

We’re excited to release Llama-2-7B-32K-Instruct, a long-context instruction model fine-tuned using Together API! Llama-2-7B-32K-Instruct achieves state-of-the-art performance for longcontext tasks such as summarization and multi-document question / answering (QA), while maintaining similar performance at a shorter context as Llama-2-7B. We are also releasing the full recipe we used to distill, train, test, and deploy the model.
We built Llama-2-7B-32K-Instruct using the Together API and today we’re making fine-tuning Llama-2 available publicly with Together API!
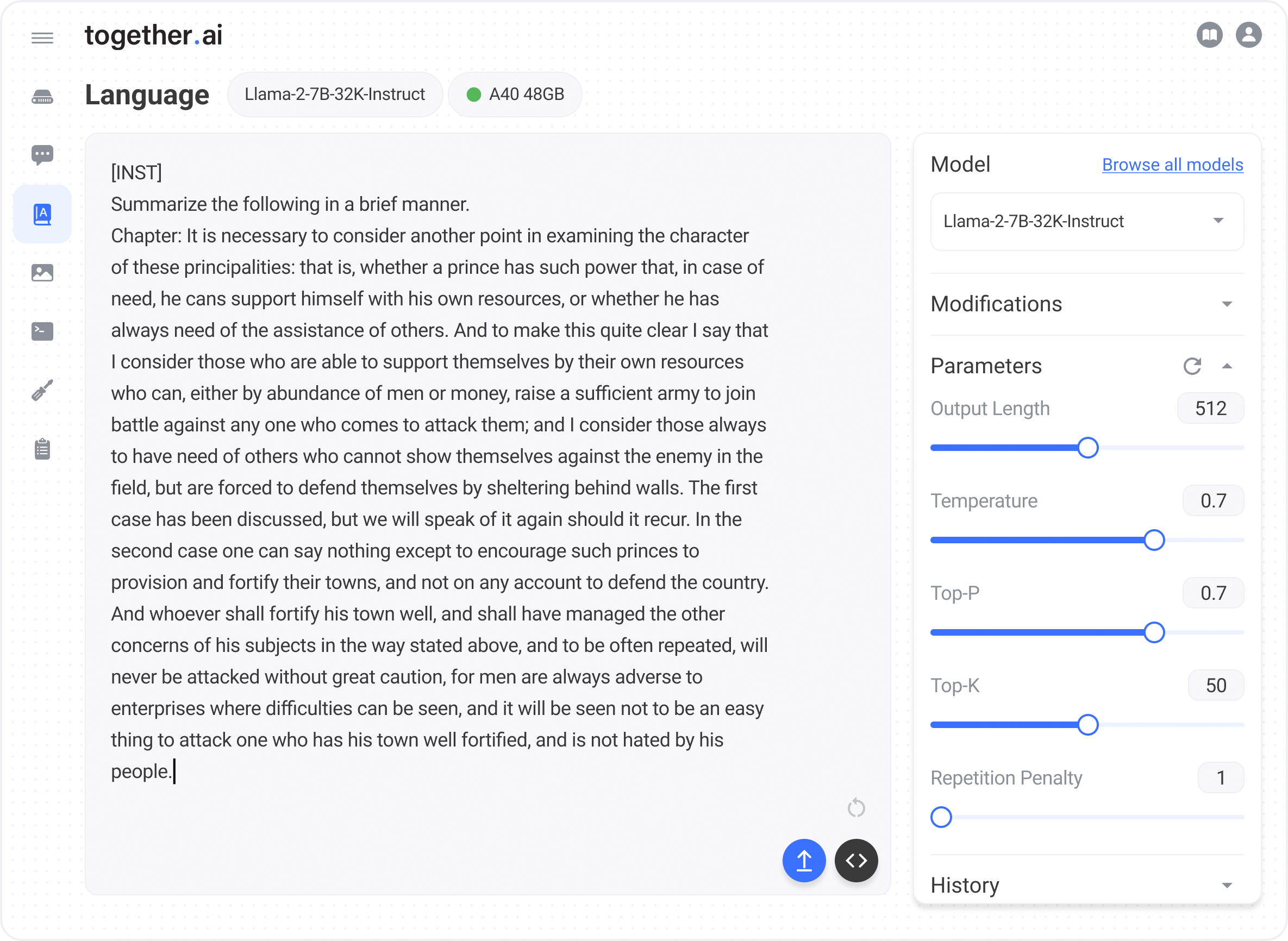
Last month, we released Llama-2-7B-32K, which extended the context length of Llama-2 for the first time from 4K to 32K — giving developers the ability to use open-source AI for long-context tasks such as document understanding, summarization, and QA.
To provide an example of this fine-tuning capability, we’re introducing Llama-2-7B-32K-Instruct — a long-context instruction-tuned model that we built with less than 200 lines of Python script using Together API. We fine-tuned this model over a mixture of three data sources: 1) a set of single- and multi-round conversations generated by human instructions and Llama-2-70B-Chat outputs, collected using the Together Inference API; 2) summarization data from the BookSum dataset; and 3) multi-document QA dataset.
The Llama-2-7B-32K-Instruct recipe: Four main steps to build custom models
The code used to implement this recipe using Together API, including the data preparation, is available on Github. The four main steps are outlined below: Distill, Train, Test, and Deploy.

Step 1: Distill
As mentioned, we fine-tuned our new model with a mixture of three data sources. The details and our pre-processing steps on BookSum and Multi-document Answering can be found in our previous blog post and our complete data recipe. In this blog post, we share our detailed steps of building the single- and multi-round conversation datasets.
We follow the distillation paradigm that is used by Alpaca, Vicuna, WizardLM, and Orca — producing instructions by querying a powerful LLM, which, in our case, is Llama-2-70B-Chat. We do this by leveraging the Together Inference API. For example, given an instruction, such as:
instruction = "Create a table about national parks in the US"We can formulate a prompt in the form of "[INST] {instruction} [/INST]", which is the standard prompt format of Llama-2-70B-Chat, we can query the Together Inference API using the following code:
res = requests.post("https://api.together.xyz/inference", json={
"model": "togethercomputer/llama-2-70b-chat",
"max_tokens": 1024,
"prompt": "[INST] " + instruction + " [/INST]",
"request_type": "language-model-inference",
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"repetition_penalty": 1,
"stop": [
"[INST]"
],
"safety_model": "",
"repetitive_penalty": 1
}, headers={
"Authorization": "Bearer " +
})
We then parse the result with:
response = res.json()["output"]["choices"][0]["text"]
In this particular case, it returns:
Sure, here's a table about national parks in the US:
Sure, here's a table about national parks in the US:
| National Park | Location | Established | Area (acres) | Notable Features |
| --- | --- | --- | --- | --- |
| Yellowstone | Wyoming, Montana, Idaho | 1872 | 2,219,790 | Geysers, hot springs, wildlife |
| Grand Canyon | Arizona | 1919 | 1,218,375 | Colorado River, canyon, scenic views |
| Yosemite | California | 1890 | 747,956 | Granite cliffs, waterfalls, giant sequoias |
| Zion | Utah | 1919 | 146,597 | Canyons, sandstone cliffs, unique rock formations |
| Great Smoky Mountains | North Carolina, Tennessee | 1926 | 522,426 | Mountains, forests, waterfalls, wildlife |
| Rocky Mountain | Colorado | 1915 | 265,795 | Mountains, alpine lakes, glaciers, wildlife |
| Acadia | Maine | 1916 | 33,255 | Coastline, mountains, forests, wildlife |
| Olympic | Washington | 1938 | 922,650 | Rainforests, mountains, coastline, wildlife |
| Grand Teton | Wyoming | 1929 | 310,044 | Mountains, glaciers, lakes, wildlife |
| Great Basin | Nevada | 1986 | 5,000 | 5,000-year-old bristlecone pine trees, limestone caverns |
| Arches | Utah | 1971 | 7,200 | Over 2,000 natural arches, sandstone formations |
| Bryce Canyon | Utah | 1928 | 35,835 | Hoodoos, amphitheater-shaped park, scenic views |
| Canyonlands | Utah | 1964 | 337,598 | Canyons, mesas, buttes, desert landscapes |
| Death Valley | California, Nevada | 1994 | 3,373,063 | Badwater Basin, salt flats, sand dunes, unique geology |
| Denali | Alaska | 1917 | 4,740,911 | Mount Denali, glaciers, wildlife, dog sledding |
| Everglades | Florida | 1935 | 1,508,537 | Mangrove forests, sawgrass marshes, diverse wildlife |
| Glacier | Montana | 1910 | 1,012,837 | Glaciers, alpine lakes, mountains, wildlife |
| Glacier Bay | Alaska | 1925 | 3,223,373 | Fjords, glaciers, mountains, wildlife |
Note: This table lists some of the most well-known national parks in the US, but there are many others that are also worth visiting. The area of each park is approximate and may vary slightly depending on the source.
Note: This table lists some of the most well-known national parks in the US, but there are many others that are also worth visiting. The area of each park is approximate and may vary slightly depending on the source.
To build Llama-2-7B-32K-Instruct, we collect instructions from 19K human inputs extracted from ShareGPT-90K (only using human inputs, not ChatGPT outputs). The actual script handles multi-turn conversations and also supports restarting and caching via a SQLite database. You can find the full script here, with merely 122 lines!
Finally, we write all the instructions and answers to a single jsonl file, with each line corresponding to one conversation:
{"text": "[INST] ... instruction ... [/INST] ... answer ... [INST] ... instruction ... [/INST] ..."}
{"text": "[INST] ... instruction ... [/INST] ... answer ... [INST] ... instruction ... [/INST] ..."}
{"text": "[INST] ... instruction ... [/INST] ... answer ... [INST] ... instruction ... [/INST] ..."}
This is also the accepted training format for the Together Fine-tuning API.
Step 2: Train
The second step is to fine-tune the Llama-2-7B-32K model using our data mixture.
First, upload the dataset. Let’s say the instruction data is stored in instructions.jsonl, with the following command:
$ together files upload instructions.jsonl
The data uploads to the Together Cloud, making it available for your fine-tuning jobs. Note that Together AI does not keep any customer or training data unless you give consent to use for your training request.
Second, start a fine-tuning job using the file ID provided in the response to the file upload command:
$ together finetune create --training-file file-cab9fb70-b6de-40de-a298-d06369b14ed8 --model togethercomputer/LLaMA-2-7B-32K
Third, track the progress of your fine-tuning job in the Jobs page on api.together.ai. You can view event logs and checkpoints.
Step 3: Test
Once your fine-tuning job is completed, which for us took just a few hours, the fine-tuned model will automatically appear on the Models page. Click play to start an instance, and begin testing your model in the Together Playgrounds.
Step 4: Deploy
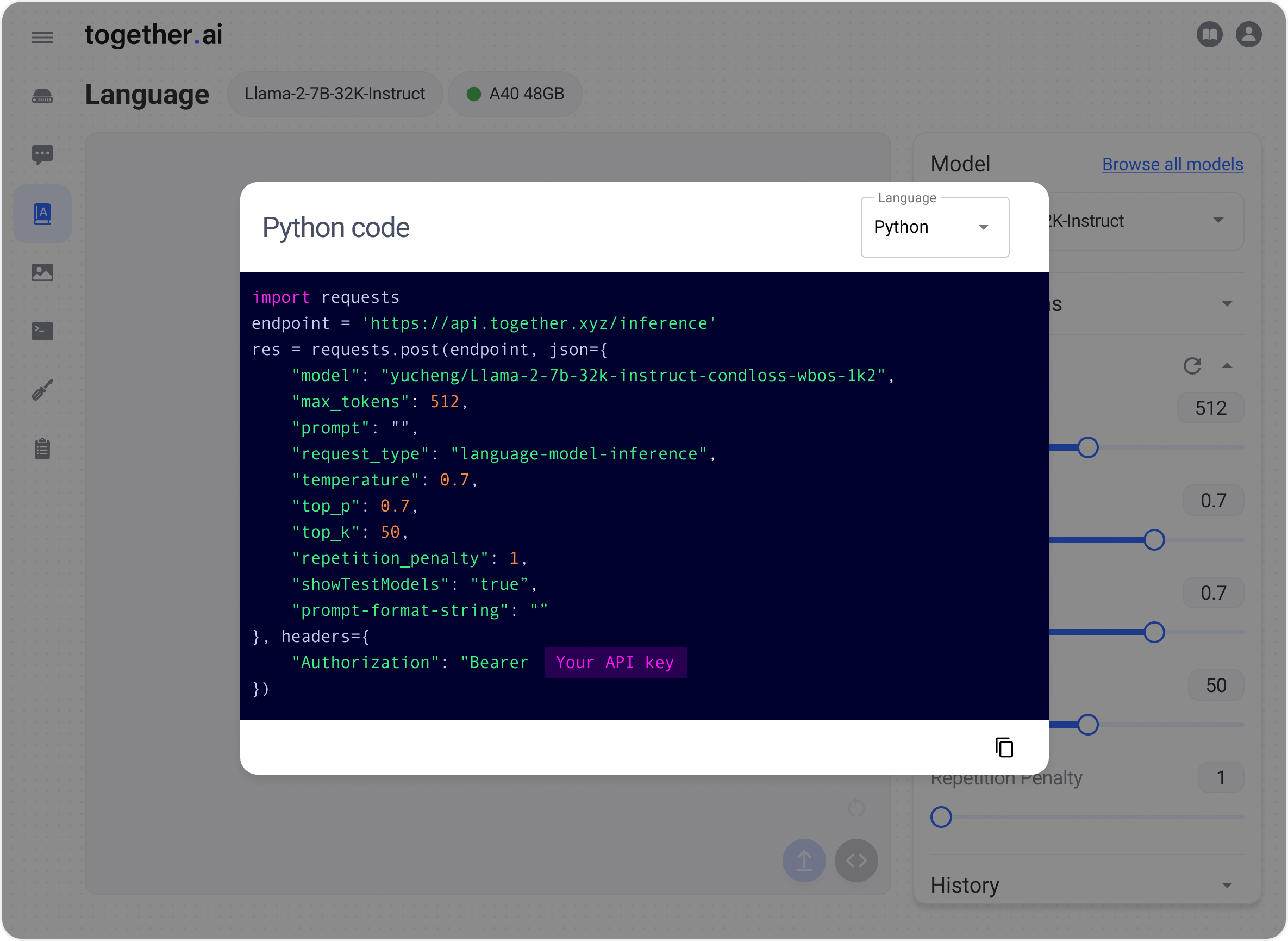
Now that you’ve tested the model in the Together Playground, you can integrate the model into your application! Query the model using the Together Inference API. Simply click “<>” in the Playground to see examples of how to query it via the API.
One immediate example is to benchmark the model that you just trained! It involves querying the inference API over a collection of evaluation examples. In this script, we provide one example of how to prepare results for Alpaca Eval. We see that for short context, we get comparable quality as a Llama-2-7B-Chat model.
| Model | win_rate | standard_error | n_total | avg_length |
|---|---|---|---|---|
| llama-2-7b-chat-hf | 71.37 | 1.59 | 805 | 1479 |
| Llama-2-7B-32K-Instruct | 70.36 | 1.61 | 803 | 1885 |
| oasst-rlhf-llama-33b | 66.52 | 1.66 | 805 | 1079 |
| text_davinci_003 | 50.00 | 0.00 | 805 | 307 |
| falcon-40b-instruct | 45.71 | 1.75 | 805 | 662 |
| alpaca-farm-ppo-human | 41.24 | 1.73 | 805 | 803 |
| alpaca-7b | 26.46 | 1.54 | 805 | 396 |
| text_davinci_001 | 15.17 | 1.24 | 804 | 296 |
Table 1: Alpaca Eval Result of Llama-2-7B-32K-Instruct. Refer to https://github.com/tatsu-lab/alpaca_eval#limitations for a list of limitations and potential biases of automatic evaluation.
The power of Llama-2-7B-32K-Instruct is the ability to input instructions that are much longer than you can use with the base Llama-2 models. In addition to the summarization example we illustrated in the beginning, following is another example of multi-document QA:
Model Evaluation
We follow the protocol from our previous blog post, and evaluate Llama-2-7B-32K-Instruct on two tasks — long context summarization and multi-document QA, as summarized below:
| Model | R1 | R2 | RL |
|---|---|---|---|
| Llama-2-7b-chat | 0.055* | 0.008* | 0.046* |
| Longchat-7b-16k | 0.303 | 0.055 | 0.160 |
| Longchat-7b-v1.5-32k | 0.308 | 0.057 | 0.163 |
| GPT-3.5-Turbo-16K | 0.324 | 0.066 | 0.178 |
| Llama-2-7B-32K-Instruct | 0.336 | 0.076 | 0.184 |
Table 2: Rogue score on BookSum.
* For Llama-2-7b-chat, we truncate the inputs when it does not fit into the 4K context.
| Model | Number of Documents | ||
|---|---|---|---|
| 20 docs (Avg. 2.9K tokens) | 30 docs (Avg. 4.4K tokens) | 50 docs (Avg. 7.4K tokens) | |
| Llama-2-7b-chat | 0.448 | 0.421* | 0.354* |
| Longchat-7b-16k | 0.510 | 0.473 | 0.428 |
| Longchat-7b-v1.5-32k | 0.534 | 0.516 | 0.479 |
| GPT-3.5-Turbo-16K | 0.622 | 0.609 | 0.577 |
| Llama-2-7B-32K-Instruct | 0.622 | 0.604 | 0.589 |
Accuracy of multi-document question answering under various # documents.
* For Llama-2-7b-chat, we truncate the inputs when it does not fit into the 4K context.
We observe that our fine-tuned Llama-2-7B-32K-Instruct consistently outperforms other baseline models including GPT-3.5-Turbo-16k, Llama-2-7b-chat, Longchat-7b-16k and Longchat-7b-v1.5-32k. It suggests the delivered model from Together API is robust across long-context benchmarks. Comparing Llama-2-7B-32K-Instruct and GPT-3.5-Turbo-16K, we observe that Llama-2-7B-32K-Instruct produces comparable, and sometimes better results on summarization and long-context regime of QA (50 docs).
Start fine-tuning Llama-2
The Together API makes it easy to fine-tune Llama-2 with your own data. As outlined in this post, simply upload a file, specify your hyperparameters, and start training. Full documentation available here.
We can’t wait to see what you’ll build!