
TL;DR
It’s critical LLMs follow user instructions. While prior studies assess instruction adherence in the model’s main responses, we argue that it is also important for large reasoning models (LRMs) to follow user instructions throughout their reasoning process.
We introduce ReasonIF, a systematic benchmark for assessing reasoning instruction following abilities across multilingual reasoning, formatting, and length control.
We find frontier LRMs, including GPT-OSS-120B, Qwen3-235B, and DeepSeek-R1 fail to follow reasoning instructions more than 75% of time. Notably, as task difficulty increases, reasoning instruction following degrades further.
For more information, please find our paper and GitHub repository.
Introduction
From exploring research ideas to building large‑scale software systems and making informed decisions, large reasoning models (LRMs), which generate step-by-step reasoning traces between special tags (e.g., <think>...</think> in DeepSeek family models, and <|channel|>analysis<|message|>...<|end|> in GPT-OSS family models), have rapidly become popularized. Their reasoning ability not only improves interpretability but also allows for iterative refinement, making LRMs highly effective in tasks requiring extensive reasoning. At Together AI, we're thrilled to see explosive interest in LRMs across the entire AI lifecycle — yet, a key question remains:
Do these high-performing models follow user instructions in their reasoning trace?
Following user instructions throughout the reasoning trace — not just in the final response — improves controllability, transparency, and safety.
- Process-level instruction following makes interactions more predictable and user-centered, allowing users to guide how the model thinks, not just what it outputs.
- Structured reasoning traces (e.g., JSON steps, cited evidence) enable programmatic auditing for logic and compliance.
- Consistent adherence to reasoning instructions helps prevent reward hacking and shortcuts that produce superficially correct answers.
- Faithful, instruction-aligned reasoning is also more robust to adversarial manipulation, since explicit user-defined rules constrain the model's internal steps.
Motivated by these points, we introduce a new benchmark and evaluate how faithfully LRMs follow instructions when producing reasoning traces. Our key findings: while models generally comply in their final responses, they fail far more often in their reasoning steps — and this shortfall worsens with task difficulty.
2. ReasonIF: A new benchmark dataset
To push the field forward, we introduce ReasonIF, a new benchmark dataset designed to evaluate instruction‑following abilities within reasoning traces. ReasonIF consists of 300 math and science problems, each paired with a concrete reasoning instruction. Every input prompt comprises two components.
- A question sampled from established benchmark collections (GSM8K, AMC, AIME, GPQA‑diamond, and ARC‑Challenge), ensuring a broad spectrum of reasoning styles.
- An instruction randomly selected from a set of six user‑oriented directives the model must obey throughout its step‑by‑step solution.
Following the previous work, IFEval (Zhou et al., 2023), which examined general instruction‑following capabilities of large language models, we employ verifiable instructions that can be automatically evaluated without relying on another LLM. However, unlike IFEval, our focus is on the reasoning trace itself. The six instruction types are crafted to reflect realistic user needs — enabling precise, automatic verification of whether the model adheres to the prescribed reasoning guidance.
- Multilinguality: Constrains reasoning to a specific language (e.g., Hindi, Arabic).
- Word limit: Caps verbosity to save cost and improve conciseness.
- Disclaimer: Enforces a safety reminder appended verbatim at the end.
- JSON formatting: Ensures structured, machine-readable outputs.
- Uppercase only: Forces strict formatting and tests fine-grained syntactic control.
- Remove commas: Similar to "Uppercase only".
Here are a few representative examples in our benchmark dataset:
Before diving into the quantitative results, we present an example illustrating how LRMs adhere to the instruction throughout their reasoning process — as it shows, many LRMs often fail to follow instructions.
3. LRMs often fail to follow instructions during reasoning
All state-of-the-art LRMs we tested demonstrated poor instruction-following (IF) in the reasoning trace, with even the best model achieving a less than 25% following score in our analysis. Compared to the IF in the main response, instruction-following score (IFS) plummeted in the reasoning trace (see Figure 1). For example, Qwen-3-235B — among the strongest open-source LRMs — showed a more than 50% drop in the IFS, showing the incompetence of LRMs' capability in IF throughout reasoning. Note that we exclude closed models from our experiments because their APIs do not provide reasoning traces. Other implementation details are available in the paper.

Furthermore, the instruction‑specific analysis (Figure 2) shows this pattern holds for all instruction types. Notably, for the Uppercase‑only and JSON‑formatting constraints, no model consistently produced valid outputs in its reasoning trace — success rates hover near 0%, with the best model achieving only a few percent compliance. This confirms current LRMs often fail to follow explicit formatting instructions during reasoning.

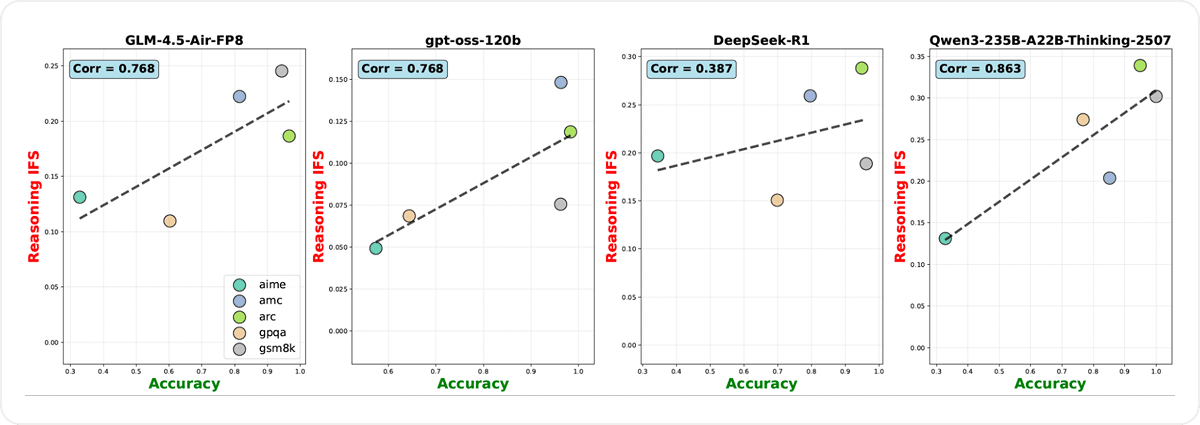
4. Reasoning Instruction-Following capabilities decline with task difficulty
Our analysis uncovered a clear and troubling pattern: the harder the task, the less faithfully models follow instructions during reasoning.
As benchmark difficulty increased — from GSM8K's relatively simple arithmetic to AIME's, GPQA-diamond's advanced math and science questions — LRMs' reasoning IFS steadily decreased. This decline was consistent across model families. As in Figure 3, the correlation between the model accuracy and the IFS can be as high as 0.863 (Qwen3-235B), and even the model with the smallest value (DeepSeek-R1) shows the correlation of 0.387. This finding supports our claim and mirrors the analogous finding for the primary response reported by Fu et al. (2025): the more difficult, the less to follow instructions in the reasoning.
This trend has important implications. In real-world deployments, where problems are complex and instructions are nuanced, users cannot assume that models will respect their requirements during reasoning. This limits trustworthiness, reproducibility, and safe integration of LRMs into critical workflows.
Conclusion
We introduce ReasonIF, a novel benchmark dataset to examine state-of-the-art open-source LRMs' reasoning IF capability. We observe a significant gap between IF capability of reasoning traces and main responses in LRMs. Further, we find a positive correlation between reasoning IF capability and task difficulty. In the paper, we further explore two strategies to enhance reasoning instruction fidelity: (1) multi-turn reasoning and (2) Reasoning Instruction Fine-tuning (RIF) using synthetic data, where RIF improves the IFS of GPT-OSS-20B from 0.11 to 0.27, indicating measurable progress but leaving ample room for improvement. For more information, check out our paper and codebase.
Citation
References
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y., & Hou, L. (2023). Instruction-following evaluation for large language models. arXiv:2311.07911.
Murthy, R., Kumar, P., Venkateswaran, P., & Contractor, D. (2024). Evaluating the Instruction-following Abilities of Language Models using Knowledge Tasks.
Sun, W., Zhang, C., Zhang, X., Yu, X., Huang, Z., Chen, P., ... & Liu, K. (2024). Beyond instruction following: Evaluating inferential rule following of large language models. arXiv preprint arXiv:2407.08440.
Fu, T., Gu, J., Li, Y., Qu, X., & Cheng, Y. (2025). Scaling reasoning, losing control: Evaluating instruction following in large reasoning models. arXiv preprint arXiv:2505.14810.