
We present TEAL (Training-Free Activation Sparsity in LLMs), a simple training-free approach to activation sparsity that applies magnitude pruning to hidden states throughout the model. In particular, TEAL achieves 40-50% model-wide activation sparsity with minimal degradation, allowing us to transfer less weights to on-chip memory. Because LLM inference is memory-bound, we can translate this into 1.53-1.8x wall-clock speedups in single-batch decoding!
.png)
Background
Large Language Models (LLMs) are very large, which leads to many challenges in inference. LLM Inference is unique in that it is memory bound: it’s bottlenecked by the speed at which the parameters can be moved from device memory to registers. As such, a variety of subfields have emerged that address this memory wall, including quantization, weight sparsity, speculative decoding, etc.
Activation sparsity is a less studied method that leverages zero values in the hidden states of LLMs. Weight channels associated with zero-valued activations are unnecessary during decoding, and we can thus achieve speedup by avoiding the transfer of such channels to on-chip memory.
Older models such as OPT-175B are very conducive to activation sparsity. In fact, past work finds that the intermediate states of ReLU-based MLPs (in Transformers) exhibit extreme emergent sparsity (around 95%!). This largely enables DejaVu to realize a 2x wall-clock speedup. However, newer models (including LLaMA) have moved away from ReLU-based MLPs and towards variants like SwiGLU, due to empirically better performance of the latter. As such, the intermediate states are no longer naturally sparse, making it more difficult to apply methods like DejaVu. Recent work has found that replacing SiLU with ReLU in the MLP blocks and performing continued pretraining can “recover” models that exhibit activation sparsity (thus making older methods applicable) (ReLUfication, ProSparse, TurboSparse), but they require training on up to hundreds of billions of tokens.
Most recently, CATS realizes training-free activation sparsity on SwiGLU based LLMs, and impressively achieves up to 50% sparsity in $\textbf{W}_\text{up}$ and $\textbf{W}_\text{down}$ for Mistral and Llama-2-7B without fine-tuning. However, other tensors (including $\textbf{W}_\text{gate}$ and $\textbf{W}_\text{q,k,v,o}$) are computed without sparsification, resulting in lower model-wide sparsity (roughly 25%).
A cheap and accessible approach for activation sparsity would be valuable. However, existing methods face limitations that inhibit widespread adoption. Some approaches require extensive continued pretraining on up to hundreds of billions of tokens. Other training-free approaches achieve impressive activation sparsity in certain areas of the model but do not achieve enough model-wide sparsity. TEAL aims to bridge this gap.
Motivating Study: Distributional Properties of Activations in LLMs

Past work finds that hidden states in LLMs exhibit outliers (SmoothQuant, LLM.int8()). We additionally find that they are zero-centered and exhibit similar distributional shapes across layers. In particular, those before MLP and Attention Blocks are Gaussian shaped, and those in the intermediate of such blocks are Laplacian shaped. We don’t have a strong explanation as to why this occurs, but we do leave a few theories in our paper. In particular, multiplying a Gaussian Matrix with a Gaussian Vector results in a Laplacian-like distribution, which may be related. Nevertheless, as both distributions are densely concentrated near and around zero, we should potentially be able to prune out many low-magnitude activations with negligible model degradation (footnote: CATS makes a similar observation with respect to the output of $\text{SiLU}(\textbf{x}\textbf{W}_\text{gate}^\top)$). To that end, we define our sparsification function as follows:

TEAL
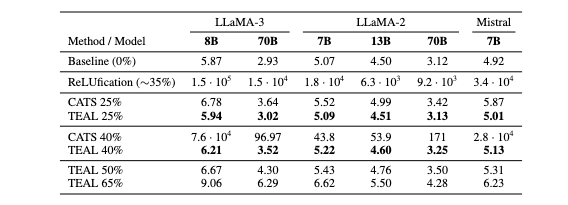
As it turns out, we actually can! In our paper, we introduce another small optimization – optimizing sparsity levels for each tensor at the transformer block level. TEAL sparsifies every tensor in the model, showcasing near-zero degradation at 25%, and minimal degradation at 40% sparsity. At 50% sparsity, Llama-3 variants show slightly more degradation compared to older Llama-2 and Mistral variants which are still fairly performant.
Most notably, TEAL outperforms CATS due to two reasons. First, and most importantly, our ability to sparsify every tensor. Second, our design choice to sparsify $\mathbf{W}_\text{up}$ through input $\mathbf{x}$ yields lower error than CATS’ choice to sparsify through gated output $\text{SiLU}(\mathbf{x}\mathbf{W}_\text{gate}^\top)$, which we further analyze in the paper.
Hardware-Aware Speed-up
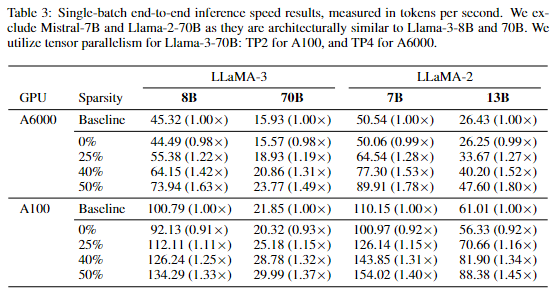
We make a few improvements targeting overhead in the sparse kernel introduced by DejaVu, which we also discuss in the paper. To benchmark real world speedup, we integrate TEAL with GPT-Fast, and enable \texttt{torch.compile} with CUDA Graphs. As shown below, TEAL achieves significant speed-ups of up to 1.53x and 1.8x at 40% and 50% sparsity respectively. We note that on A100, our kernel is faster than \texttt{torch.matmul} (cuBLAS) at 0% sparsity, but is slower than the GEMV kernel generated by \texttt{torch.compile}. Evidently, there still may be room for further kernel optimization!
Compatibility with Quantization
Finally, we demonstrate compatibility with quantization, which is another promising direction for efficient LLM inference. We consider 8-bit channel-wise RTN, 4-bit AWQ, and 2/3-bit
QuIP#. The point of sharp perplexity degradation is similar across bit-widths, suggesting that errors from activation sparsity and quantization compound somewhat independently. Combining these techniques unlocks new regimes with respect to memory transferred to GPU registers, allowing for higher inference speed-up. This requires developing specialized sparse + quantized kernels, which we leave for future work.

Applications
The most immediate application of TEAL is accelerating inference in resource constrained edge settings. These settings are typically single batch, which is where TEAL realizes the most salient speed-up. We find that TEAL is performant at low batch sizes greater than 1 (albeit with less sparsity), but does not scale as well to higher batch sizes.
TEAL can also help inference providers! Together AI hosts over 100 leading open-source models across a large fleet of GPUs. There are often times where the active batch size across models is fairly low on any given instance and with improvements like TEAL, we are able to serve models more efficiently in this regime.