
Summary
TorchForge RL pipelines now run on Together AI’s Instant Clusters with support for distributed training and sandboxed environments. This blog provides a demo of a TorchForge RL pipeline along with guidance for configuring it for broader use cases. These capabilities will serve as the foundational components of Together AI’s upcoming RL service.
The AI Native Cloud provides the foundation for a next-gen RL service
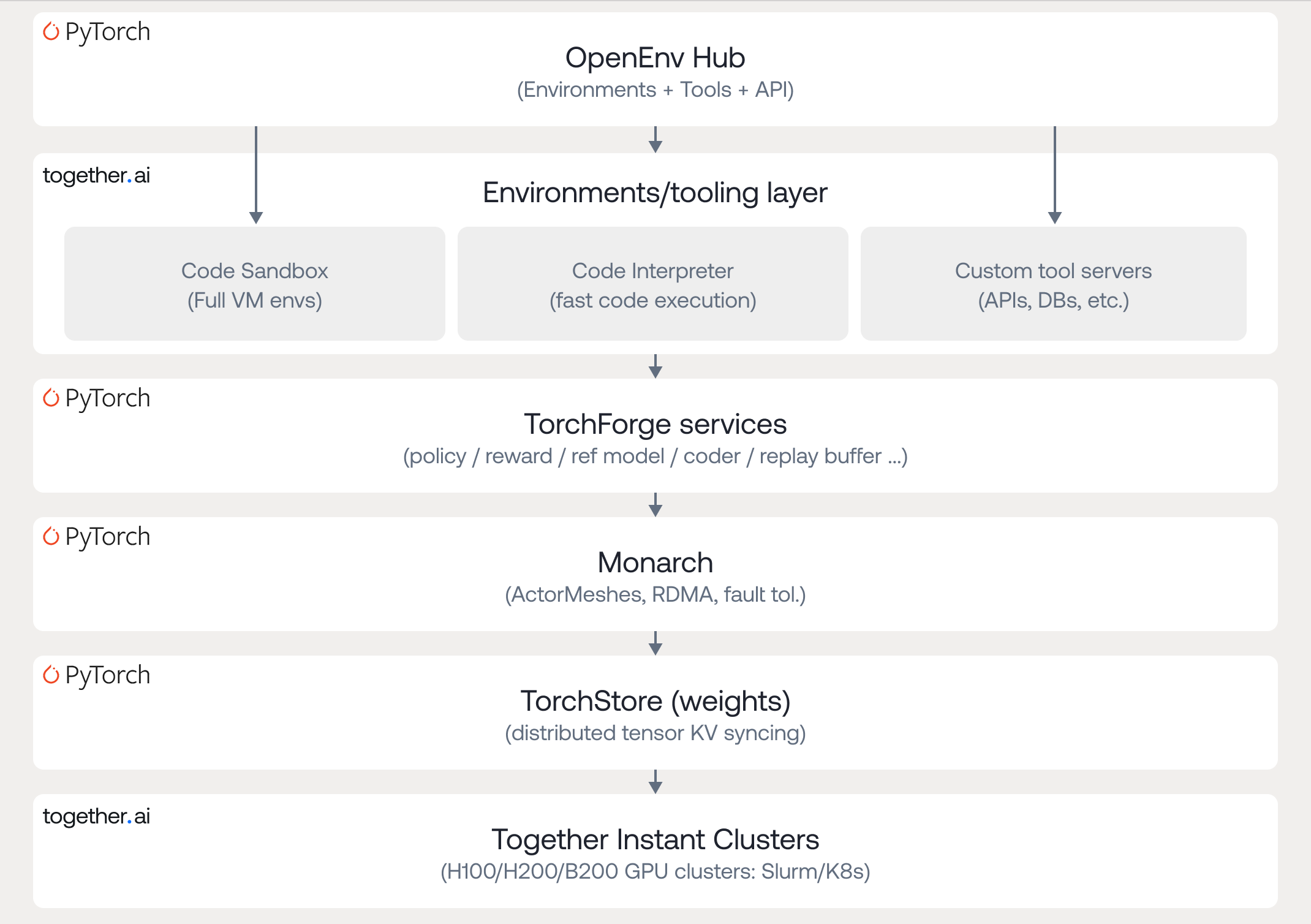
Building flexible, scalable reinforcement learning (RL) systems requires compute, frameworks, and tooling that are compatible and efficient. Modern RL pipelines extend far beyond simple training loops—they rely on distributed rollouts, high-throughput inference, tool-based environments, reward evaluators, and tight coordination across CPU and GPU resources.
Today, the full PyTorch stack – including TorchForge and Monarch – runs with distributed training capabilities on Together Instant Clusters, which provide:
- Low-latency GPU communication: InfiniBand/NVLink topologies that match the requirements of TorchForge and Monarch for RDMA-based data transfers and distributed actor messaging.
- Consistent cluster bring-up: Instant Clusters booted with drivers, NCCL, CUDA, and the GPU operator preconfigured, allowing PyTorch distributed jobs (SPMD or Monarch-based) to run without any manual setup.
- Heterogeneous RL workload scheduling: GPU nodes for policy replicas and trainers, and CPU-optimized nodes for environments, tool execution, and code execution.
Together clusters are a natural fit for RL frameworks that mix GPU-bound model computation with CPU-bound environment workloads.
A large fraction of RL workloads involve calling tools, running code, or interacting with sandboxed environments. Together AI supports these needs natively:
- Together CodeSandbox → full microVM environments for tool-use, coding tasks, simulation, and environment logic that cannot run inside standard containers.
- Together Code Interpreter → fast, isolated Python execution, ideal for unit-test–based reward functions or code-evaluation tasks.
Both integrate with OpenEnv and TorchForge environment services, allowing rollout workers to invoke these tools during training.
Demo: RL training with PyTorch on Together Instant Clusters
Today, we’re releasing a demo of a TorchForge RL pipeline running on Together Instant Clusters and interacting with an OpenEnv environment hosted on Together CodeSandbox. Adapted from a Meta reference implementation, the demo trains a Qwen 1.5B model to play BlackJack using GRPO. The RL pipeline integrates a vLLM policy server, BlackJack environment, reference model, off-policy replay buffer, and a TorchTitan trainer—connected through Monarch’s actor mesh and using TorchStore for weight synchronization.
The OpenEnv GRPO BlackJack repository contains Kubernetes manifests and setup scripts. To deploy and start RL training, simply run the three kubectl commands found in the getting-started guide. Experiment by swapping in different models via the config file, adjusting GRPO hyperparameters such as the KL-penalty coefficient, or modifying the reward function to encourage new playing strategies.
We’re also releasing a standalone integration that wraps Together’s Code Interpreter as an OpenEnv environment. This allows RL agents to interact with the Interpreter like any other environment—issuing code snippets as actions, receiving execution outputs as observations, and scoring these observations with custom rewards. As a result, the same RL pipeline used for game-playing can be applied to coding tasks, mathematical reasoning, or any computation that can be expressed through code.
These demos show that sophisticated, multi-component RL training can run on the Together AI Cloud with the same ease as a simple training script on a local GPU. And this is just the beginning! We’re building on this foundation with Meta to create a flexible, open RL framework in the PyTorch ecosystem, delivered as a scalable, high-performance service on the Together AI Cloud. We’re excited to continue this journey and will share more as we advance the forefront of reinforcement learning. Stay tuned!