
The RedPajama project aims to create a set of leading open-source models and to rigorously understand the ingredients that yield good performance. In April we released the RedPajama base dataset based on the LLaMA paper, which has worked to kindle rapid innovation in open-source AI.
The 5 terabyte dataset has been downloaded thousands of times and used to train over 100 models!

We trained 3B and 7B models on the Summit supercomputer, in collaboration with AAI CERC lab at Université de Montréal, EleutherAI & LAION for compute time on Summit within the INCITE program award "Scalable Foundation Models for Transferable Generalist AI”.
Today we are excited to release the v1 versions of the RedPajama-INCITE family of models, including instruct-tuned and chat versions under the Apache 2.0 license.
- RedPajama-INCITE-7B-Instruct is the highest scoring open model on HELM benchmarks, making it ideal for a wide range of tasks. It outperforms LLaMA-7B and state-of-the-art open models such as Falcon-7B (Base and Instruct) and MPT-7B (Base and Instruct) on HELM by 2-9 points.
- RedPajama-INCITE-7B-Chat is available in OpenChatKit, including a training script for easily fine-tuning the model and is available to try now! The chat model is built on fully open-source data and does not use distilled data from closed models like OpenAI’s – ensuring it is clean for use in open or commercial applications.
- RedPajama-INCITE-7B-Base was trained on 1T tokens of the RedPajama-1T dataset and releases with 10 checkpoints from training and open data generation scripts allowing full reproducibility of the model. This model is 4 points behind LLaMA-7B, and 1.3 points behind Falcon-7B/MPT-7B on HELM.
- Moving forward with RedPajama2, we conducted detailed analyses on the differences between LLaMA and RedPajama base models to understand the source of these differences. We hypothesize the differences are in part due to FP16 training, which was the only precision available on Summit. The process of this analysis was also a great source of insights into how RedPajama2 can be made stronger through both data and training improvements.
Instruct model
RedPajama-INCITE-7B-Instruct is an instruction-tuned version of the base model optimized for few-shot performance by training on a diverse collection of NLP tasks from both P3 (BigScience) and Natural Instruction (AI2). The Instruct version shows excellent performance on few-shot tasks, outperforming leading open models of similar sizes including Llama-7B, Falcon-7B (both base and instruct version), and MPT-7B (both base and instruct version) on HELM. RedPajama-INCITE-7B-Instruct appears to be the best open instruct model at this scale, as shown in the results below:
HELM benchmark results:
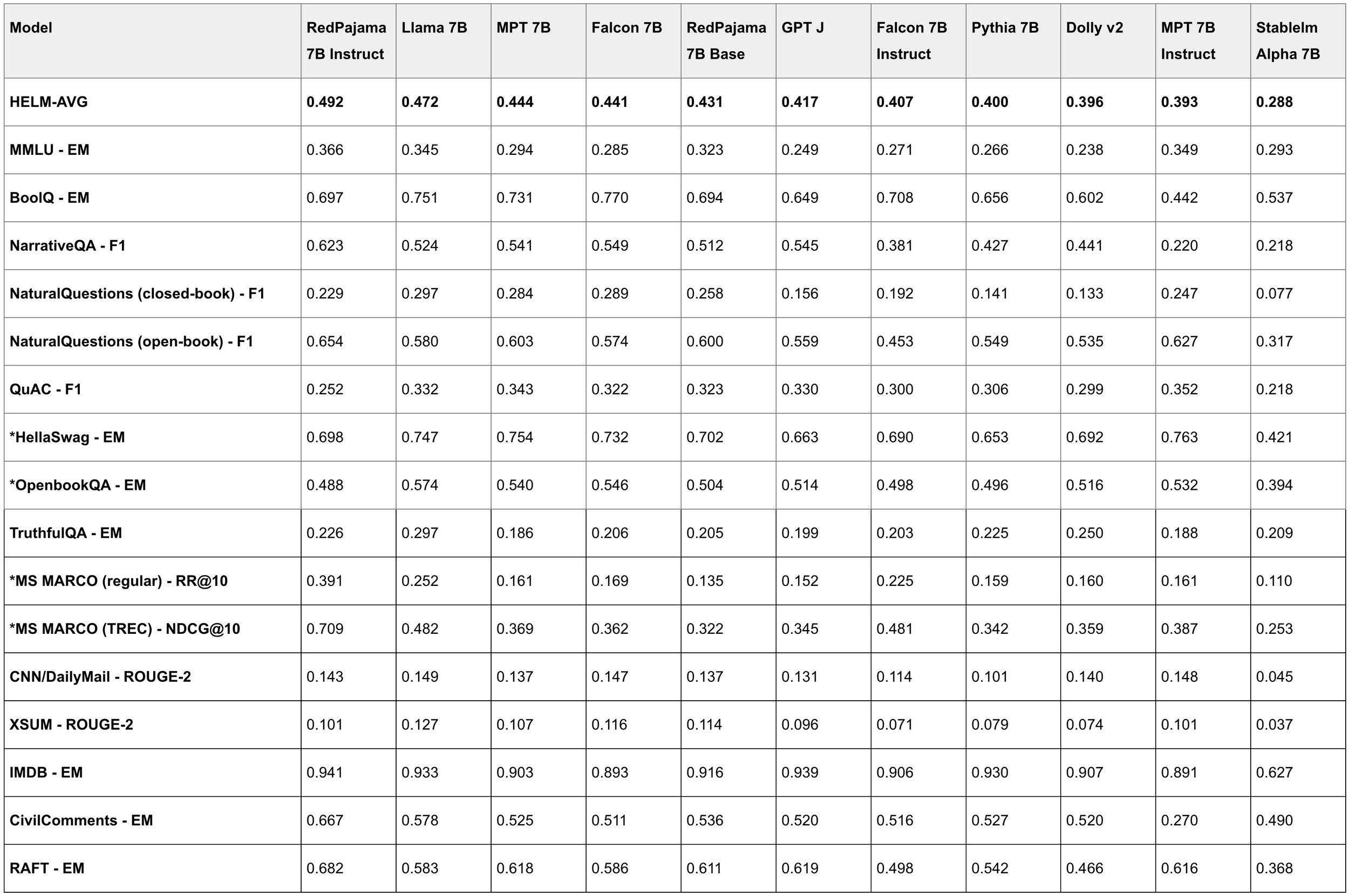
When constructing the Instruct dataset, we selected a diverse collection of NLP tasks from both P3 (BigScience) and Natural Instruction (AI2), and conducted aggressive decontamination against HELM, in two steps: (1) We first conducted semantic search using each validation example in HELM as the query and got top-100 similar instances from the Instruct data set and checked tasks that have any returned instances overlapping (using 10-Gram) with the validation example. We removed the entire task if the returned instance and the validation example correspond to the same task (in this step, we kept the task in the case that the returned instance happened to use the same Wikipedia article as the validation example, but asks different questions); (2) We then removed all instances that have any 10-Gram overlap with any HELM validation example. In total, we filtered out 137 tasks and 5.2M instances (out of 1069 tasks and 93.3M instances). The decontaminated Instruct dataset is available at RedPajama-Data-Instruct.
Chat model
RedPajama-INCITE-7B-Chat is an instruction-tuned version of the base model optimized for chat by training on open instruction data (Dolly2 and OASST), ensuring it is clean for use in open or commercial applications, like all models in the RedPajama-INCITE family.
We have added the chat model to OpenChatKit, which provides functionalities to further fine-tune the chat model and customize it for a specific application. You can play with it in our HuggingFace space.
We are also working with the open-source community to make RedPajama-INCITE-7B-Chat available to use on as wide a variety of hardware as possible. It is currently available to run on CPUs using RedPajama.cpp, a fork of the excellent llama.cpp. Stay tuned for updates as we work with projects like MLC LLM, which currently supports the 3B version of RedPajama, to also get the 7B version running on mobile phones, raspberry pi, and more!
Base model
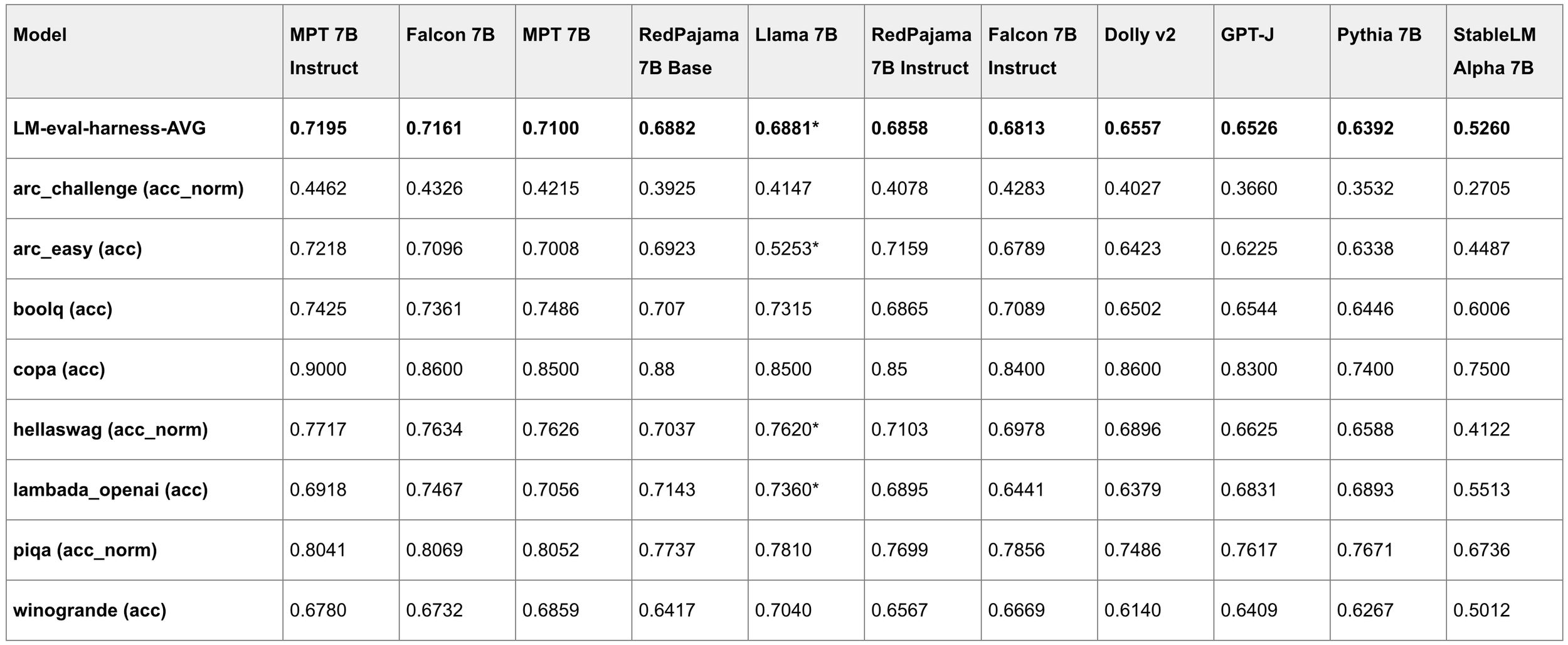
RedPajama-INCITE-7B-Base is trained on the RedPajama dataset, with the same architecture as the popular Pythia model suite. It was trained on the Summit supercomputer with 3072 V100 GPUs with DeeperSpeed codebase developed by EleutherAI. As a base model, RedPajama-INCITE-7B-Base was trained over 1T tokens. The base model is slightly (1.3 point) behind Falcon-7B on HELM. We further break down the tasks and see that it lags behind only on tasks that require using logprob, which compute the difference between the probabilities of right and wrong answers. However, the model achieves comparable average HELM scores on tasks that directly generate answers and measure quality. Note that all tests in LM harness use logprob, so we see similarly lower results on this benchmark.
We hypothesize this was partly due to training with FP16, which does not allow us to use larger learning rate as in projects such as OpenLlama. FP16 was the highest precision possible to train with on V100 GPUs, therefore for future training we plan to use higher precision.
LM Harness Results:
“The goal of the RedPajama effort is not only to produce a state-of-the-art open model, but also to make the whole process of building such a model fully reproducible, including a fully open dataset, the creation recipe, and the training process.”
As part of this goal, we are releasing 10 intermediate checkpoints from the training process. You can access the checkpoints on RedPajama-INCITE-7B-Base. Moreover, all details of the training process are also open. If you have any questions, please join our Discord server!
Plans for RedPajama2
Since the release of RedPajama, we are excited to see the progress that the community made towards building better open models. Taking the feedback we got over the last month, we are currently working towards a new version of RedPajama, RedPajama2, targeting 2-3T tokens. In this new version, we are excited to make several improvements on the data side:
- Understand in a principled way how to balance data mixture over each data slice. We are excited to try out techniques like DoReMi to automatically learn a better data mixture.
- Include complementary slices from Pile v1 (from Eleuther.ai), Pile v2 (from CarperAI), and other data sources to enrich the diversity and size of the current dataset.
- Process an even larger portion of CommonCrawl.
- Explore further data deduplication strategies beyond the approaches in the LLaMA paper.
- Include at least 150B more code tokens in the mixture to help improve quality on coding and reasoning tasks.
On the model side, we will start a new training run with higher precision, continue to explore larger models, and incorporate suggestions from community feedback. Come provide suggestions on our Discord server and help us make future open-source models even better!
Acknowledgements
The training of the first collection of RedPajama-INCITE models is performed on 3,072 V100 GPUs provided as part of the INCITE compute grant on Summit supercomputer at the Oak Ridge Leadership Computing Facility (OLCF). This grant was awarded to AAI CERC lab at Université de Montréal, LAION and EleutherAI in fall 2022 for their collaborative project on Scalable Foundation Models for Transferrable Generalist AI.
We are thankful to all the project team members helping to build the RedPajama dataset and supporting training, including Ontocord.ai, ETH DS3Lab, AAI CERC Lab at the Université de Montréal, Stanford Center for Research on Foundation Models (CRFM), Stanford Hazy Research research group, LAION and EleutherAI. We are grateful to Quentin Anthony (EleutherAI and INCITE project team) for porting DeeperSpeed and the GPT-NeoX training framework to Summit, and assisting with distributed training setup.
We are also appreciative to the work done by the growing open-source AI community that made this project possible. That includes:
- Meta AI — Their inspiring work on LLaMA shows a concrete path towards building strong language models, and it is the original source for our dataset replication.
- EleutherAI — This project is built on the backs of the great team at EleutherAI — including the source code they provided for training GPT-NeoX.
- INCITE project team — Their work on GPT-NeoX adaptation to Summit during early 2023 enabled distributed training that scaled efficiently to thousands of Summit GPUs, and ensured smooth training of the models.
- This research used resources of the Oak Ridge Leadership Computing Facility (OLCF), which is a DOE Office of Science User Facility supported under Contract DE-AC05-00OR22725. We are grateful for the invaluable support provided to us by the OLCF leadership and by the OLCF liaison for the INCITE project.