
We introduce Mixture of Agents (MoA), an approach to harness the collective strengths of multiple LLMs to improve state-of-the-art quality. And we provide a reference implementation, Together MoA, which leverages several open-source LLM agents to achieve a score of 65.1% on AlpacaEval 2.0, surpassing prior leader GPT-4o (57.5%).

For a quick summary on MoA and 3-minute demo on how to implement this with code, watch the video below. Or keep reading to learn more about our research.
Overview
We are excited to introduce Mixture of Agents (MoA), a novel approach to harness the collective strengths of multiple LLMs. MoA adopts a layered architecture where each layer comprises several LLM agents. These agents take the outputs from the previous layer as auxiliary information to generate refined responses. This approach allows MoA to effectively integrate diverse capabilities and insights from various models, resulting in a more robust and versatile combined model.
Our reference implementation, Together MoA, significantly surpass GPT-4o 57.5% on AlpacaEval 2.0 with a score of 65.1% using only open source models. While Together MoA achieves higher accuracy, it does come at the cost of a slower time to first token; reducing this latency is an exciting future direction for this research.
Our approach is detailed in a technical paper on arXiv; and the open-source code is available at: togethercomputer/moa, including a simple interactive demo. We look forward to seeing how MoA will be utilized to push the boundaries of what AI can achieve.
Mixture of Agents
Our research is based on a key observation we term the collaborativeness of LLMs — the phenomenon where an LLM tends to generate better responses when presented with outputs from other models, even if these other models are less capable on their own.
To investigate if this phenomenon is prevalent across open-source models, we evaluated the score when leveraging responses from other models in an answer. Figure 2 shows that each model increases significantly from their base score on AlpacaEval 2.0. This improvement occurs even when the reference response quality is lower than the model’s own.

To effectively leverage the collaboration of multiple LLMs, we categorize their roles based on their strengths in different aspects of collaboration:
Proposers: These models generate initial reference responses. While a proposer might produce a high-quality response on its own, its main value lies in offering nuanced and diverse perspectives that serve as valuable references for the aggregator.
Aggregators: These models synthesize the different responses from the proposers into a single, high-quality response.
Based on this categorization, we propose a layered process to improve responses, as illustrated in Figure 1. Initially, several proposers independently generate responses to a given prompt. These responses are then presented to aggregators in the next layer, who synthesize them into higher-quality responses. This iterative process continues through several layers until a more robust and comprehensive response is achieved.
Together MoA achieves state-of-the-art performance
Below we give a overview of our reference implementations shown in the leaderboards:
- Together MoA, uses six open source models as proposers and Qwen1.5-110B-Chat as the final aggregators. The six open source models tested are: WizardLM-2-8x22b, Qwen1.5-110B-Chat, Qwen1.5-72B-Chat, Llama-3-70B-Chat, Mixtral-8x22B-Instruct-v0.1, dbrx-instruct. We design MoA to have a total of three layers, striking a good balance between quality and performance.
- Together MoA-Lite uses the same set of proposers, but uses Qwen1.5-72B-Chat as the aggregator and only has two layers.
- Together MoA w/ GPT-4o also uses the same set of proposers and has three layers, but the final aggregator is changed to GPT-4o.
We present our evaluation results on three standard benchmarks: AlpacaEval 2.0, MT-Bench, and FLASK. These benchmarks were chosen to comprehensively assess the performance of our approach and compare with the state-of-the-art LLMs. Specifically, we achieved top positions on both the AlpacaEval 2.0 leaderboard and MT-Bench. Notably, on AlpacaEval 2.0, using solely open-source models, we achieved a margin of 7.6% absolute improvement from 57.5% (GPT-4o) to 65.1% (Together MoA). The Together MoA-Lite configuration, despite its fewer layers and being more cost-effective, still achieved scores comparable to those of GPT-4o.
Table 1: Results on AlpacaEval 2.0. We ran our experiments three times and reported the average scores along with the standard deviation. † denotes our replication of the AlpacaEval results.
Table 2: Results on MT-Bench. We ran our experiments three times and reported the average scores along with the standard deviation. We ran all the MT-Bench scores ourselves to get turn-based scores.
FLASK offers fine-grained evaluation of models across multiple dimensions. Together MoA method significantly outperforms the original Qwen1.5-110B-Chat on harmlessness, robustness, correctness, efficiency, factuality, commonsense, insightfulness, completeness. Additionally, Together MoA also outperforms GPT-4o in terms of correctness, factuality, insightfulness, completeness, and metacognition.

Do we need multiple layers in MoA?
We also benchmarked the LC win rate of each layer of Together MoA on AlpacaEval 2.0. A consistent and monotonic performance gain can be achieved after each layer. All the curves use the same 6 proposer agents; they only differ in the choice of the aggregator on top of them. We also added a baseline where a LLM-Ranker (Qwen1.5-110B-Chat) is used to pick the best response from the reference responses. This further demonstrates that the aggregator is sophisticatedly synthesizing rather than just picking and selecting.

Do we need multiple LLMs as proposers?
To assess the influence of the number of proposers on performance, we conducted experiments with varying numbers of proposed answers. We denote n as number of proposed outputs either from different proposers or the same proposer. We use Qwen1.5-110B-Chat as the aggregator for all settings in this table.
We can see there is clearly a consistent advantage brought by having more proposer outputs even with Single-Proposer. However, the Multiple-Proposer configuration consistently outperforms Single-Proposer, indicating that integrating a wider variety of inputs from different models significantly enhances the output. This highlights the value of leveraging diverse perspectives and capabilities that different models offer.
Table 3: Effects of the number of proposer models on AlpacaEval 2.0.
The cost-effectiveness of MoA
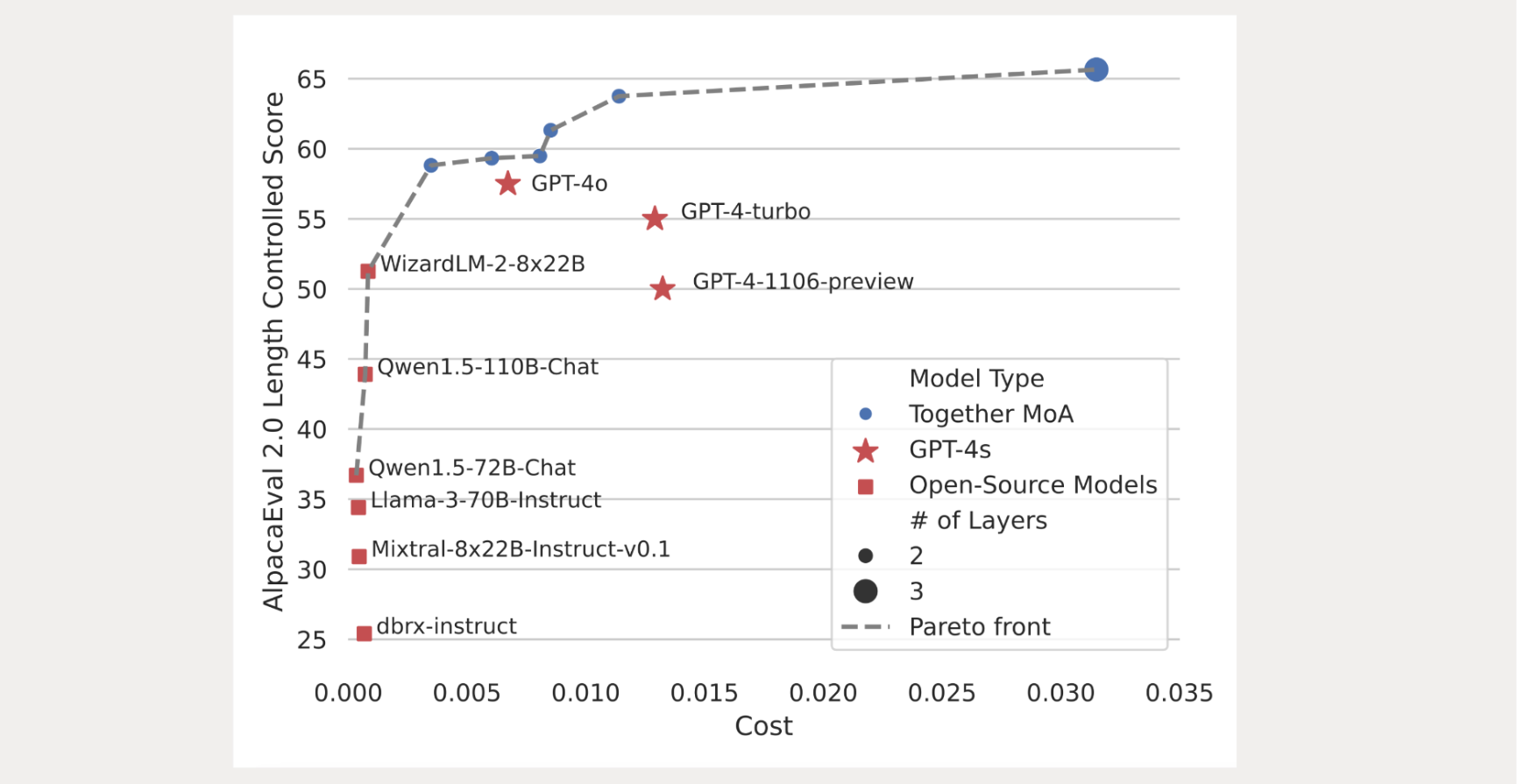
To gain a deeper understanding of accuracy and cost-effectiveness, we present a figure that illustrate these relationships. In the figure, we plot the LC win rate against the average inference cost for each query. For open-source models, we calculate the price using data from the Together API; for OpenAI models, we use pricing details from the OpenAI API. Pricing data was retrieved as of May 22, 2024.
The dashed curve identifies the Pareto front, indicating the most optimal balance between cost and performance. If we prioritize performance, the Together MoA configuration is the best choice. However, if we aim to strike a good balance between quality and cost, the Together MoA-Lite configuration can match GPT-4o cost while achieving higher quality.
Acknowledgements
Notably, this work was made possible by the collaborative spirit and contributions of several active organizations in the open-source AI community. We appreciate the shared contributions of Meta AI, Mistral AI, Microsoft, Alibaba Cloud, and DataBricks for developing the Meta Llama 3, Mixtral, WizardLM, Qwen, and DBRX models. Additionally, we extend our gratitude to Tatsu Labs, LMSYS, and KAIST AI for developing the AlpacaEval, MT-Bench, and FLASK evaluation benchmarks.
Conclusion & future directions
Together MoA leverages the strengths of multiple open-source LLMs through successive stages of collaboration, leading to superior performance compared to strong closed-source models. This study highlights the potential to enhance AI systems, making them more capable, robust, and aligned with human reasoning.
We are excited by the immediate applications of this technique for offline processing, synthetic data generation for training, or applications for which accuracy is of paramount importance.
Looking ahead, we are interested in several potential future directions. One key area of interest is the systematic optimization of the MoA architecture, exploring various choices of models, prompts, and architectural configurations. We plan to optimize the latency of time to first token, and have a number of techniques we expect will significantly improve the performance. Additionally, we aim to evaluate and optimize Together MoA for more reasoning-focused tasks, further enhancing its ability to tackle complex and nuanced challenges in AI.