
Together’s software network harnessed spare GPU cycles across thousands of servers to benchmark 10 prominent open language models and process 11 billion tokens.
We have entered the era of foundation models — massive models trained on huge amounts of data — which can be adapted to a wide range of applications. Language models such as GPT-3 in particular have rich capabilities. They can improve the quality of existing applications (e.g., question answering) and introduce novel applications (e.g., brainstorming slogans or writing blog posts).
The pace of innovation is rapid, with new models being announced regularly. But given the vast surface of capabilities of language models, it’s not clear when they work and when they don’t, which is critical for downstream users. The Stanford Center for Research on Foundation Models (CRFM) has recently announced Holistic Evaluation of Language Models (HELM), a comprehensive effort to benchmark 30 language models. 10 of these models are open, with their model weights released as open-source.

A core challenge in building HELM is computation. HELM covers 42 scenarios from question answering to sentiment analysis. Running HELM on the 10 open models requires running inference over more than 11 billion input tokens and 1.6 billion output tokens. These experiments required over 60,000 GPU hours for all tests and tuning, with the final full run of benchmarks requiring 20,000 GPU hours. As new open models are released (e.g., Flan-T5, BLOOMZ, Galatica) and the number of scenarios grow, the maintainance and expansion of the benchmark will create a growing demand for computation.
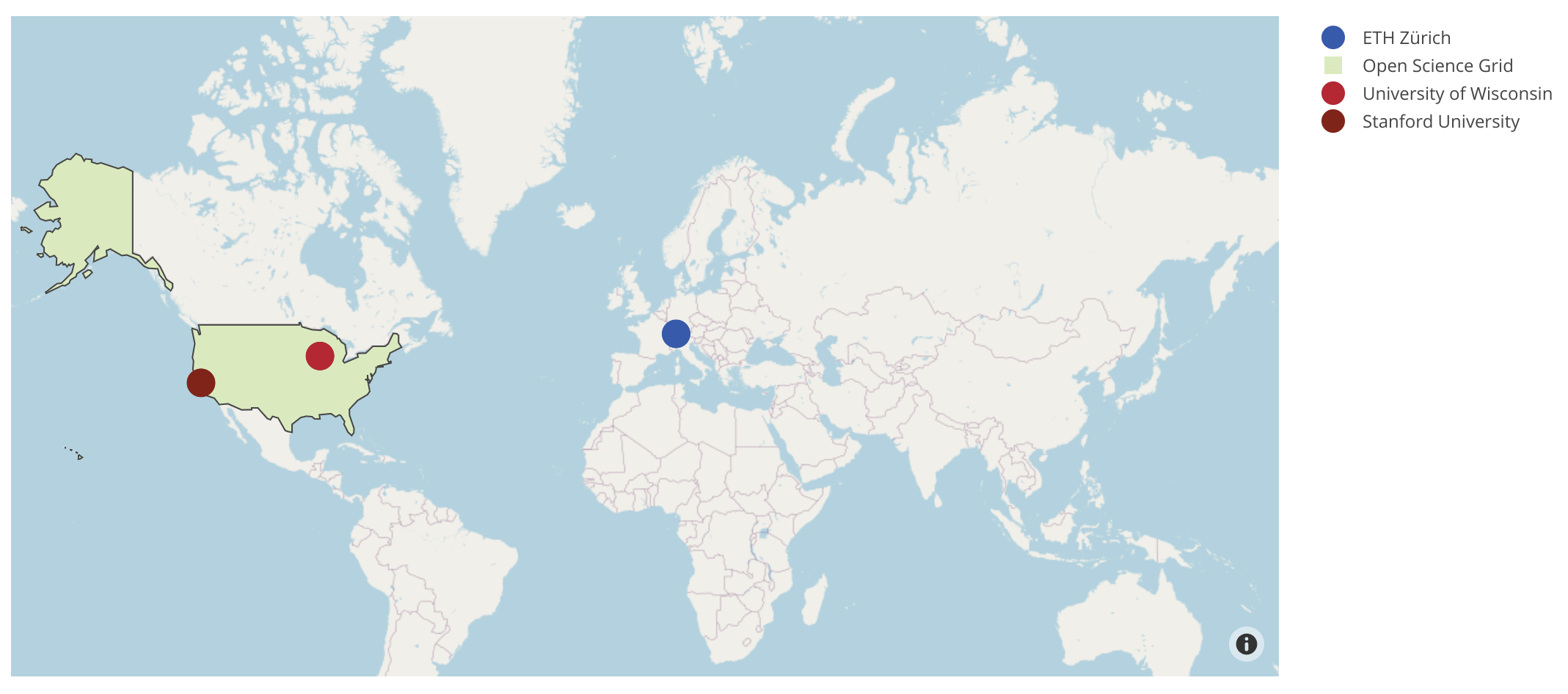
Instead of relying on dedicated cloud services, HELM is enabled by a different source of computing, one enabled by the research community. More specifically, these are “idle” GPU cycles in academic clusters. From our experience on Open Science Grid and three academic clusters (Stanford, ETH Zurich, and the University of Wisconsin-Madison), there are more than 2,000 GPU cards in total, and it is not uncommon to see hundreds of these cards idle for several hours a day (as long as it’s not right before a major conference deadline!). How can we aggregate all these computation resources, not only to support HELM, but to enable researchers to tackle more ambitious projects?
Together is building systems to enable this kind of efficient, shared compute for AI. Together’s mission is to bring the world’s compute together to enable everyone to contribute to and benefit from advanced AI. We have roots in academic research and are committed to the growth in open research and advancing the state of open AI models.
As an early step towards this mission, we started by aggregating academic compute into the Together Research Computer. The Together Research Computer today combines the resources from five partners (Stanford, ETH Zurich, Open Science Grid, University of Wisconsin-Madison, and CrusoeCloud) with a total of more than 200 PetaFLOPS worth of compute. All 10 open models in HELM are run on the Together Research Computer.
Decentralized computing can solve the computation bottlenecks in LLMs, and make the field more accessible to researchers and practitioners.
There are a range of technical challenges in aggregating decentralized compute for using large models. To support HELM’s benchmarking, we specifically optimized for the high-throughput setting, where we seek to maximize throughput (# tokens/seconds) instead of the latency of a single inference task. The HTCondor project and the Center of High-Throughput Computing at UW-Madison, who pioneered this concept was a source of inspiration here.
First, to support the largest models (a 175 billion parameter model requires 350GB of storage), we have to partition the model onto different devices — already a challenging task with dedicated machines in the cloud. In our decentralized setting, this becomes even harder. Machines and networks can be vastly heterogeneous, and to best utilize all available devices, we need to carefully partition a large model and map different parts of the computation tasks to different devices. In [https://arxiv.org/abs/2206.01288], we describe some of our research on resource allocation for training under heterogeneous networks, and we follow a similar approach to handle inference on heterogeneous devices. The pioneering work by HT-Condor project has been an inspiration for us in the design of high-throughput AI.
Second, we need to gracefully handle preemption; after all, we harvest GPU cycles only when no one is using these machines and will be evicted the moment these machines are required by other users. Especially when models are partitioned among different devices, a part of the model might be evicted while another part is still running, so handling preemption requires care. We periodically checkpoint and synchronize the inference results to a global file system and designed a communication-efficient way of detecting evictions.
We are excited by what the Together Research Computer, an early application of our distributed computing technology, has enabled so far and plan to continue supporting HELM as well as other benchmark efforts such as DataPerf [https://dataperf.org/] in collaboration with MLCommons [https://mlcommons.org/en/]. Benchmarking is just the first step; we also want to support fine-tuning and pre-training of foundation models.
Together is committed to building a thriving ecosystem for open foundation models and mechanisms to aggregate compute at a very large scale. We believe better open models will create widespread value and create equitable access to this important technology. To get there, we want to involve the AI communities in research and industry. We are looking for partners who have idle compute to share, researchers who are interested in decentralized training or just trying out ideas on the Together Research Computer. Please talk to us if you are also excited by this vision. Let’s build the best open models in the world, together!