
We're excited to announce that the Together Fine-Tuning Platform now supports Direct Preference Optimization (DPO)! This technique allows developers to align language models with human preferences creating more helpful, accurate, and tailored AI assistants. In this deep-dive blogpost, we provide details of what DPO is, how it works, when to use it and code examples. If you'd like to jump straight into code have a look at our code notebook.
Tuning LLMs on Preference Data
Modern language model development typically follows a three-stage process:
- Pre-training on internet-scale data to build a foundation model with broad knowledge
- Supervised fine-tuning (SFT) on specific high-quality examples to adapt a model to a particular knowledge domain or task
- Preference-based learning to refine the model based on human preferences

This final stage, preference learning, is where DPO comes in as an alternative to Reinforcement Learning from Human Feedback (RLHF). It ensures that models not only perform tasks correctly but do so in ways that users prefer. It also allows users to teach the model nuances of a particular use case by showing examples of what is expected and what the model should avoid. Business use cases where you might employ DPO are to improve:
- Helpfulness
- Tone
- Truthfulness
- Harmlessness
- Instruction-following
Preference tuning shapes the model's generation quality and alignment with human and business values.
What is Direct Preference Optimization?
DPO is a method for aligning language models with human preferences without using reinforcement learning (RL). Unlike traditional approaches, DPO allows you to train language models directly on preference data consisting of:
- A prompt or instruction
- A preferred (chosen) response
- An unpreferred (rejected) response
For example, you might have a dataset entry like this:
DPO adjusts the model weights to increase the probability of generating responses like the preferred one while decreasing the probability of generating responses like the rejected one. It essentially teaches the model to distinguish between better and worse responses for a given prompt.
To understand how DPO works, let's use a cooking analogy. Imagine you're a chef with a cookbook (your initial model). The DPO loss function teaches you to adjust your recipes in a specific way: increase the likelihood of making dishes customers loved compared to your original recipes, and decrease the likelihood of making dishes customers disliked compared to how you made them initially. Rather than simply maximizing preferred dishes and minimizing disliked ones in absolute terms, this relative approach ensures you don't completely abandon your fundamental cooking techniques while developing improvements.
The β parameter acts like a constraint controlling how much you can experiment: a higher value forces you to stay closer to your original recipes, while a lower value allows for more significant departures from your cookbook. You're not learning from a more experienced chef; instead, you're using your initial recipes as a reference point to prevent you from drifting too far from what you already know how to cook.
DPO vs. RLHF
Companies have used Reinforcement RLHF to align language models with human preferences. While both DPO and RLHF aim to achieve the same goal, they take fundamentally different approaches:
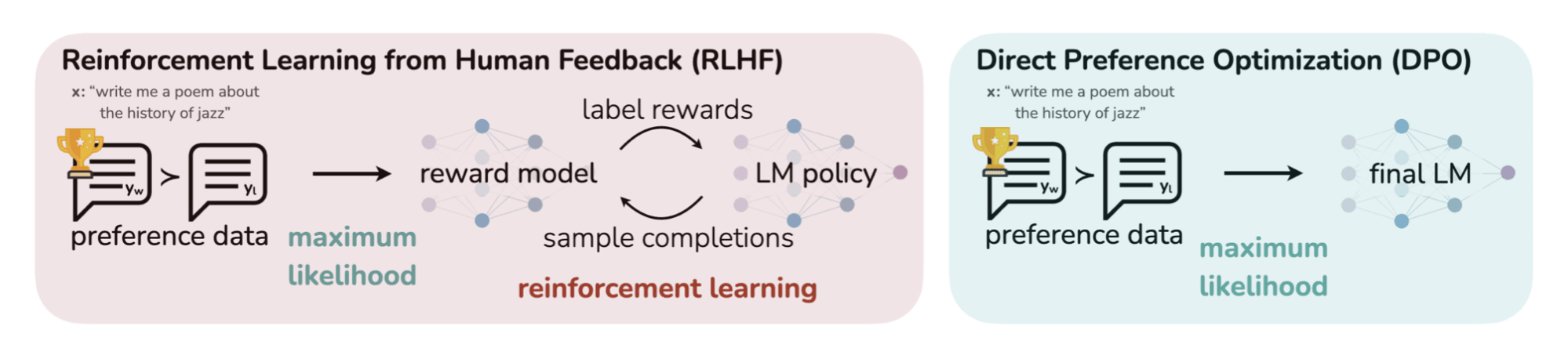
RLHF: The Traditional Approach
RLHF is a complex, multi-stage process:
- Train a reward model on human preference data
- Use reinforcement learning (typically PPO) to optimize the policy model against the reward model
- Generate online samples during training, slowing down the process
- Manage the complexity of RL training, including value functions, policy gradients, and hyperparameter tuning
DPO: The Direct Approach
DPO simplifies this process dramatically:
- Train directly on preference data without an intermediate reward model
- Use a simple loss function that maximizes the margin between preferred and rejected responses
- No need for online sampling during training, making it more efficient
- Simpler implementation and hyperparameter tuning
In contrast to DPO, going back to our analogy of cookbook improvement, RLHF would be like hiring a food critic (reward model) to taste and rate your dishes, then having you repeatedly cook different variations and adjust your recipes based on the critic's ongoing feedback - a more complex process requiring the intermediate step of training the critic to recognize good food before you can improve your cooking. While DPO directly uses customer preferences to modify your existing recipes, RLHF introduces this third-party critic who guides your experimentation through ongoing taste tests and ratings.
Previous work has shown that DPO can match or exceed the performance of RLHF in many cases while being simpler to implement and more computationally efficient.
Stacking Methods: Combining SFT with Preference Fine-tuning
While DPO is powerful on its own, combining it with Supervised Fine-Tuning (SFT) creates an even more effective training pipeline. The recommended approach is to:
- First perform SFT on your dataset to teach the model the basic task structure and response format
- Then refine with DPO by continuing fine-tuning from your SFT checkpoint
This two-stage approach provides several key advantages:
- Better initial starting point: SFT helps the model understand the basic format and content of desired responses
- Significant quality improvements: SFT is particularly important when your training data differs from what the base model observed during pre-training
- More effective preference learning: A model already familiar with the task domain can better learn subtle preferences
- Faster convergence: The DPO phase can focus on preference refinement rather than learning task basics
To implement this approach, you can first concatenate the context with the preferred output for SFT, and then follow up with preference fine-tuning using pairs of preferred and non-preferred outputs.
This stacked approach, of SFT + DPO, yields superior results compared to using either method alone. The SFT phase ensures the model has the fundamental capabilities, while the DPO phase refines how those capabilities are expressed. Read our technical deep-dive on continual fine-tuning.
When to Use Direct Preference Optimization
DPO is ideal in scenarios where you have preference data that captures the nuances of what makes a good response better than an alternative. Here are some key situations where DPO shines:
1. When Prompting Isn't Sufficient
While prompts can guide model behavior, they take up tokens, incur costs with each call, and may be ignored. DPO provides a more robust solution by directly encoding preferences into the model weights.
2. When Humans Can Compare Better Than Create
It's often easier for humans to judge which of two responses is better than to craft the perfect response from scratch. DPO leverages this fact, making data collection more efficient.
3. When Making Controlled Improvements to Existing Models
DPO, especially with tuned β values, allows for more measured improvements to models that are already performing well but need refinement in specific areas.
Ideal Use-Cases for DPO
DPO excels in tasks with multiple valid approaches where quality judgments are nuanced:
DPO is not good for tasks with single correct answers, such as:
- Information extraction (NER, classification)
- Tool calling with limited variation
- Mathematical computation
- Tasks where there's an objectively correct answer
Getting Started with DPO on Together
We’ve prepared an code notebook for you to follow along. Below, we cover some important things to keep in mind when training a model using DPO.
Key Hyperparameters
While you still need to tune usual hyperparameters like learning rate, the most important parameter for DPO is --dpo-beta:
- This controls how much the model is allowed to deviate from its reference model during training
- Lower values (e.g., 0.1) allow more aggressive updates toward preferred responses
- Higher values keep the model closer to its reference behavior
- The default value is 0.1, but you can experiment with values between 0.05-0.5
Monitoring Training
When monitoring your DPO fine-tuning job, you'll see several metrics specific to preference optimization:
- Accuracy: The percentage of times the reward for the preferred response is greater than the reward for the non-preferred response
- KL Divergence: The divergence between the tuned model and the reference model
These metrics help you gauge how well your model is learning preferences while maintaining its core capabilities.
Sources
- https://www.tylerromero.com/posts/2024-04-dpo/
- https://simmering.dev/blog/llm-customization/
- https://iclr-blogposts.github.io/2024/blog/rlhf-without-rl/
- https://huggingface.co/blog/pref-tuning
- https://rlhfbook.com/c/12-direct-alignment.html
- https://arxiv.org/abs/2406.09279v1
- https://www.interconnects.ai/p/the-dpo-debate