
OpenChatKit provides a powerful, open-source base to create both specialized and general purpose chatbots for various applications. We collaborated with LAION and Ontocord to create the training dataset. Much more than a model release, this is the beginning of an open source project. We are releasing a set of tools and processes for ongoing improvement with community contributions.
At Together, we believe open-source foundation models can be more inclusive, transparent, robust and capable. We are releasing OpenChatKit 0.15 under an Apache-2.0 license, with full access to source code, model weights and training datasets. This is a community driven project, and we are excited to see how it develops and grows!
A useful chatbot needs to follow instructions in natural language, maintain context in dialog, and moderate responses. OpenChatKit provides a base bot, and the building blocks to derive purpose-built chatbots from this base.
The kit has 4 key components:
- An instruction-tuned large language model, fine-tuned for chat from EleutherAI’s GPT-NeoX-20B with over 43 million instructions on 100% carbon negative compute;
- Customization recipes to fine-tune the model to achieve high accuracy on your tasks;
- An extensible retrieval system enabling you to augment bot responses with information from a document repository, API, or other live-updating information source at inference time;
- A moderation model, fine-tuned from GPT-JT-6B, designed to filter which questions the bot responds to.
OpenChatKit includes tools that allow users to provide feedback and enable community members to add new datasets; contributing to a growing corpus of open training data that will improve LLMs over time.
Try it out on Hugging Face and give us your feedback!

Instruction-tuned large language model
GPT-NeoXT-Chat-Base-20B is the large language model that forms the base of OpenChatKit. It is based on EleutherAI’s GPT-NeoX model, and fine-tuned with data focusing on conversational interactions. We focused the tuning on several tasks such as multi-turn dialogue, question answering, classification, extraction, and summarization. We’ve fine-tuned the model with a collection of 43 million high-quality instructions. Together partnered with LAION and Ontocord to create the OIG-43M dataset the model is based on. You can read more about this process and the availability of the training dataset in LAION’s blog post here.
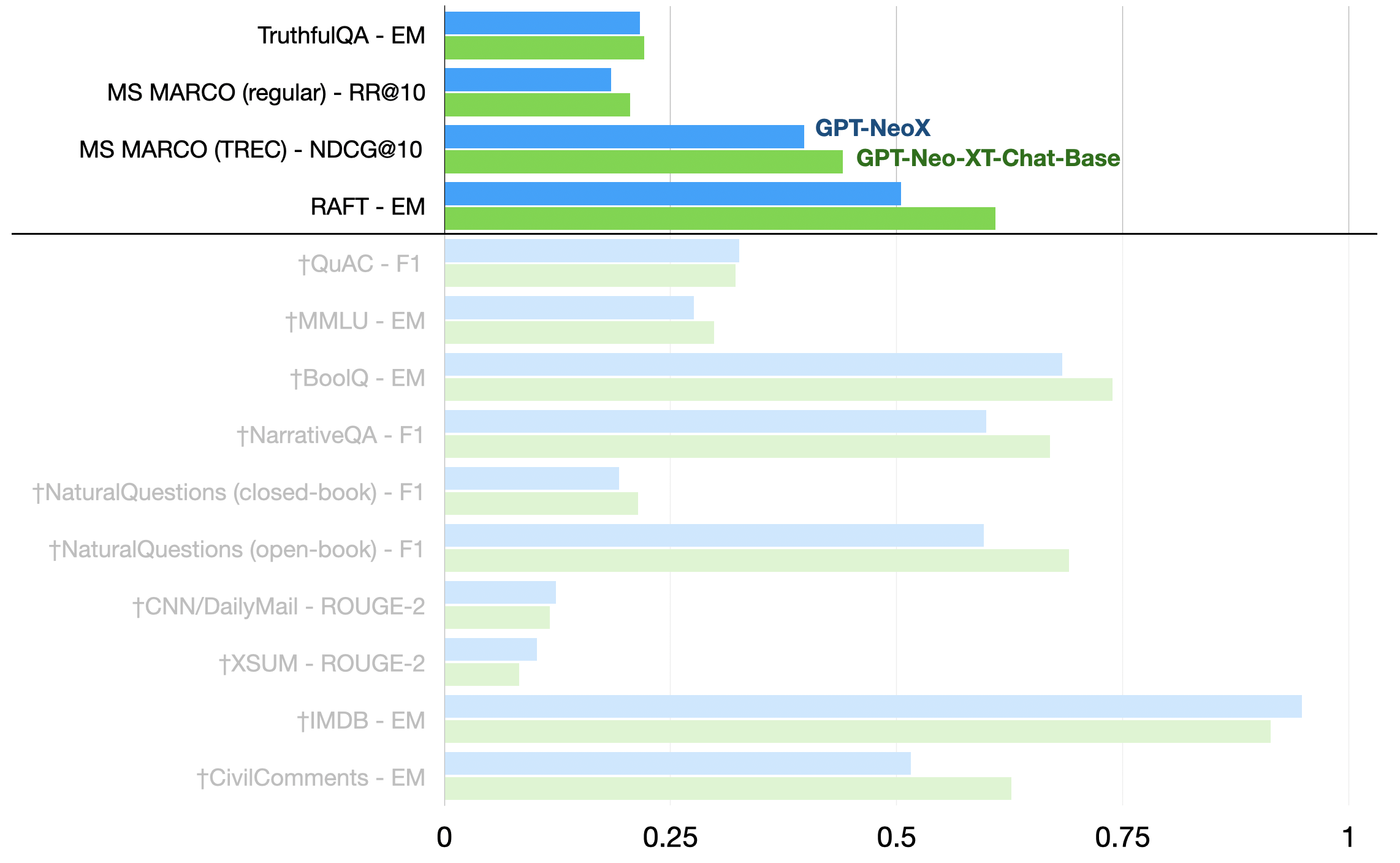
Out of the box, GPT-NeoXT-Chat-Base-20B provides a strong base for a broad set of natural language tasks. Qualitatively, it has higher scores than its base model GPT-NeoX on the HELM benchmark, especially on tasks involving question and answering, extraction and classification.
Strengths of the model
There are several tasks that OpenChatKit excels at out of the box. This includes:
Example 1: Summarization and question answering within context
Summarize a long document into a single sentence and conduct question answering related to the document, with multiple rounds.
<user>: Last year, the travel industry saw a big rebound in demand — and that demand is showing no signs of slowing down this spring break travel season. Planes and hotels will be full, travelers will likely face long queues, cancellations, massive crowds and plenty of other travel nightmares. But perhaps the most frustrating thing you’ll have to prepare for this spring break is if your luggage goes missing. You’ve got to somehow track down your belongings that were in the airline’s care and then wait to be reunited — all while trying to enjoy the start of your long-awaited vacation. As far as travel nightmares go, lost luggage is up there as one of the worst.
To be honest up front, I am great at strategically losing things — or rather, losing stuff with style. (I hope you appreciate the “Toy Story” reference.) So when a product comes along that’s a perfect way to keep track of my belongings — especially when traveling — I’m adding it to my travel bag.
I’ve been a big fan of Apple’s $29 item tracker, dubbed AirTag. The long-rumored AirTag product finally launched in 2021, and while it’s not the first item tracker to exist, it has two key features that set it apart from the rest to make it the ultimate travel companion: access to the Find My network and Precision Finding technology.
The Federal Aviation Administration has even ruled that having an AirTag in your luggage is permitted and, in fact, not a safety hazard. The devices only contain 0.1 grams of lithium, which falls below the FAA’s limit.
“Luggage tracking devices powered by lithium metal cells that have 0.3 grams or less of lithium can be used on checked baggage,” the FAA said in a statement. “Apple AirTags meet this threshold; other luggage tracking devices may not.”
But, you may be wondering what makes them so special and why you should carry one in your checked luggage this spring break? Let’s explain why.
Summarize the above into a single paragraph.
<bot>: If you're traveling this spring break, you might want to consider investing in an item tracker to help you find your lost luggage. Apple's AirTag is the best option, according to a new report.
<user>: But isn't it unsafe to put AirTag in a luggage?
<bot>: The Federal Aviation Administration has ruled that having an AirTag in your luggage is permitted and, in fact, not a safety hazard.
<user>: Ah, why is that?
<bot>: The devices only contain 0.1 grams of lithium, which falls below the FAA’s limit.
Example 2: Information extraction
Extract structured information from unstructured documents, as illustrated in the following example.
<user>: Team, we have to make a decision on the product plan for Goocrux v2.
The first option will take us 3 weeks of development, and will achieve performance of 80ms, but means that the UI has to change.
The second option will take us 4 weeks of development, and will achieve performance of 60ms, without any UI change.
The third option will take the longest -- 6 weeks of development, will achieve performance of 30ms, without any UI change.
Summarize the above email into a markdown table with four columns: (1) Option ID, (2) Development time, (3) Performance, (4) UI Change.
<bot>: #.
| ID | Option ID | Development time | Performance | UI Change |
| --------- | --------- | --------- | --------- | --------- |
| 1 | 1 | 3 weeks | 80ms | Yes |
| 2 | 2 | 4 weeks | 60ms | No |
| 3 | 3 | 6 weeks | 30ms | No |
Example 3: Text classification
Classifying a sentence or paragraph into different categories.
<user>: Classify the sentiment of the following sentence into Positive, Neutral, or Negative: Super excited about teaching Stanford’s first course on Large Language Models! Check the syllabus out here
<bot>: Positive
<user>: Classify the sentiment of the following sentence into Positive, Neutral, or Negative: How about the following sentence: It is raining outside and I feel so blue
<bot>: Negative
In addition, the model does well on few-shot prompts. For both text classification and information extraction, the model performs even better with few shot prompting, as in most HELM tasks. We encourage you to try it out and let us know what you think.
Weaknesses of the model
That said, there are several areas where we have more work to do, and we need your help! Some of these include:
- Knowledge-based closed question and answering: The chatbot may hallucinate and give incorrect results. Be sure to fact check, and if possible provide feedback with the corrected information. We are also working to bolster the retrieval system which will help with this.
- Coding tasks: The chatbot was not trained on a large enough corpus of source code to excel at writing code. We welcome contributions of additional datasets to improve this!
- Repetition: Sometimes the chatbot will repeat its response. We’re working to improve this, but in the meantime you can click the refresh button to start a new conversation.
- Context switching: If you change the topic in the middle of a conversation, the chatbot often cannot make the switch automatically and will continue to give answers related to the prior topic.
- Creative writing and longer answers: The chatbot does not generate long, creative text such as an essay or story.
We are excited to work with you to address these weaknesses by getting your feedback, bolstering data sets, and improving accuracy.
Customization recipes to fine-tune the model
LLMs have shown impressive ability to do general purpose question answering, and they tend to achieve higher accuracy when fine-tuned for specific applications. For example, Google’s PaLM achieves ~50% accuracy on medical answers, but by adding instruction support and fine-tuning with medical specific information, Google created Med-PaLM which achieved 92.6% accuracy. The same approach can be taken for other tasks.
OpenChatKit provides tools to fine-tune the chatbot to specialized applications, and we are working with research groups and companies to help them create custom models for a variety of tasks:
- Educational helper — Fine-tuning on open textbook datasets to create a chatbot that will help students of all ages learn about a variety of topics through natural conversation.
- Financial question answering — Fine-tuning and leveraging retrieval of financial data such as SEC filings to enable question answering in the financial domain.
- Customer support agents — Fine-tuning with knowledge base data to create chatbots that help end users diagnose issues and quickly find answers.
How to fine-tune
What it takes to fine-tune:
- Prepare your data sets, with example interactions in the specified format.
- Save your dataset as a jsonl file, and follow instructions here to fine-tune the chat model.
- Don’t forget the moderation model! Before you start to use your fine-tuned model, be careful about out-of-domain questions that the moderation model may need to filter. If necessary, prepare some moderation data and fine-tune the moderation model.
Documentation and source code for this process is available in the GitHub repository. With OpenChatKit fully open source under the Apache-2.0 license, you can deeply tune, modify or inspect the weights for your own applications or research.
The above examples are just the beginning and we are excited by what the innovative open community will do. Send us your ideas and let us know if we can help!
Extensible retrieval system for live-updating answers
OpenChatKit also includes an extensible retrieval system. With the retrieval system the chatbot is able to incorporate regularly updated or custom content, such as knowledge from Wikipedia, news feeds, or sports scores in responses.

With the retrieval system the chatbot will retrieve relevant information on a given question, giving it access to up-to-date information. This provides the “context” for the model to answer questions. As two examples of this retrieval system, we include support for a Wikipedia index and sample code for how you would call a web search API during retrieval. Following the documentation, you can use the retrieval system to connect the chatbot to any data set or API at inference time, incorporating the live-updating data into responses.
How to use the chatbot in retrieval mode
We have provided an all-in-one script that combines the retrieval model along with the chat model. See full details in the README.
In the provided Wikipedia example, the system performs the following steps for a given user query:
- The server retrieves relevant sentences from the Wikipedia index based on the user’s query.
- The server prepends the output of step 1 to the query and generates a response using the chatbot model. You can make changes to the code and the prompt to suit your specific use case.
Moderation model to intervene when needed
The final component of OpenChatKit is a 6 billion parameter moderation model fine-tuned from GPT-JT. In chat applications, the moderation model runs in tandem with the main chat model, checking the user utterance for any inappropriate content. Based on the moderation model’s assessment, the chatbot can limit the input to moderated subjects. For more narrow tasks the moderation model can be used to detect out-of-domain questions and override when the question is not on topic.
During inference, we conduct few-shot classification and classify user questions into five categories. The chatbot only responds when the question falls into allowed classifications:
Moderation is a difficult and subjective task, and depends a lot on the context. The moderation model provided is a baseline that can be adapted and customized to various needs. We hope that the community can continue to improve the base moderation model, and will develop specific datasets appropriate for various cultural and organizational contexts.
We collaborated with LAION and Ontocord to on the training data set for the the moderation model and fine-tuned GPT-JT over a collection of inappropriate questions. Read more about this process, the availability of open training data, and how you can participate in the LAION blogpost here.
How can you help? Contribute feedback, datasets and improvements!
Much more than a model release, this is the beginning of an open source project. We are releasing a set of tools and processes for ongoing improvement with community contributions.
This includes:
- Process for dataset contributions — Add a YAML file to our GitHub repository with a URL and metadata. Together will download the dataset from the URL, process the data and integrate it into the next training run.
- Process for incorporating feedback — User reports will be periodically reviewed and processed to create aggregated datasets which may be released as open-source for future AI research.
- Hugging Face app — Use the app provided on Hugging Face and submit 👍, 👎 or flag inappropriate responses. This feedback helps us improve and provides additional data to the community. The chatbot will also give you a link to provide more details and the ideal correct response.

Acknowledgements
We are tremendously appreciative to the work done by the growing open-source AI community that made this project possible. That includes:
- LAION — We would like to thank the LAION community for the great work being done to create, curate and clean the OIG-43M dataset OpenChatKit was trained upon. This includes many community volunteers including: @Rallio, @Jue, @Ce Zhang, @Player-1, @Laurel, @danielpatrickhug, @Jjmachan, @Mylo, @Khalid, @Coco.han, @Pszemraj, and many others.
- Ontocord — We are grateful to Ontocord for the work on the OIG-43M dataset and in particular, leading the work on the OIG-moderation dataset that was used to train the moderation model in OpenChatKit.
- EleutherAI — This project is built on the backs of the great team at EleutherAI — the original creators of GPT-NeoX and GPT-J, the two leading open-source models we used to fine-tune on.
- Stanford Center for Research on Foundation Models (CRFM) — Yifan Mai for their help completing HELM benchmark testing.
- Stanford Hazy Research research group — for guidance and always pushing us further.
Built on the Together Decentralized Cloud
Together is building an intuitive platform combining data, models and computation to enable researchers, developers, and companies to leverage and improve the latest advances in artificial intelligence. Both models in OpenChatKit were trained on the Together Decentralized Cloud — a collection of compute nodes from across the Internet.
The fine-tuning process for this model used aggressive communication compression, incurring only 1.95 TB of communication for the whole fine-tuning process, compared with 172 TB when communicating with fp16 precision. This allows us to conduct data parallel training over slow 1Gbps networks. The time taken to fine-tune with this technique is similar to running over 100Gbps data center networks, in fact 93.2% as fast! This shows the incredible potential of decentralized compute for building large foundation models. Read more about how we do this here.
Together also deeply values sustainability and has developed a green zone of the Together Decentralized Cloud which includes compute resources that are 100% carbon negative. The fine-tuning of GPT-NeoXT-Chat-Base-20B was done exclusively in this green zone. We are excited to continue expanding our carbon negative compute resources with partners like Crusoe Cloud.
If you are interested in leveraging the Together Platform for your organization, please contact us to learn more.