
Frontier AI teams need high-performance compute, and they need it fast. Today, we’re launching Together Instant GPU Clusters, a self-service solution accelerated by up to 64 NVIDIA GPUs per cluster, available within minutes. This service is now in preview, and we are gradually rolling it out to select users.
Why Together Instant GPU Clusters?
🚀 Instant AI Compute: No approvals, no wait times—deploy high-performance clusters in minutes.
🔗 Optimized for Distributed AI: Together Instant GPU Clusters feature the NVIDIA Cloud Partner (NCP) reference architecture with NVIDIA Blackwell and Hopper GPUs, non-blocking NVIDIA Quantum-2 InfiniBand and NVIDIA NVLink™ networking, ensuring ultra-low-latency, high-throughput performance for large-scale AI workloads.
🛠 Flexible Deployment: Customers can choose Kubernetes or Slurm for workload orchestration, giving them full control over their AI infrastructure.
⚙️ Choice of NVIDIA Driver and NVIDIA CUDA® Versions: Users have full control over their cluster, with the option of selecting the versions of NVIDIA Drivers and CUDA.
💰 Start Small: Instant GPU Clusters enable teams to provision GPU clusters starting from a single 8-GPU node, for as little as three days, eliminating the need for lengthy, upfront commitments.
How to Spin Up a Cluster
- Log in to the Together AI console.
- Select your configuration:
- GPU Type: NVIDIA H100 (80GB SXM)
- Cluster Size: Options include 8, 16, 32, or 64 GPUs
- Software Stack: Kubernetes or Slurm
- Storage: Adjustable from 1TB, based on workload needs
- Duration: Flexible rental periods from 3–90 days
- Deploy in minutes—your fully interconnected GPU cluster is ready to use.
Note you will need to be whitelisted to access Together Instant GPU Clusters.
Apply at together.ai/instant
Turbocharging AI Workloads: When to Use Instant GPU Clusters
Together Instant GPU Clusters accelerated by NVIDIA are designed for AI teams that need immediate access to high-performance compute for a variety of real-world use cases:
✅ Burst Compute for Short-Term Needs – When you need a surge of GPU capacity for a short period, such as handling peak demand, running a hackathon, or tackling an urgent project deadline.
✅ Model Validation Before Long-Term Commitment – Test drive an AI training environment before making a longer-term investment. Validate model compatibility, performance expectations, and software stack configurations.
✅ Faster Access, No Sales Process – Skip lengthy approvals and procurement cycles. Deploy NVIDIA GPUs instantly without waiting for sales conversations or capacity planning.
Pricing: Simple, Transparent, and Flexible
Together Instant GPU Clusters provide high-performance compute at a competitive, predictable cost structure.
GPU Pricing
Storage Pricing
Our storage from platforms including VAST Data and WEKA is optimized for high-performance AI workloads, ensuring low-latency data access.
Data Transfer: Always Free
We believe that moving your data should not be a barrier. Unlike traditional cloud providers that charge for egress, Together AI keeps data transfer free to enable seamless AI development.
How We Built It
To build the Together Instant GPU Clusters, we've developed a comprehensive, end-to-end software stack that streamlines the entire cluster lifecycle. This includes creation and deployment, connectivity, acceptance testing, validation, and installation of either Kubernetes or Slurm on Kubernetes. Our Instant GPU Clusters are built on a foundation of open-source software, leveraging customized provisioning to optimize the performance of GPUs, high-speed interconnects, and storage systems. This ensures that every cluster is delivered to users in a fully configured and tuned state, ready for optimal performance.
The Instant GPU Clusters architecture enables multi-tenancy through virtualization, allowing user workloads to run in Virtual Machines (VMs) for training with either Slurm or managed Kubernetes (K8s). Additionally, Instant Clusters are compatible with the NCP architecture and offer bare-metal performance for compute, network and storage resources, making them ideal for multi-node training. Furthermore, our clusters provide ultra-fast provisioning, ready for use in minutes, to help you get started quickly and efficiently.
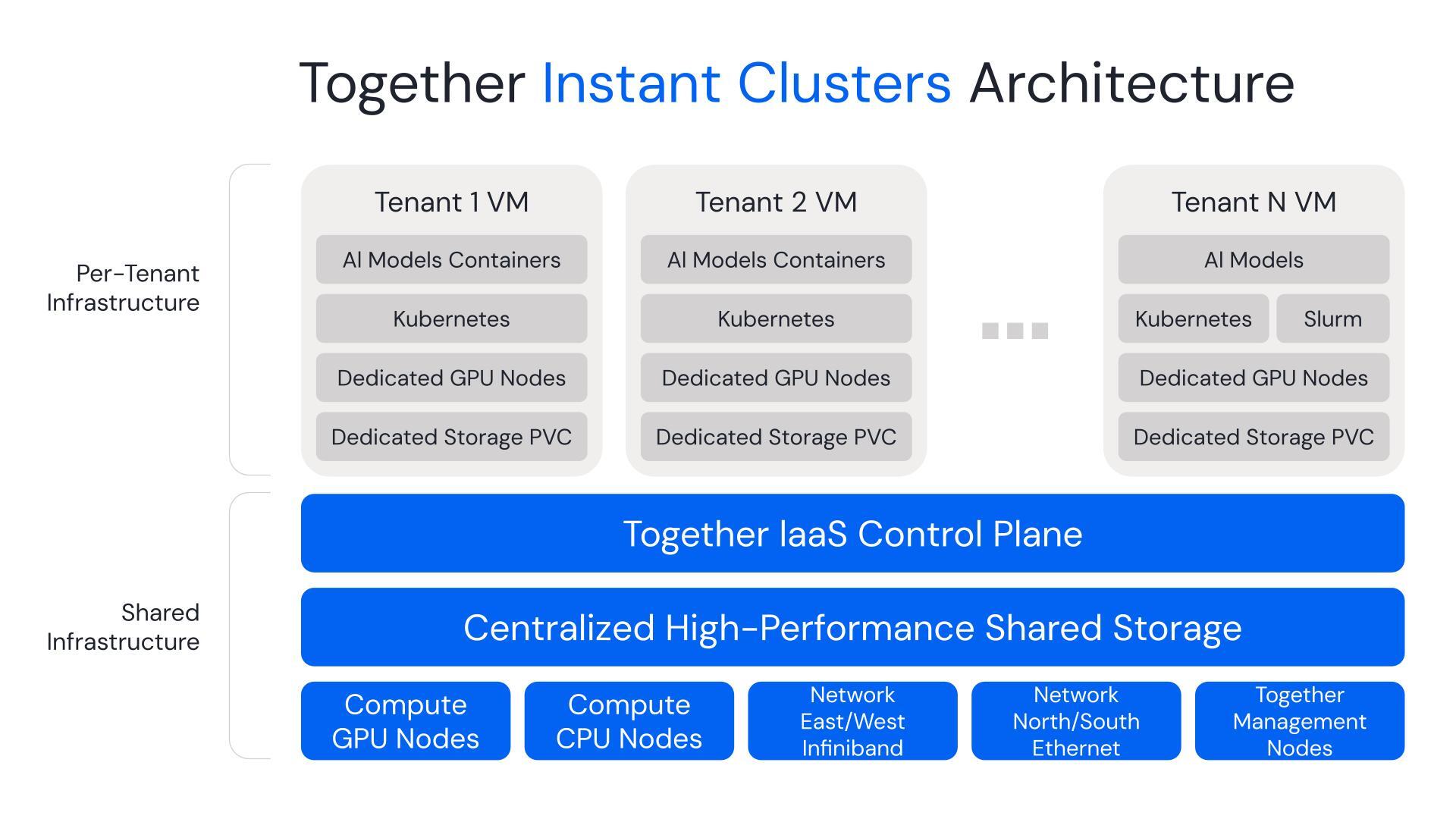
Ultimately, Together Instant GPU Clusters combine advanced hardware provisioning with intelligent automation to deliver high-performance AI compute without the typical complexity associated with large-scale infrastructure.
Get Started
Together Instant GPU Clusters are live today in Preview. To be among the first to experience ultra-fast, frictionless AI compute at scale, apply to be added to our whitelist.