
Llama 3.1 has taken the world by storm, as the first open model to rival the best models available today. One of the advantages of open models is that anyone can host them. And, at first glance, given the same model, all providers appear to provide an equivalent service. Deciphering any differences, and properly benchmarking models as powerful as Llama 3.1 is challenging. However, once you do, you find that inference services are not fungible. Differences in implementation decisions, optimizations, and quality testing processes can mean the difference of a percentage point or more on a benchmark, and a success or a failure for your application task.
Recently there has been considerable discussion on Twitter regarding these differences.
Example 2: High school math problem
“A positive integer x is equal to twice the square of a certain positive integer y, and it is also equal to three times the cube of another positive integer z. What is the smallest positive integer x that satisfies these conditions”
Example 3: AI Researcher knowledge question (we couldn’t resist)
“What is group query attention?”
Our quality testing methodology
When hosting models for inference and optimizing for performance and scale, it can be difficult to determine if the model is providing the correct results. Unlike receiving a compilation error when something is off when coding, differences in output of these large models may be subtle, and unfortunately may not be significant enough to impact results of all benchmarks.
Therefore, we have developed a five step approach to evaluating if our model serving is providing the true reference quality:
- Reference matching
- Perplexity
- Analytic capability testing
- Generative capability testing
- Qualitative testing
Reference matching. The first pillar is to match the distribution exactly with the reference implementation (often those uploaded to official HuggingFace repositories, both for model weights and reference inference code) and our implementation. Since each operator has its own optimized kernel in our inference engine, it is important to make sure we catch any mismatch of semantics and accuracy gaps between our implementation and the reference implementation, to reduce negative error propagation to the end-to-end impact. Even though getting bitwise exact match of the distribution is hard because of factors such as difficult floating point reproducibility through reordering or even different tensor-parallel degrees, we make sure that the distributions produced by our implementation are within a close radius compared with the original reference model, for the all models that are released under the Together Reference tier.
Perplexity. The second pillar is to test the perplexity, which is often the direct objective that we optimize for during model approximation (e.g., during the calibration process of model quantization). Perplexity measures the ability of the model predicting the next token over a given corpus and any significant quantitative gap (e.g., 0.05) on perplexity often indicates qualitative difference of the model behavior.



Analytic capability testing. The third pillar is an ever growing collection of downstream benchmark tasks. The goal here is to directly measure the capability of the model in an automatic way to test its capacity on knowledge (closed book QA), in-context learning, long context retrieval, hallucination, etc. We run HELM classic on almost all of our models before their release and compare these numbers with those from the official full-precision implementations. Furthermore, Together’s Eval team continues to build up a large collection of benchmarks through the learning from the feedback of our customers on what matters to their production workloads. Figures above show the downstream task accuracy from our Together Turbo tier (FP8) offering compared to Meta’s reference implementations (F8 mixed precision for 405B and BF16 for 8B and 70B). For 8B and 70B models, our Turbo offering closely tracks the BF16 model quality (i.e., +0.1% on average for Llama-3.1-70B and -0.3% for Llama-3.1-8B). For the 405B model, Together Turbo achieves almost identical accuracy as the reference model.
Generative capability testing: One limitation of the downstream benchmark tasks is that they rarely measure the quality of long generations and the style of outputs, which are also important for many of our customers. The fourth pillar of quality testing relies on benchmarks such as AlpacaEval and Arena-Hard-Auto, which use powerful language models such as GPT-4 as judges. This is a really important category of benchmarks that are crucial for evaluating services for real-world production workloads.
Qualitative testing: The fifth pillar of quality testing is qualitative. We maintain a collection of test cases (and continue to grow them with our experience and customer feedback) and compare the model behavior with the reference model in a manual, qualitative way. For example, we found that the prompt “What is flash attention in LLMs” is quite powerful in testing the knowledge capacity of the model – if the model behaves significantly differently on these prompts compared with the reference implementation, it indicates room for improvements. Other good qualitative testing prompts include math and coding tasks, such as the examples shown in the prior section.
Why compromise?
A common mantra is that differences solely come down to a tradeoff between quality, performance, and price. While there is of course a tradeoff, this also assumes that no innovation is possible, that all techniques for generative AI inference are known. At Together AI, we are working hard to push the boundaries of inference optimization, to enable fast performance and the highest quality in a single competitively priced package we call Together Turbo. Together Turbo endpoints empower businesses to prioritize performance, quality, and price without compromise. We offer the most accurate quantization available for Llama-3.1 models, closely matching full-precision FP16 models. These advancements make Together Inference the fastest engine for NVIDIA GPUs and the most cost-effective solution for building with Llama 3.1 at scale. The below two figures demonstrate this combination of performance and quality for Llama-3.1-405B:
Llama 3.1 405B Performance – Artificial Analysis (7/30/2024)
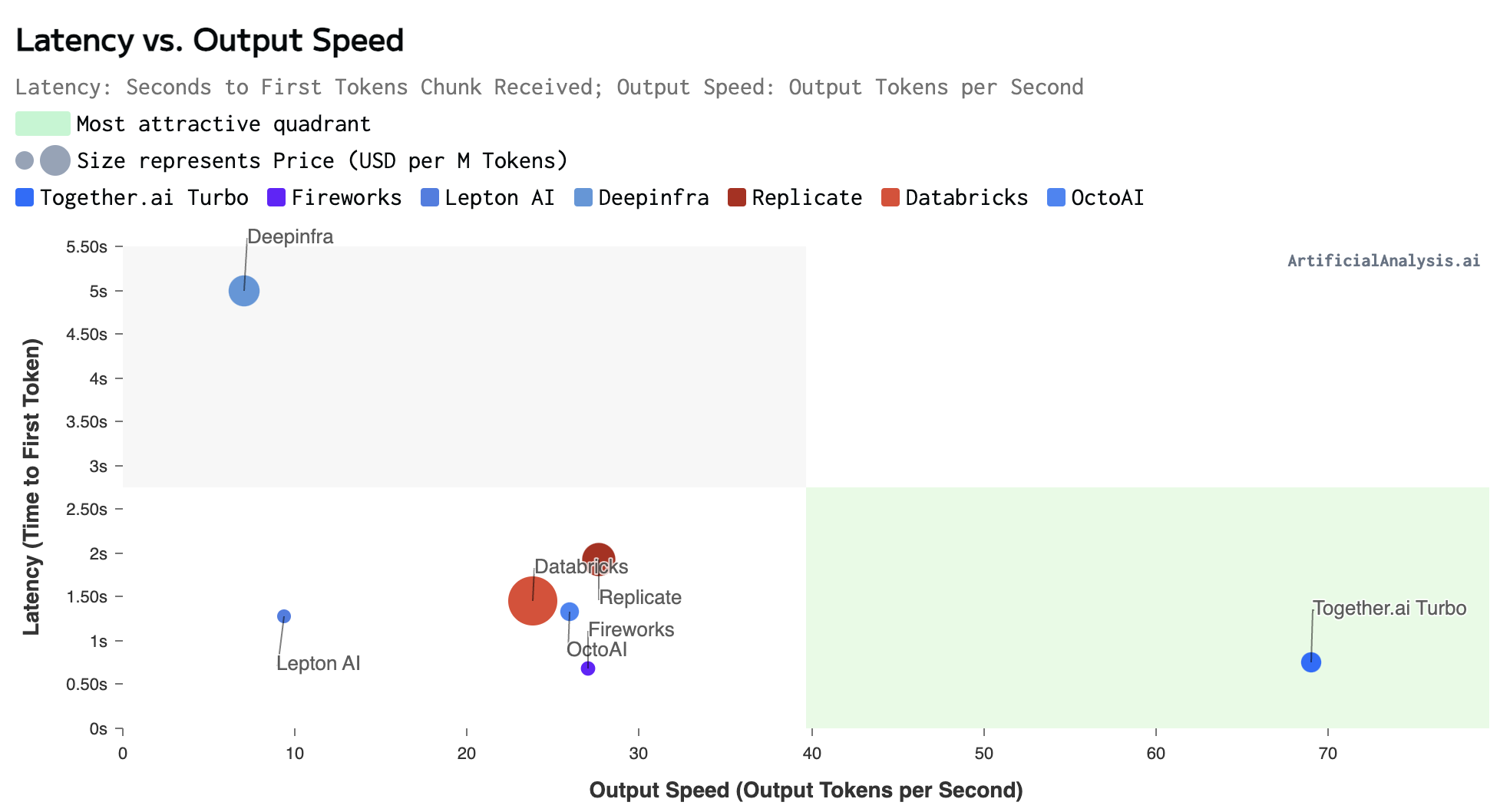
In terms of performance, the results from Artificial Analysis show the low latency and fast output performance of Together AI.

In terms of quality, we report the results using the data AlpacaEval 2.0 shown above to demonstrate real-world automatic evaluation. AlpacaEval 2.0 is a leading benchmark designed to assess the alignment of LLMs with human preferences. It includes 805 instructions that are representative of real-world use cases. Each model’s response is compared against that of GPT-4 (specifically the gpt-4-1106-preview version). A GPT-4-based evaluator is then used to determine the likelihood of preferring the evaluated model’s response. To ensure fairness, the evaluation employs length-controlled (LC) win rates, which effectively neutralize bias related to response length. This metric aligns well with human preferences, achieving a Spearman correlation of 0.98 with actual human evaluations. To minimize variance, we set the temperature to 0.0 and frequency penalty to 1.0 with a max output tokens of 2048. No system prompt was provided during the evaluation. The same configuration was consistently applied across all API providers. The figure demonstrates the superior model quality achieved by Together Turbo which faithfully implements the FP8 mixed precision quantization from Meta’s reference model, achieving superior model quality than other providers on the market.
In other words, the Together Turbo endpoint for Llama-3.1-405B successfully achieves the best of both worlds: superior performance and model quality.
A transparent approach
We believe in a transparent approach that allows you to understand what you’re getting with each endpoint we provide. Therefore, with the launch of Together Inference Engine 2.0 we introduced three tiers of endpoints that models are made available with:
- Together Reference endpoints are provided at the same precision the model was trained at and denoted either with “-Reference” in the model name or without any suffix.
- Together Turbo endpoints represent our flagship implementation for a given model, providing a near negligible difference in quality from the reference implementation with faster performance and lower cost, currently using FP8 quantization.
- Together Lite endpoints provide the most cost-efficient and scalable optimizations of a given model, currently using INT4 quantization.
As optimization techniques evolve these endpoints may be served with different levels of quantization but will be clearly stated in our documentation. Additionally, we will release new benchmarks over time demonstrating the quality and performance tradeoffs between these endpoints so that you can make an educated choice.
Moving Forward
Providing models with the highest quality is our deepest commitment to you. We strive to help you navigate the complex tradeoffs between quality, performance, and price, while working on innovations to enable you to get the best of all three whenever possible. We will continue to invest in research that further optimizes quality, performance, and cost and work to provide even greater transparency in the future.