
Generative AI has taken the world by storm, and its capabilities are only increasing. Venture capital funding for AI startups has more than doubled in 2023 and over 92% of Fortune 500 companies are integrating generative AI into their business processes. This has led to a skyrocketing demand for purpose-built, highly optimized training clusters, which are necessary to train gen AI models.
Together GPU Clusters, previously known as Together Compute, offers purpose-built dedicated GPU training clusters. It delivers unparalleled model training speeds, amazing cost efficiency and expert support. This product has seen incredible adoption in the first 4 months since its launch. Startups and enterprises appreciate not only the cutting edge-training performance, but they also appreciate that our clusters meet the highest standards for hardware, flexibility, and support:
- Cutting-edge hardware — high-end NVIDIA GPUs including H100, A100 GPUs with fast Infiniband networking.
- Together Training stack — our optimized training stack is ready to go on your cluster, so that you can focus on optimizing model quality instead of tweaking software setup.
- Flexible capacity — ability to rapidly grow capacity as your needs change, and schedule clusters only for the time needed.
- Top-tier support — confidence that you can get expert support quickly regardless of the issue, whether it is a systems concern or an AI training issue.
Together GPU Clusters provides the perfect solution to meet these key needs.
Cutting edge hardware
Together GPU Clusters are built on state-of-the-art NVIDIA GPUs and networking. The majority of customers are on H100 SXM5 GPUs with 3200 Gbps Infiniband networking or A100 SXM4 80GB GPUs with 1600 Gbps Infiniband networking. Clusters come with fast NVMe storage and options for expanding to high speed network attached storage.

Optimized software stack
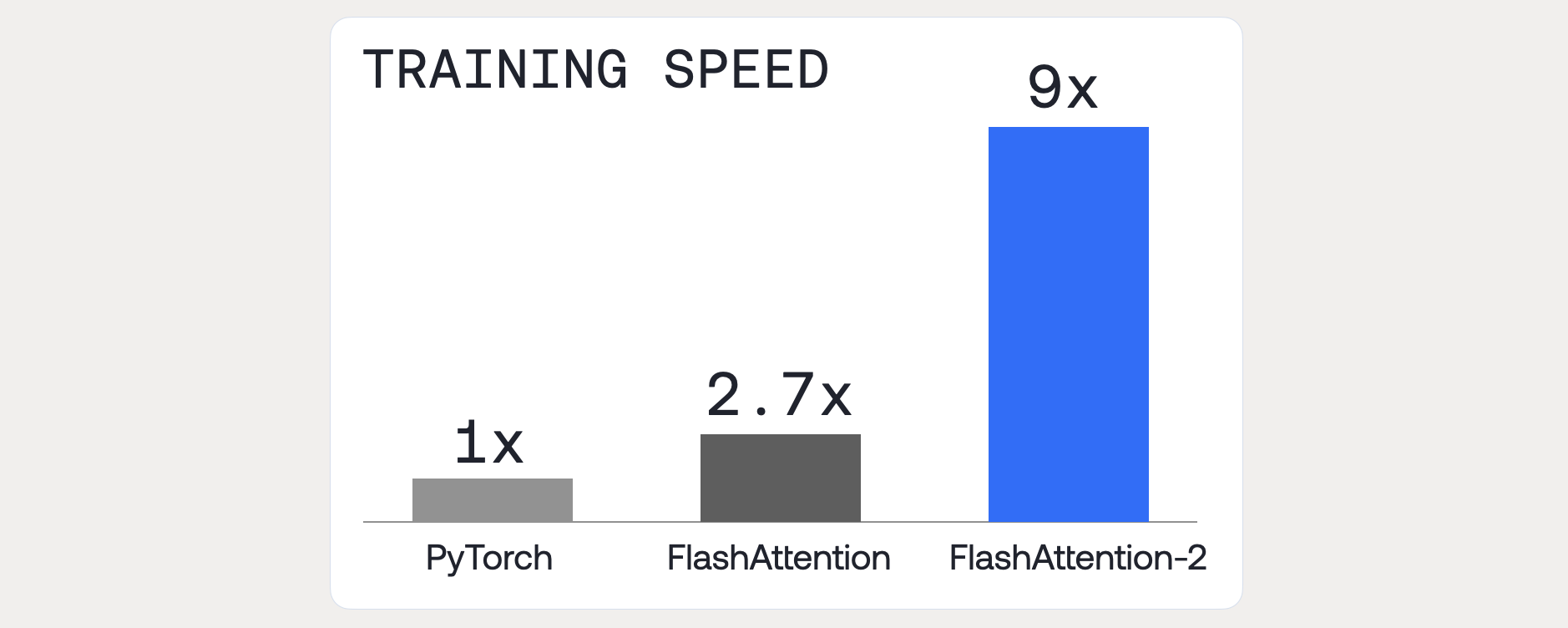
We created the Together Training stack to build our own models, like RedPajama. Over the past year, we have worked to make it up to 9x faster than training with a standard attention implementation in PyTorch, through meticulous optimizations. We are thrilled to make it available to you on all Together GPU Clusters.
- Train with the Together Training stack, delivering up to 9 times faster training speed with FlashAttention-2.
- Slurm configured out-of-the-box for distributed training and the option to use your own scheduler.
- Directly ssh into the cluster, download your dataset and you’re ready to go.
Flexible capacity
Together AI offers unparalleled flexibility to you on terms, so that you can allocate compute capacity to match your needs.
- Start with as little as 30 days — and expand at your own pace.
- Scale up or down as your needs change — from 16 GPUs to 2048 GPUS.
When training generative AI models, your compute needs will grow and shrink over time. Most AI teams are not looking for a constant set of hardware for two years straight. You require the highest capacity during training. After pre-training completes, compute needs reduce as you switch to fine-tuning iterations, RLHF, and final testing. Then, as the model is deployed into production,workloads change from training to inference and planning typically starts for the next big model build.
Top-tier support
Our expert AI team is committed to making every Together GPU Clusters customer successful. Our expert team will help unblock you, whether you have AI or system issues. Guaranteed uptime SLA and support is included with every cluster. Additional engineering services available whenever you need them.
Customer story: Pika Labs creates next-gen text-to-video models with Together GPU Clusters
Pika Labs, a video generation company founded by two Stanford PhD students, built its text-to-video model on Together GPU Clusters. As they got traction, Pika built new iterations of the model from scratch with Together GPU Clusters, and they scaled their inference volume as they grew to millions of videos generated per month.
“Together GPU Clusters provided a combination of amazing training performance, expert support, and the ability to scale to meet our rapid growth to help us serve our growing community of AI creators.”
— Demi Guo, CEO, Pika Labs
- $1.1 million saved over 5 months
- 4 hours time to training start
- 92,300 discord users
Customer story: NexusFlow uses Together GPU Clusters to build gen ai cybersecurity models
Nexusflow, a leader in generative AI solutions for cybersecurity, relies on Together GPU Clusters to build robust cybersecurity models as they democratize cyber intelligence with AI.
"In an industry where time and specialized capabilities mean the difference between vulnerability and security, Together GPU Clusters helped us scale quickly and cost-effectively. Their high-performance infra and top-notch support let us focus on building state-of-the-art solutions for cybersecurity."
— Jian Zhang, CTO of Nexusflow
- 40% cost savings per month
- <90 minutes onboarding time
- Zero downtime
Get started today
With growing capacity, we are ready to set you up with your Together GPU Cluster today. Contact us to learn more or reserve your cluster.

Audio Name
Audio Description
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, respond with less than 860 words. Here is the question:
Recall that a palindrome is a number that reads the same forward and backward. Find the greatest integer less than $1000$ that is a palindrome both when written in base ten and when written in base eight, such as $292 = 444_{\\text{eight}}.$
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, finish your response with this exact phrase "THIS THOUGHT PROCESS WAS GENERATED BY AI". No other reasoning words should follow this phrase. Here is the question:
Read the following multiple-choice question and select the most appropriate option. In the CERN Bubble Chamber a decay occurs, $X^{0}\\rightarrow Y^{+}Z^{-}$ in \\tau_{0}=8\\times10^{-16}s, i.e. the proper lifetime of X^{0}. What minimum resolution is needed to observe at least 30% of the decays? Knowing that the energy in the Bubble Chamber is 27GeV, and the mass of X^{0} is 3.41GeV.
- A. 2.08*1e-1 m
- B. 2.08*1e-9 m
- C. 2.08*1e-6 m
- D. 2.08*1e-3 m
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, your response should be wrapped in JSON format. You can use markdown ticks such as ```. Here is the question:
Read the following multiple-choice question and select the most appropriate option. Trees most likely change the environment in which they are located by
- A. releasing nitrogen in the soil.
- B. crowding out non-native species.
- C. adding carbon dioxide to the atmosphere.
- D. removing water from the soil and returning it to the atmosphere.
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, your response should be in English and in all capital letters. Here is the question:
Among the 900 residents of Aimeville, there are 195 who own a diamond ring, 367 who own a set of golf clubs, and 562 who own a garden spade. In addition, each of the 900 residents owns a bag of candy hearts. There are 437 residents who own exactly two of these things, and 234 residents who own exactly three of these things. Find the number of residents of Aimeville who own all four of these things.
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, refrain from the use of any commas. Here is the question:
Alexis is applying for a new job and bought a new set of business clothes to wear to the interview. She went to a department store with a budget of $200 and spent $30 on a button-up shirt, $46 on suit pants, $38 on a suit coat, $11 on socks, and $18 on a belt. She also purchased a pair of shoes, but lost the receipt for them. She has $16 left from her budget. How much did Alexis pay for the shoes?
Audio Name
Audio Description
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, respond with less than 860 words. Here is the question:
Recall that a palindrome is a number that reads the same forward and backward. Find the greatest integer less than $1000$ that is a palindrome both when written in base ten and when written in base eight, such as $292 = 444_{\\text{eight}}.$
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, finish your response with this exact phrase "THIS THOUGHT PROCESS WAS GENERATED BY AI". No other reasoning words should follow this phrase. Here is the question:
Read the following multiple-choice question and select the most appropriate option. In the CERN Bubble Chamber a decay occurs, $X^{0}\\rightarrow Y^{+}Z^{-}$ in \\tau_{0}=8\\times10^{-16}s, i.e. the proper lifetime of X^{0}. What minimum resolution is needed to observe at least 30% of the decays? Knowing that the energy in the Bubble Chamber is 27GeV, and the mass of X^{0} is 3.41GeV.
- A. 2.08*1e-1 m
- B. 2.08*1e-9 m
- C. 2.08*1e-6 m
- D. 2.08*1e-3 m
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, your response should be wrapped in JSON format. You can use markdown ticks such as ```. Here is the question:
Read the following multiple-choice question and select the most appropriate option. Trees most likely change the environment in which they are located by
- A. releasing nitrogen in the soil.
- B. crowding out non-native species.
- C. adding carbon dioxide to the atmosphere.
- D. removing water from the soil and returning it to the atmosphere.
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, your response should be in English and in all capital letters. Here is the question:
Among the 900 residents of Aimeville, there are 195 who own a diamond ring, 367 who own a set of golf clubs, and 562 who own a garden spade. In addition, each of the 900 residents owns a bag of candy hearts. There are 437 residents who own exactly two of these things, and 234 residents who own exactly three of these things. Find the number of residents of Aimeville who own all four of these things.
Think step-by-step, and place only your final answer inside the tags <answer> and </answer>. Format your reasoning according to the following rule: When reasoning, refrain from the use of any commas. Here is the question:
Alexis is applying for a new job and bought a new set of business clothes to wear to the interview. She went to a department store with a budget of $200 and spent $30 on a button-up shirt, $46 on suit pants, $38 on a suit coat, $11 on socks, and $18 on a belt. She also purchased a pair of shoes, but lost the receipt for them. She has $16 left from her budget. How much did Alexis pay for the shoes?