

Together AI provides the fastest cloud platform for building and running generative AI. Today we are launching the Together Embeddings endpoint. As part of a series of blog posts about the Together Embeddings endpoint release, we are excited to announce that you can build your own powerful RAG-based application right from the Together platform with Langchain.
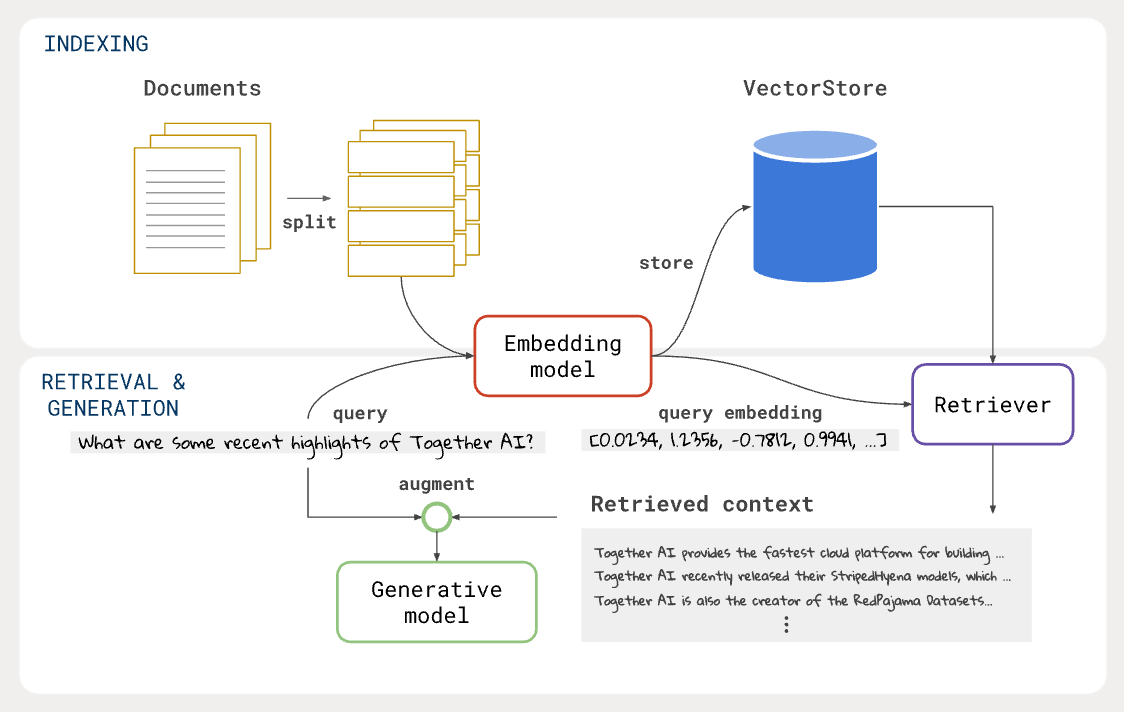
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) (original paper, Lewis et al.), leverages both generative models and retrieval models for knowledge-intensive tasks. It improves Generative AI applications by providing up-to-date information and domain-specific data from external data sources during response generation, reducing the risk of hallucinations and significantly improving performance and accuracy.
Building a RAG system can be cost and data efficient without requiring technical expertise to train a model while keeping the other advantages mentioned above. Note that you can still fine-tune an embedding or generative model to improve the quality of your RAG solution even further! Check out Together fine-tuning API to start.
Quickstart
To build RAG, you first need to create a vector store by indexing your source documents using an embedding model of your choice. LangChain libraries provide necessary tools for loading documents, splitting documents to small chunks that fit the context window of the embedding model you select, and storing their embeddings to a vector store. LangChain supports numerous vector stores. See the complete list of supported vector stores here. After you have your vector store ready, you will retrieve relevant data examples to your query using the same embedding model you used to create the vector store and Retriever. Finally, augment the retrieved information to your prompt, and obtain the final output from a generative model.
Below you will find an example of how you can incorporate latest knowledge into your RAG application using the Together API and Langchain so that a generative model can respond with the correct information.
First, install the following packages:
pip install -U langchain-together langchain-core langchain-community faiss-cpu tiktoken
Set the environment variables for the API keys. You can find the Together API key under the settings tab in Together Playground.
import getpass
import os
os.environ["TOGETHER_API_KEY"] = getpass.getpass()
# (optional) LangSmith to inspect inside your chain or agent.
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Now we will provide some recent information about Together AI and ask the model "What are some recent highlights of Together AI?"
from operator import itemgetter
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_together import TogetherEmbeddings
from langchain_community.llms import Together
vectorstore = FAISS.from_texts(
["Together AI provides the fastest cloud platform for building and running generative AI.",
"Together AI recently released their StripedHyena models, which is the first alternative model competitive with the best open-source Transformers in short and long-context evaluations.",
"Together AI is also the creator of the RedPajama Datasets. RedPajama-Data-v2 is an open dataset with 30 trillion tokens from 84 CommonCrawl dumps.",
"Together AI recently raised $102.5M in a Series A financing to build the future of AI."],
TogetherEmbeddings(model="togethercomputer/m2-bert-80M-8k-retrieval")
)
retriever = vectorstore.as_retriever()
model = Together(
model="mistralai/Mixtral-8x7B-Instruct-v0.1",
temperature=0.7,
max_tokens=128,
top_k=50,
# together_api_key="..."
)
# Provide a template following the LLM's original chat template.
template = """<s>[INST] Answer the question in a simple sentence based only on the following context:
{context}
Question: {question} [/INST]
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
input_query = "What are some recent highlights of Together AI?"
output = chain.invoke(input_query)
print(output)
>>> Together AI recently raised $102.5M in a Series A financing, created the RedPajama Datasets with an open dataset of 30 trillion tokens, and released their StripedHyena models, which are competitive in short and long-context evaluations.
The answer is correct and incorporates the context provided above! For a comparison, if you just use the mistralai/Mixtral-8x7B-Instruct-v0.1 model for the same question, "What are some recent highlights of Together AI?", the answer is mostly inaccurate and does not include recent information.
input_query_prompt = f"<s>[INST] {input_query} [/INST] "
print(model(input_query_prompt))
>>> 1. Launch of Together AI Platform: In 2021, Together AI launched its AI platform designed to help businesses build and deploy custom AI models quickly and easily. The platform provides a no-code interface, allowing users to create AI solutions without needing extensive technical knowledge.
2. Partnership with Cognizant: Together AI announced a partnership with Cognizant, a leading digital transformation services company, to offer AI-powered solutions to enterprises. The partnership aims to help businesses accelerate their digital transformation journey by providing them with AI solutions tailored to their specific needs.
3. Integration
Conclusion
The above example demonstrates how to build a RAG (Retrieval-Augmented Generation) system using Together and LangChain. By leveraging the power of these tools, you can create a generative model that provides accurate and up-to-date responses by retrieving relevant data from your vector store.
As you continue to explore the capabilities of Together APIs and LangChain, we encourage you to experiment with different use cases and applications. We are excited to see the innovative solutions that you will build using these powerful tools.
Thank you for following along with this tutorial!