
AI shouldn’t be static — it should evolve alongside your application and its users. That’s the core idea of the new Together Fine-Tuning Platform: it enables you to easily refine and improve the language models you use over time, based on user preferences and fresh data.
With support for preference optimization and continued training, businesses can now go beyond one-time LLM customization. You can fine-tune open-weight models like Llama or Gemma to reflect your users’ expectations, capture your domain specifics, and continuously adapt your models as your app evolves. Combined with a new web UI and full control over your model weights, the Together AI platform makes it easier than ever to build AI systems that learn and grow according to your needs.
Fine-tune models, directly from your web browser
Previously, getting started with fine-tuning on Together AI required installing our Python SDK or making calls to an API — both options involving the setup of extra tools. To make fine-tuning more accessible for developers, we have created a brand new UI, offering the ability to start fine-tuning runs directly from the browser. It allows you to upload datasets, specify the training parameters, and see all of your experiments at a glance.
{{custom-cta-1}}
Direct Preference Optimization
While regular supervised fine-tuning is an essential step in adjusting the LLM behavior for downstream tasks, it lacks flexibility and nuance required to fit the target applications in the best way possible. To address this problem, the research community has proposed training on preference data: instead of simply imitating the given responses, the model observes both preferred and undesired replies to user messages, learning to steer towards the former and away from the latter.
To give AI developers the ability to build the best models for their applications, we have added Direct Preference Optimization (or DPO), which is a stable and effective way of training LLMs on preference data that does not involve an additional reward model. To get started with DPO on our platform, upload a dataset with preference data and specify --training-method="dpo" when creating a fine-tuning job.
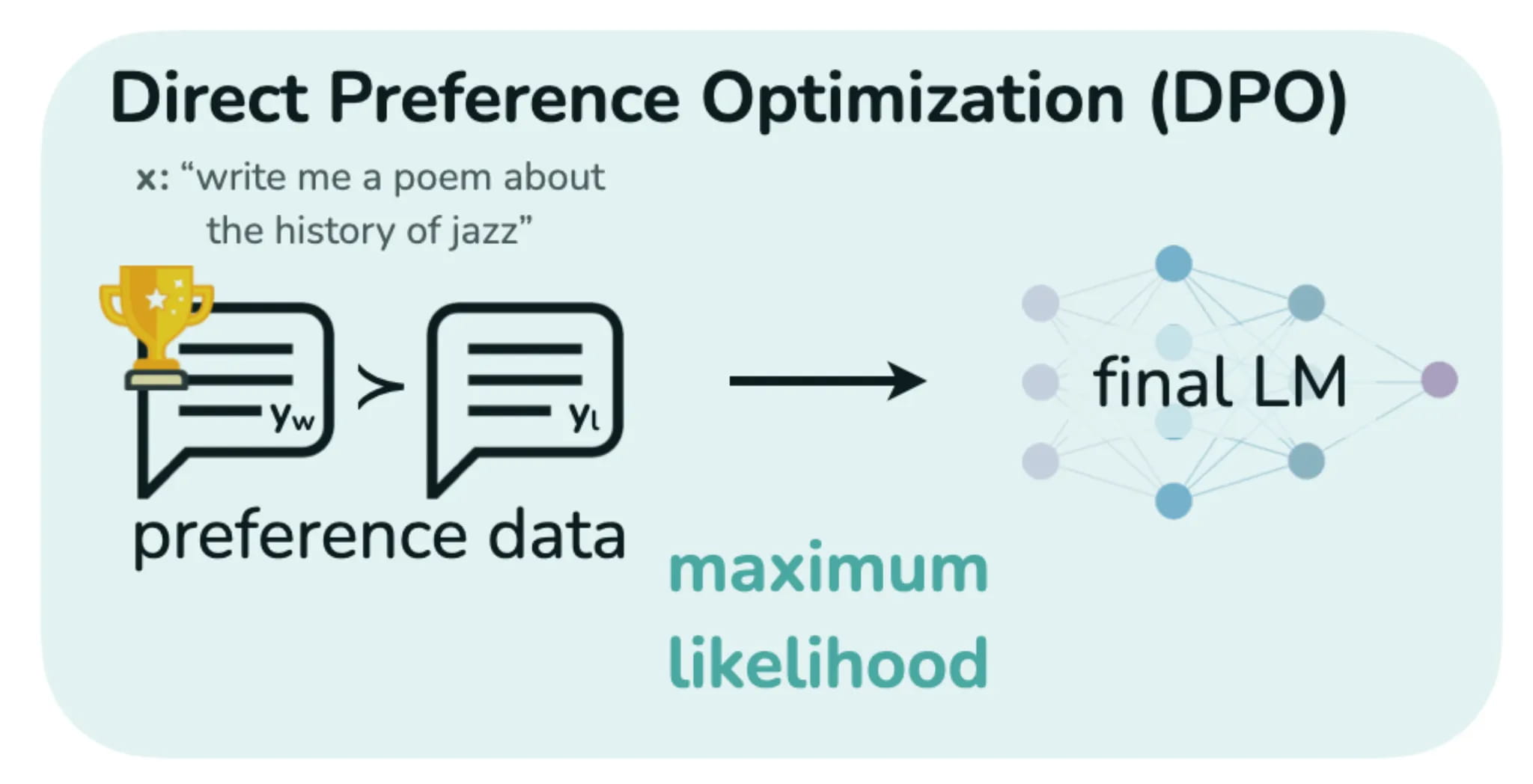
To learn more about the inner workings of DPO and its benefits for language model adaptation, read our deep-dive blog post. It also provides a cookbook that demonstrates how you can run experiments with Direct Preference Optimization using our Python SDK.
Continued training
Nowadays, the best recipes for model post-training often include multiple stages that use different training datasets or hyperparameters. This is especially important when using methods like DPO, as the preference optimization step hugely benefits from instruction tuning beforehand. Furthermore, regularly updating your existing model with new data is often highly beneficial, allowing you to easily adapt to latest trends in how users interact with your LLM application.
To support this setup, we have added the ability to start fine-tuning jobs from the results of your previous runs on Together AI. To do this, simply add the --from-checkpoint flag when creating a job and specify the job ID that you want to start from; see our docs for the full description of the feature.
Our customers are already seeing the benefits of continued fine-tuning. Protege AI is building a platform for marketing compliance with AI. As early users of continued fine-tuning, they have launched hyper-personalized models for their enterprise clients that update regularly based on their customer’s preferences.
"After thoroughly evaluating multiple LLM infrastructure providers, we’re thrilled to be partnering with Together for fine-tuning. The new resuming from a checkpoint functionality combined with LoRA serving has enabled our customers to deeply tune our foundational model, ShieldLlama, for their enterprise’s precise risk posture. The level of accuracy would never be possible with vanilla open source or prompt engineering.
— Alex Chung, Founder at Protege AI
To learn how to use continued fine-tuning in practice, read our deep-dive blog post, which presents several use cases for this feature, or jump straight to our example notebook.
Fine-tuning improvements
Our platform now supports training the latest top-ranking open models, such as Google’s Gemma 3 and versions of distilled DeepSeek-R1 (from DeepSeek-R1-Distill-Qwen-1.5B to DeepSeek-R1-Distill-Llama-70B). In the coming weeks, we are also planning to enable training of several very large models including Llama 4 and DeepSeek R1 — stay tuned for updates!
We have also added two features to help you train the best-quality models for your tasks. To train the models only on the responses you want, you can now specify message weights when launching a fine-tuning job with conversational data. This can help you indicate that the model should not learn to generate certain messages from conversations, from example, irrelevant or lower-quality assistant responses. The LLM will still observe them in the context, but will not be penalized for poorly performing on predicting messages with a weight of 0.
In addition, we have extended the choice of learning rate schedulers with the cosine LR scheduler, used to train many leading LLMs: to specify it, use --lr-scheduler-type cosine when starting a fine-tuning job. As with the linear scheduler, you can set the fraction of training steps to be used for the warmup, and you can also specify the number of cosine scheduler cycles.
Lastly, we have optimized our data preprocessing logic, which now handles large training datasets more efficiently. In our internal large-scale training runs, it resulted in substantial data processing speedups, leading to end-to-end training speedups of up to 32% (and 17% for regular-sized fine-tuning jobs). This improvement has been in production since March, speeding up all fine-tuning jobs — at no extra cost to you and with no impact on training quality.
Try our end-to-end fine-tuning notebook to get started!
Pricing update
At Together AI, we firmly believe that every developer should be able to integrate fine-tuned AI models into their applications. To reflect this, we are changing our pricing for the fine-tuning service, making the training costs lower and more transparent. See the table below for our updated pricing:
The token counts for pricing calculation above include both training and validation data. Using Direct Preference Optimization increases the price by 2.5x due to its higher compute costs. Furthermore, there is now no minimum price for fine-tuning: if you are only exploring the potential of customizing Large Language Models, you can now start with smaller datasets and pay only for what you use. See the full pricing table here.
Own & evolve your AI
This update marks a huge leap forward in empowering developers and businesses to continuously evolve their models with full ownership. With the new web UI for starting and monitoring fine-tuning jobs, it is now easier than ever to get started with customizing your models. Once your model is created, you can immediately deploy it for inference via Together — or download the resulting checkpoint and use it locally, regardless of the training setup.
At Together AI, we're building the most comprehensive, full-featured and price-competitive Fine-Tuning Platform. Soon, we’re planning to expand it with larger-scale training capabilities, additional components for end-to-end model development, and a wider range of models and features based on your feedback.
Join our webinar on May 1st, where we will showcase the new fine-tuning platform and our latest training features. If you want to learn more about fine-tuning for your tasks, have feedback about our platform, or want to become an early-access user for upcoming features, reach out on Discord or contact our team.
Customize leading models with your own data using our new web interface.