

Summary
Current data science benchmarks rely on incompatible evaluation interfaces. Moreover, many tasks can be solved without using the underlying data. We address these limitations by introducing DSGym, an integrated framework for evaluating and training data science agents in self-contained execution environments. Using DSGym, we trained a state-of-the-art open-source data science agent.
arXiv paper: https://arxiv.org/abs/2601.16344
Github repo: https://github.com/fannie1208/DSGym
Data science serves as the computational engine of modern scientific discovery. However, evaluating and training LLM-based data science agents remains challenging because existing benchmarks assess isolated skills in heterogeneous execution environments, making integration costly and fair comparisons difficult.
We introduce DSGym, a unified framework that integrates diverse data science evaluation suites behind a single API with standardized abstractions for datasets, agents, and metrics. DSGym unifies and refines existing benchmarks while expanding the scope with novel scientific analysis tasks (90 bioinformatics tasks from academic literature) and challenging end-to-end modeling competitions (92 Kaggle competitions). Beyond evaluation, DSGym provides trajectory generation and synthetic query pipelines for agent training—we demonstrate this by training a 4B model on 2k generated examples, achieving state-of-the-art performance among open-source models.
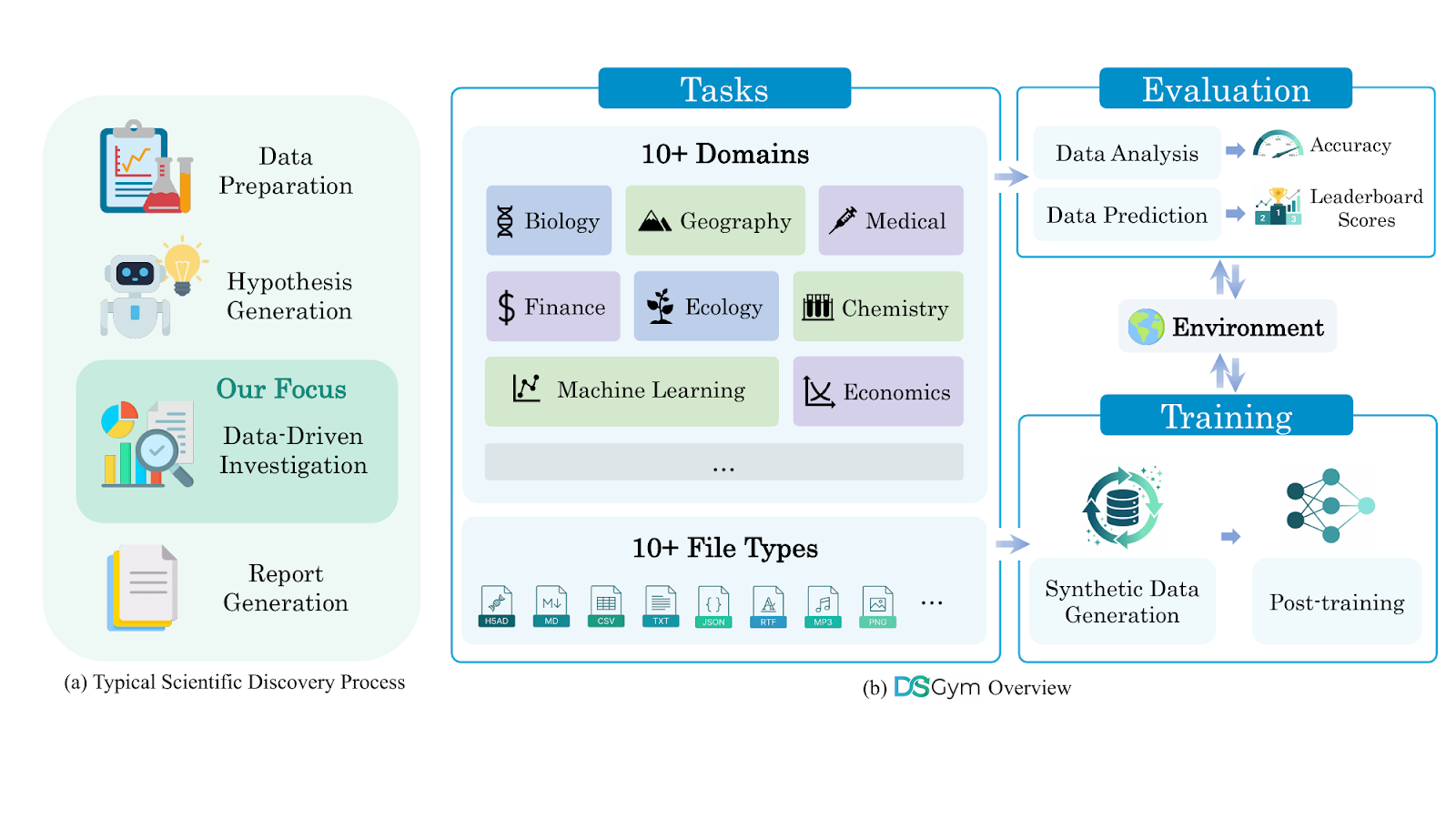
Framework and datasets
One of the main contributions of DSGym is that it abstracts the complexity of code execution behind containers that can be allocated in real time to execute code safely; these containers come with pre-installed dependencies and data available for processing.
DSGym provides a unified JSON interface for all benchmarks, where each task is expressed as: data files, query prompt, evaluation metric, and metadata. We strive to make the design modular and straightforward. In this way adding new tasks, agent scaffolds, tools, and evaluation scripts should be simpler for users. The tasks in DSGym are categorized into two primary tracks:
- Data Analysis (query-answering via programmatic analysis).
- Data Prediction (end-to-end ML pipeline development).
In addition to integrating established benchmarks like MLEBench and QRData, DSGym introduces original datasets. Specifically, we expand the general scope by creating two novel suites: DSBio (90 bioinformatics tasks from academic literature probing domain-specific workflows) and DSPredict (92 Kaggle competitions spanning time series, computer vision, molecular property prediction, and single-cell perturbation). The next figure summarizes our creation process for these two suites:
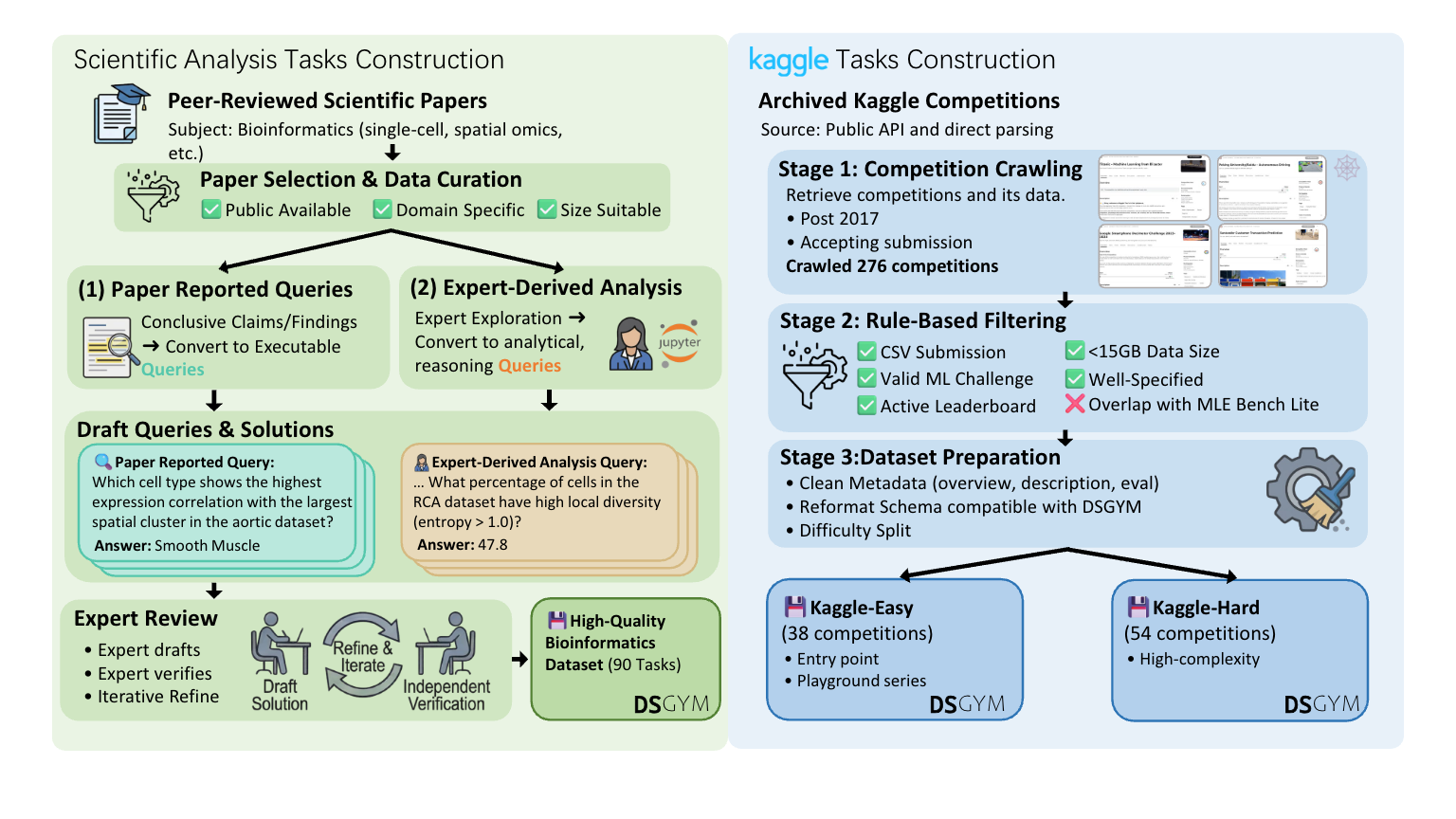
To support task execution and data generation, DSGym provides a data generation pipeline to execute queries and generating trajectories, turning the framework into a data factory that can effectively train models.
Using this pipeline, we generated 3,700 synthetic queries. After applying LLM-based quality filtering, we obtained 2,000 high-quality query-trajectory pairs for supervised finetuning. Our results (presented next) demonstrate that these data can be an effective way to improve model performance on data science tasks, even for small models.
Results
We present here our main findings. Additional results are available in the paper.
Addressing the memorization gap
A first and important result concerns memorization. We observe that many existing benchmark queries provide weak signals: a non-trivial fraction remains solvable even without data file access, suggesting LLMs might have learned about these tasks during training.
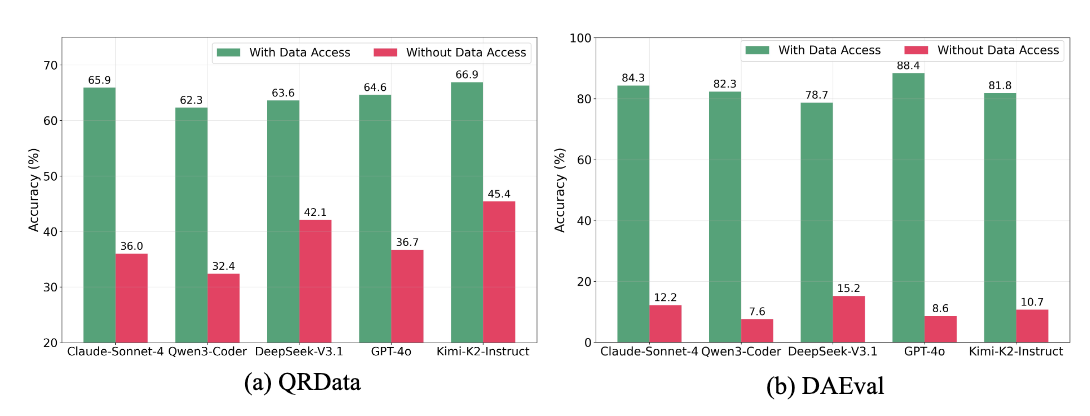
Thus, we made sure to flag and exclude these examples that are likely in the training sets of the models. DSGym applies quality filtering and prompt-only shortcut filtering to remove such tasks, producing refined datasets: DAEval-Verified, QRData-Verified, DABStep, and MLEBench-Lite.
Benchmark performance & failure Mmodes
After creating these new benchmarks, we test frontier proprietary and open-weight LLMs across general-purpose data science and domain-specific scientific tasks.
Our trained 4B model (Qwen3-4B-DSGym-SFT-2k) achieves competitive performance with much larger models on general analysis benchmarks.
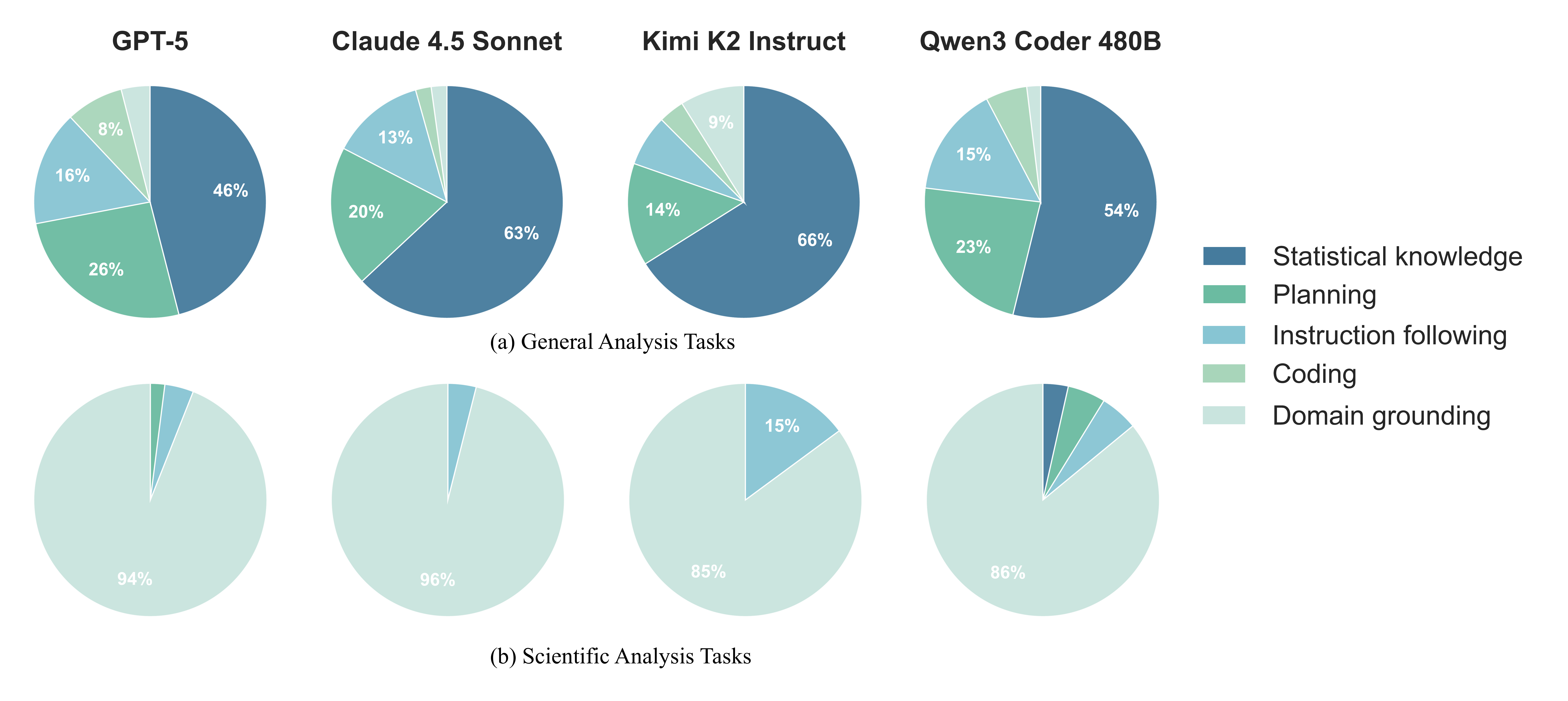
Interestingly, most models are still far from getting perfect scores on these benchmarks. To understand why models fail on these tasks, we conducted a manual error analysis of 50 randomly sampled failed trajectories per model and task family. This analysis reveals an interesting pattern: while general analysis tasks show diverse failure modes, with statistical knowledge gaps and planning errors being most common, scientific analysis tasks are dominated by a single failure mode.
Data prediction performance
DSPredict evaluates the ability of agents to build complete machine learning pipelines—from raw data to a final model—mimicking the complexity of Kaggle competitions.
We evaluate models on DSPredict-Easy and DSPredict-Hard splits. Performance is measured by:
- Valid Submission: Successful generation of a correctly formatted output file.
- Median/Percentile: Performance relative to the original competition leaderboard.
- Medal: Achieving score thresholds equivalent to Bronze, Silver, or Gold medals.
We use a simple CodeAct like scaffold. Each agent is given a time limit of 10 hours for total time and 2 hours for each code execution.
Our analysis of the DSPredict results reveals several critical insights into the current capabilities and limitations of LLM agents in end-to-end ML workflows.
High reliability, low competitiveness: While frontier models (like GPT-5.1 and Claude 4.5) are excellent at creating functional pipelines—achieving over 85% valid submission rates—they struggle to be competitive. Very few models can consistently beat the human median on "Hard" tasks.
A major bottleneck is the tendency for models to choose the path of least resistance. When faced with technical friction or complex data, agents often default to simple baselines or "safe" heuristics rather than pursuing high-performance modeling strategies.
Reasoning vs. scale: High-reasoning models (GPT-5.1-high) show a significant lead, suggesting that the "skeptical" persistence required for data science—tuning, validating, and iterating-is currently a more critical factor than raw parameter count.
Conclusion
DSGym provides a unified framework for evaluating and training data science agents. We expose a fundamental challenge in current approaches: models rely heavily on memorization for general tasks while failing to ground their analysis in domain knowledge for scientific problems.
By offering standardized benchmarks spanning both task types, DSGym enables systematic investigation of how to build agents that truly reason about data rather than recall patterns. We also release a capable open source data science agent that’s easy to develop and deploy. We hope this resource accelerates progress toward more reliable and generalizable data science automation.