PM (CST): Our co-founder Percy Liang talks at the Workshop of Decentralization and Trustworthy Machine Learning in Web3.
- December 7, 7:45 PM-8:00 PM (CST): Virtual Panel for Oral Papers for Decentralized Training of Foundation Models in Heterogeneous Environments
In part 1 of this 2-part blog post, we dive into the details of the first paper: Decentralized Training of Foundation Models in Heterogeneous Environments
The challenge and opportunity of decentralized training
Foundation models such as GPT-3, BLOOM, and GLM are computationally expensive to train. For example, a single GPT-3 (175B) training run takes 3.6K PetaFLOPS-days [1] — this easily amounts to $4.6M on today's AWS on-demand instances [2], even assuming 50% device utilization (V100 GPUs peak at 125 TeraFLOPS)! While the cost of training these models is expensive partly due to the difficulty to access GPUs in a centralized data center, there are plenty of computational resources scattered around the world. Jon Peddie Research reports that the PC and AIB GPU market shipped 101 million units in Q4 2021 alone [3]. Moreover, the incremental electricity and HVAC costs of running a V100 GPU (or GPUs with similar TFlops) for a personally owned GPU can be 50-100✕ lower than the spot prices for an equivalent device on the cloud [4].
If we could make use of these devices in a decentralized, open, collaborative paradigm for foundation model training, this could significantly bring down the cost. The inspirational Folding@Home project sourced upwards of 40K NVIDIA and AMD GPUs from volunteer devices to run protein simulations. There are also awesome efforts such as Learning@Home, DeDLOC, PETALS, and SWARM that already start to bring a decentralized paradigm of learning to practice. But when it comes to large-scale foundation models and heterogeneous, slow networks, is it possible? We are excited to share some promising results.

Modeling the decentralized training computation
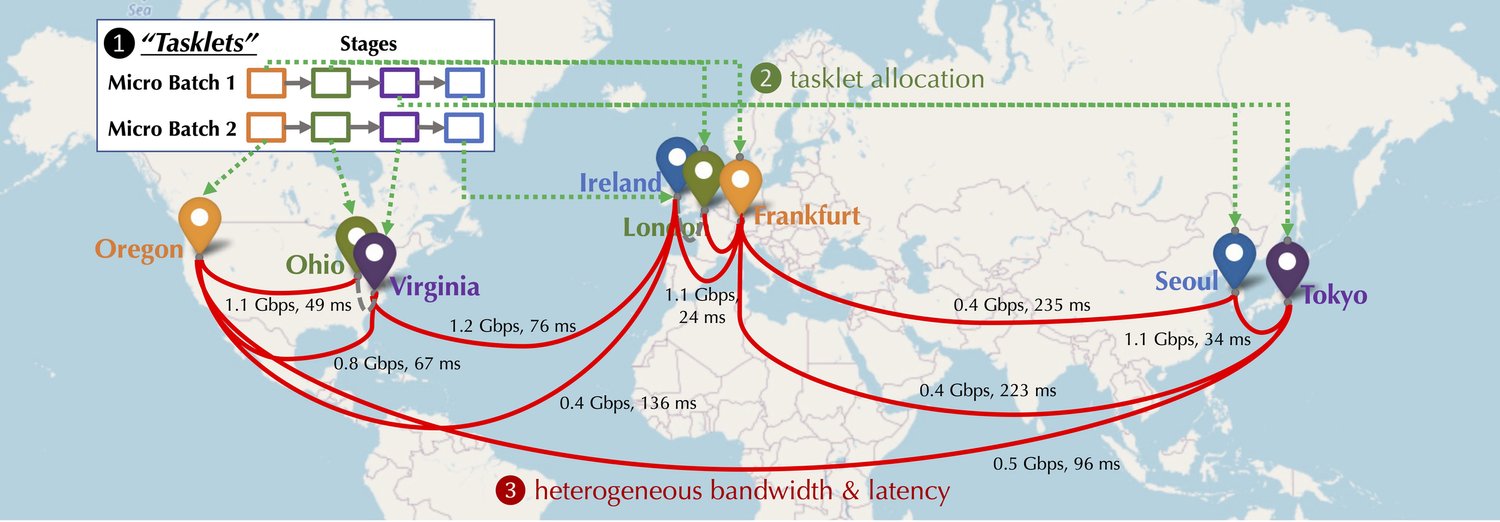
Let’s consider a group of devices (GPUs) participating in decentralized training of a foundation model. Each pair of devices has a connection with potentially different delay latency and bandwidth. These devices can be geo-distributed, as illustrated in Figure 2, with vastly different pairwise communication bandwidth and latency. We consider two forms of parallelism, pipeline parallelism and data parallelism, corresponding to the three types of communication that are illustrated in Figure 1:
- In pipeline parallelism, all layers of a model are split into multiple stages, where each device handles a single stage, which is a consecutive sequence of layers, e.g., several Transformer blocks; in the forward pass, the activations are communicated to the next stage, while in the backward pass, the gradient of the activations is transferred to the previous stage.
- In data parallelism, devices compute the gradient for different micro-batches independently but need to synchronize these gradients through communication.
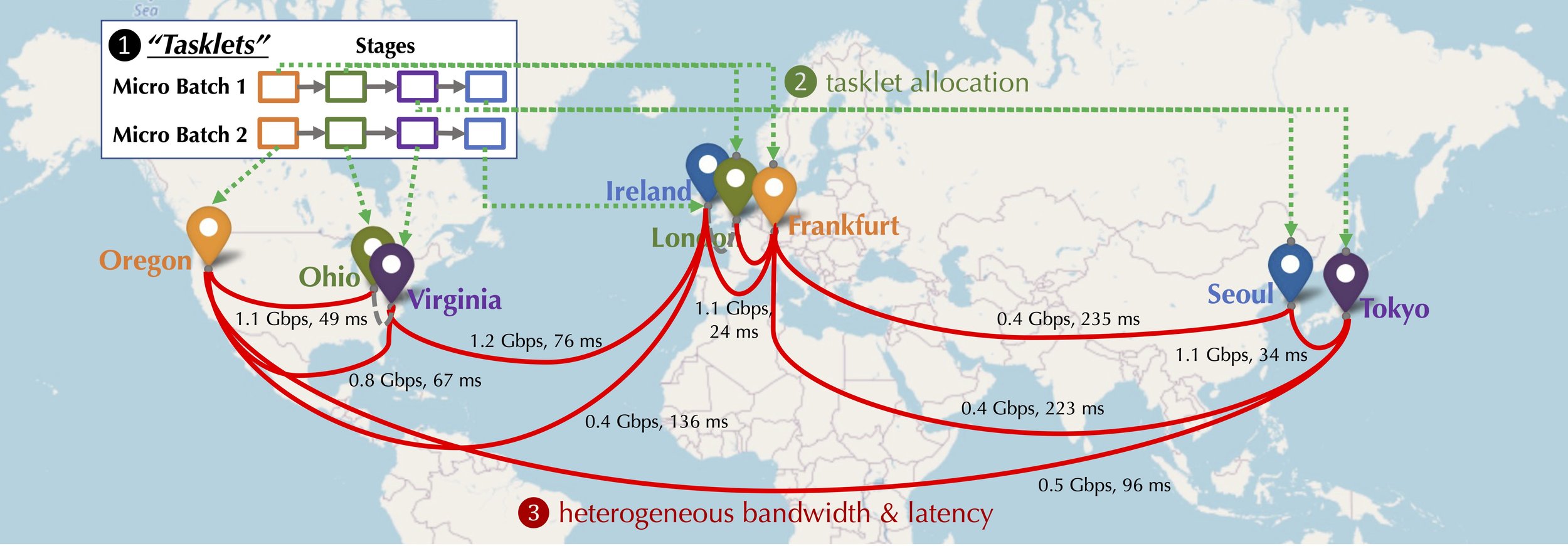
These two types of parallelism combined lead to a set of computation tasks. Formally, we define a tasklet \(t_{i,j}\) as the forward and backward computation for a particular stage \(j\) with a micro-batch \(i\) of training data in a training iteration. Given the heterogeneity of the underlying network (e.g., Oregon ↔ Ohio can be much faster than Frankfurt ↔ Seoul), one important problem in decentralized training is to assign tasklets to devices as to maximize the training throughput.
Scheduling in heterogeneous environments
In a decentralized environment, the training procedure is often communication-bounded. Intuitively, a scheduling algorithm would allocate tasklets that require heavy communication between them to devices with faster connections. This is challenging when the network is heterogeneous — we need to take a global view on such an optimization problem given the dependencies between tasklets and the heterogeneity of the network.
In this work, we take a principled view and start by modeling the cost of a specific scheduling strategy. To capture the complex communication cost for training foundation models, we propose a natural, but novel, formulation that decomposes the cost model into two levels:
- The first level is a balanced graph partitioning problem corresponding to the communication cost of data parallelism.
- The second level is a joint graph matching and traveling salesman problem corresponding to the communication cost of pipeline parallelism.
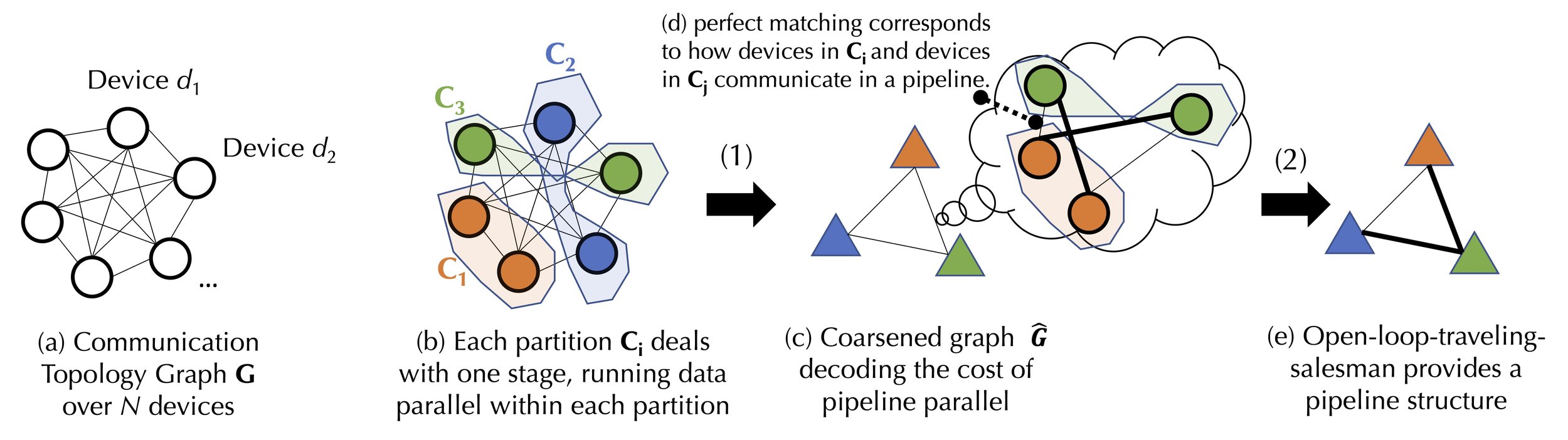
Figure 3 illustrates this procedure. More formally, given a communication graph \(G\) over a set of \(N\) devices \(D={d_1…d_N}\), we use \(\mathbf{A} \in \mathbb{R}_+^{N\times N}\) and \(\mathbf{B} \in \mathbb{R}_+^{N\times N}\) to represent the communication matrix between these devices describing the delay and bandwidth respectively, where the delay and bandwidth between device \(d\) and \(d'\) is \(\alpha_{d,d'} = \mathbf{A}[d, d']\) and \(\beta_{d,d'} = \mathbf{B}[d, d']\). The communication volumes for pipeline parallelism and data parallelism are noted as \(c_{pp}\) and \(c_{dp}\).
We first generate a balanced graph partition corresponding to \(D_{PP}\) number of data parallel groups \(\mathbf{C}_1 ... \mathbf{C}_{D_{PP}}\), where each partition deals with the same pipeline stage that needs to run gradient synchronization for data parallelism (e.g., Device 1 and Device 2 in Figure 1 belong to the same partition), which can be computed as:
$$\mathsf{DataPCost}(\mathbf{C}_1 ... \mathbf{C}_{D_{PP}}) =$$
$$\max_{j \in \left[D_{PP} \right]} \max_{d \in \mathbf{C}_j} \sum_{ d' \in \mathbf{C}_j - \{d\} } 2 \left(\alpha_{d, d'} + \frac{c_{\text{dp}}}{D_{DP}{\beta}_{d, d'}}\right)$$
Then we merge each partition to generate a fully connected coarsened graph \(\mathbf{\widehat{G}}_{\mathbf{C}_1 ... \mathbf{C}_{D_{PP}}}\) where a node represents a pipeline stage and the edge represents the communication cost for pipeline parallelism between these two partitions computed by solving a perfect matching problem. Assuming \(\mathcal{M}\) is a perfect matching between \(\mathbf{C}_j\) and \(\mathbf{C}_{j'}\) the cost can be formulated as:
$$\min_{\mathcal{M}} \max_{(d, d') \in \mathcal{M}} 2 \left(\alpha_{d, d'} + \frac{c_{pp}}{\beta_{d,d'}} \right)$$
Lastly, we model the problem of finding the optimal pipeline structure as an open-loop-traveling-salesman problem over \(\mathbf{\widehat{G}}_{\mathbf{C}_1 ... \mathbf{C}_{D_{PP}}}\):
$$\mathsf{PipelinePCost}\left(\mathbf{C}_1 ... \mathbf{C}_{D_{PP}}\right)= $$
$$\mathsf{OpenLoopTSP} \left(\mathbf{\widehat{G}}_{\mathbf{C}_1 ... \mathbf{C}_{D_{PP}}}\right)$$
We then design a scheduling algorithm to search for the optimal allocation strategy given our cost model — developing a direct solution to this optimization problem is hard; thus, we adopt an efficient evolutionary algorithm based on a collection of novel heuristics, going beyond the traditional heuristics used in standard graph partitioning methods.
Performance of decentralized FM training
In our empirical study, we find that even when the network is 100x slower, the end-to-end training throughput is only 1.7-2.3x slower (for GPT-style models with 1.3B parameters). This result is very promising since it indicates that we could bridge the gap between decentralized and data center training (up to 100✕ slower networks) through scheduling and system optimizations such as pipelining communications and computations and use CUDA streams carefully!
Concretely, to evaluate the effectiveness of our scheduling algorithm, we use 64 Tesla V100 GPUs and control their pairwise communication latency and bandwidth to configure 5 different environments:
- Data center on demand. This is a standard setting that a user can obtain to train foundation models. we use 8 AWS p3.16xlarge nodes (each with 8 V100 GPUs); the intra-node connection is NVLink of 300 GB/s bidirectional bandwidth (150 GB/s unidirectional), and the inter-node connection has a bandwidth of 25 Gbps.
- Data center spot instances. Spot GPUs are cheaper in a data center but can be located on different types of machines. In this case, we rent 4 AWS p3.8xlarge nodes (each with 4 V100) and 32 p3.2xlarge nodes (each with 1 V100); the intra-p3.8xlarge node connection has a bandwidth of 100 Gbps, and the inter-node connection has a bandwidth of 10 Gbps.
- Multiple data centers. We consider two organizations, one in Ohio and another in Virginia, each organization contributes 32 V100 GPUs; within each organization, the bandwidth is 10 Gbps, and connections across different campuses have a delay of 10 ms and bandwidth of 1.12 Gbps.
- Regional geo-distributed. We consider individual GPUs across four different regions in US (California, Ohio, Oregon, and Virginia); within each region, the delay is 5 ms and bandwidth is 2 Gbps; cross different regions, the delay is 10-70 ms and the bandwidth is 1.0-1.3 Gbps.
- World-wide geo-distributed. We consider individual GPUs across eight different regions world-wide (Oregon, Virginia, Ohio, Tokyo, Seoul, London, Frankfurt, and Ireland); within each region, the delay is 5 ms and bandwidth is 2 Gbps; cross different regions, the delay is 10~250 ms and the bandwidth is 0.3~1.3 Gbps.
In Figure 4, we show the end-to-end compassion of our system with Megatron and DeepSpeed, which are state-of-the-art systems to support the training of foundation models. The comparison is conducted in 5 different scenarios. Column (a) and (b) visualize the delay and bandwidth of 5 scenarios respectively; Column (c) illustrate the comparison of our system, with and without the scheduler, and state-of-the-art systems including Megatron and DeepSpeed.
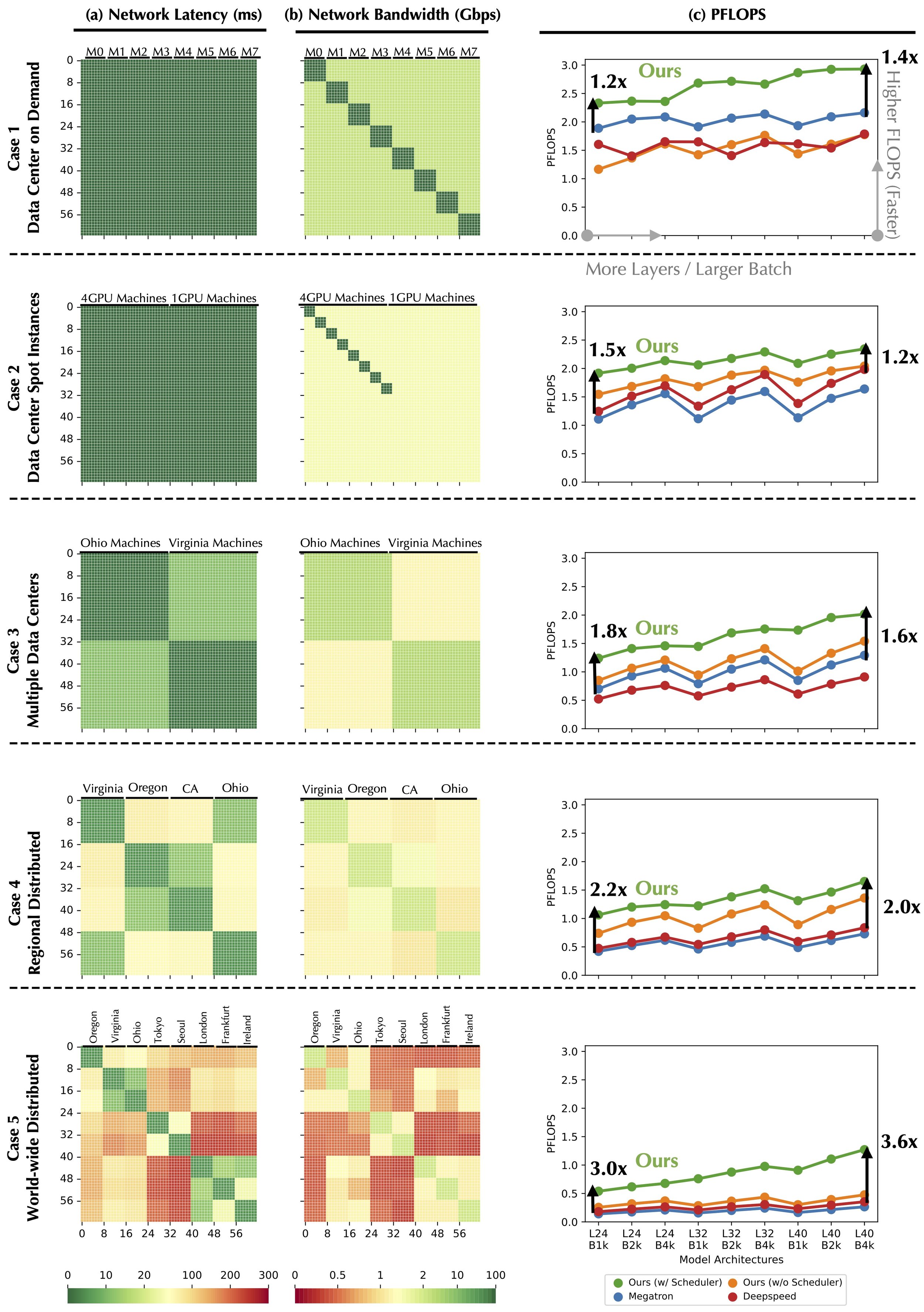
The result demonstrates that our system can speed up foundation model training in a decentralized setting. Specifically, our system is 4.8✕ faster, in end-to-end runtime than the state-of-the-art systems (Megatron and DeepSpeed) training GPT-3 (1.3B) in world-wide geo-distributed setting. Surprisingly, it is only 1.7-2.3✕ slower than these systems in data centers.
Can we apply our techniques to even larger models such as GPT3-175B? When the model size grows, on one hand, the amount of data that we need to communicate for both data parallelism and pipeline parallelism grows, but on the other hand, the amount of computation that we need to perform also grows. We expect the scheduling problem that we studied in this paper will continue to be important, but also believe that, to fully close the gap between the decentralized and the centralized training strategy, we need to go beyond pipeline and data parallelism and consider other notions of parallelism, e.g., tensor model parallelism and fully sharded data parallelism. We might also need to consider lossless or even lossy compression techniques. All these are promising future directions that we are exploring! Please let us know if you also find these questions to be interesting and we’d love to work together!
Beyond Scheduling
Scheduling is a fundamental problem for decentralized learning, and we are super excited about what we learned in this paper, which shows that with careful scheduling we can hide a significant amount of communications behind computations. However, decentralized learning requires much more than the scheduling components. There are a lot of other aspects that we need to be careful about for end-to-end systems:
- Fault tolerance, network jitters, heterogeneity on devices (e.g., the Varuna system by researchers at Microsoft Research is an awesome example)
- Training algorithms that are friendly to decentralized environments (e.g., the Gossip-style algorithm that we analyzed back in 2017 and many other research efforts done by the community)
- Communication compression for all data movement channels (e.g., our recent effort to compress all three channels,build on the tireless efforts by the community to push the boundary of compression in the last decade)
- Security and verification (e.g., the Slalom system by Florian Tramèr and Dan Boneh)
We have started to work on some of these problems and have some approaches that we'll formally describe in the future (e.g., see the GPT-JT model that was trained with slow networks). These problems are being tackled by many researchers in the community, and in the next few blog posts, we will deep dive into these topics and explore the excellent prior research in this area that we build upon.
Read more about our approach to optimize distributed training in part 2 here.