Fine-tuning Llama-3 to get 90% of GPT-4’s performance at a fraction of the cost
The success of Llama-3 has been incredible, proving that open source models are rapidly catching up to closed models without compromising private ownership. Our customers have been using their own proprietary data to fine-tune small OSS models like Llama-3 to run their tasks with greater accuracy than even the top closed-source models are capable of. Their fine-tuned model is small, accurate, and fully owned and controlled by them.
Discover how to leverage Together AI's platform to fine-tune Llama-3-8b on your proprietary data, creating a custom model that outperforms leading OSS alternatives like Llama-3-70b and is comparable to leading closed-source alternatives like GPT-4 at a fraction of the cost. This step-by-step guide demonstrates how a fine-tuned Llama-3 8B model went from 47% accuracy on the base model to 65% accuracy, even surpassing Llama-3-70B (64%) and coming close to GPT-4o (71%). Learn how you can create faster, more accurate, and fully owned AI solutions for your specific use cases, all while reducing costs by an order of magnitude compared to using GPT-4.
The full repo is available here if you want to run all the code yourself: https://github.com/togethercomputer/finetuning
Dataset Transformation
The first thing we’ll do is download the Math Instruct dataset. Navigate to MathIntruct on HuggingFace and click download next to MathInstruct.json. After we do this, we’ll run a quick cleanup script to remove duplicates, remove 1,000 problems to save them for evals, and rename the final file to MathInstruct-207k.json. If you want to follow along, feel free to clone the GitHub repo and use the TrainMathInstruct-500.json file to fine-tune a smaller dataset.
Next, we need to transform this dataset into a .jsonl file, since that’s the file format Together supports. We can use some Python code and the Llama-3 instruct format to do this:
We can then use check_file function from Together’s SDK to verify that our dataset is valid and in the correct format:
If the assertion passes, you’re ready to upload your dataset to Together AI!
Uploading & checking your dataset
Now that we have a valid dataset, we’ll upload it to Together AI via the Python SDK. Make sure to pip install together, save your API key as an environment variable called TOGETHER_API_KEY, then run the following code to upload it and verify that it was uploaded successfully.
You can also upload a dataset through our CLI.
Starting a Fine-tuning job
We’re now ready to fine-tune a model using our uploaded dataset! We’ll create a fine-tuning job using Llama-3-8B as our base model, specify our dataset as the training_file, use 5 epochs, and optionally add a Weights and Biases API key if we want to monitor the fine-tuning job with graphs such as a loss curve.
After you run this code, your fine-tuning job will be kicked off. You’ll be able to view it on your Together AI jobs dashboard.

Running your fine-tuned model
When your fine-tuning job has finished (this dataset takes ~2-14 hours depending on the number of epochs), you’ll be able to view and launch it from your dashboard on Together AI.
Navigate to the Models page, click on your fine-tuned model, and click Deploy to create an endpoint with one of the hardware configurations below. For this tutorial, we’ll deploy on 1 A100-80GB. (If you don’t mind lower latency, you can also deploy on cheaper hardware like L40s or RTX-6000s.)
After your endpoint spins up, you can test it in the Together AI playground by clicking the green Play button, or you can call directly from your code using our API. We’ll be calling it through our API in the following section to fully evaluate it.
Running evaluations to see results
Now that we have our fine-tuned model, we want to see if it performs better than the base model (and other models out there). We’ll be using an LLM to judge the results (also known as LLM-as-a-judge) since it’s straightforward, but there are more sophisticated and deterministic ways you can also use to evaluate your model.
To do this, we’ll take 1000 math problems that the LLM has never seen before and run them through both the base Llama-3-8B and our fine-tuned Llama-3-8B, and evaluate the accuracy of each. We’ll also run them through LLama-3-70B and GPT-4o to see the accuracy from the top OSS and proprietary models to put it in perspective.
To start, let’s define our eval dataset. We’ll grab 1000 problems from the dataset that were not used in the initial training and save them to a file called EvalDataset-1000.json. We can then iterate through each problem and have our base and fine-tuned model both answer it, then store results in results.json.
Note: All this code, including the dataset and eval dataset, are available on GitHub here.
Now that we have the results from the 1000 problems from our base and fine-tuned models, we can send them to an evaluator model (in this case, we’ll use Llama-3-70B) to grade them on accuracy and output a final score:
Results
We evaluated a dataset of 1000 math problems on the base model, our fine-tuned model, and top large models such as Llama-3-70B and GPT-4o. Here are the results for accuracy:
Our small 8B fine-tuned model outperformed the base model by nearly 20%, beat out top OSS model LLama-3-70B, and achieved over 90% of GPT-4o’s accuracy. It also leads all evaluated models in accuracy and gets 91% of GPT-4o’s accuracy while being much faster, 50x cheaper than GPT-4o, and giving the end user full ownership of the model and weights (you can download and run the model yourself).
Not only is our fine-tuned model more accurate, its responses are more succinct and organized, translating to lower costs and faster response times when running tasks.
Let’s look at a quick example next.
Comparing responses from the base and fine-tuned models
For the following question (where C is the correct answer), notice the difference in the base model and fine-tuned model responses.
Question: A sum of money is to be distributed among A, B, C, D in the proportion of 5 : 2 : 4 : 3. If C gets Rs. 1000 more than D, what is B's share?
Answer Choices: (A) 1000 (B) 3000 (C) 2000 (D) 4000 (E) 5000
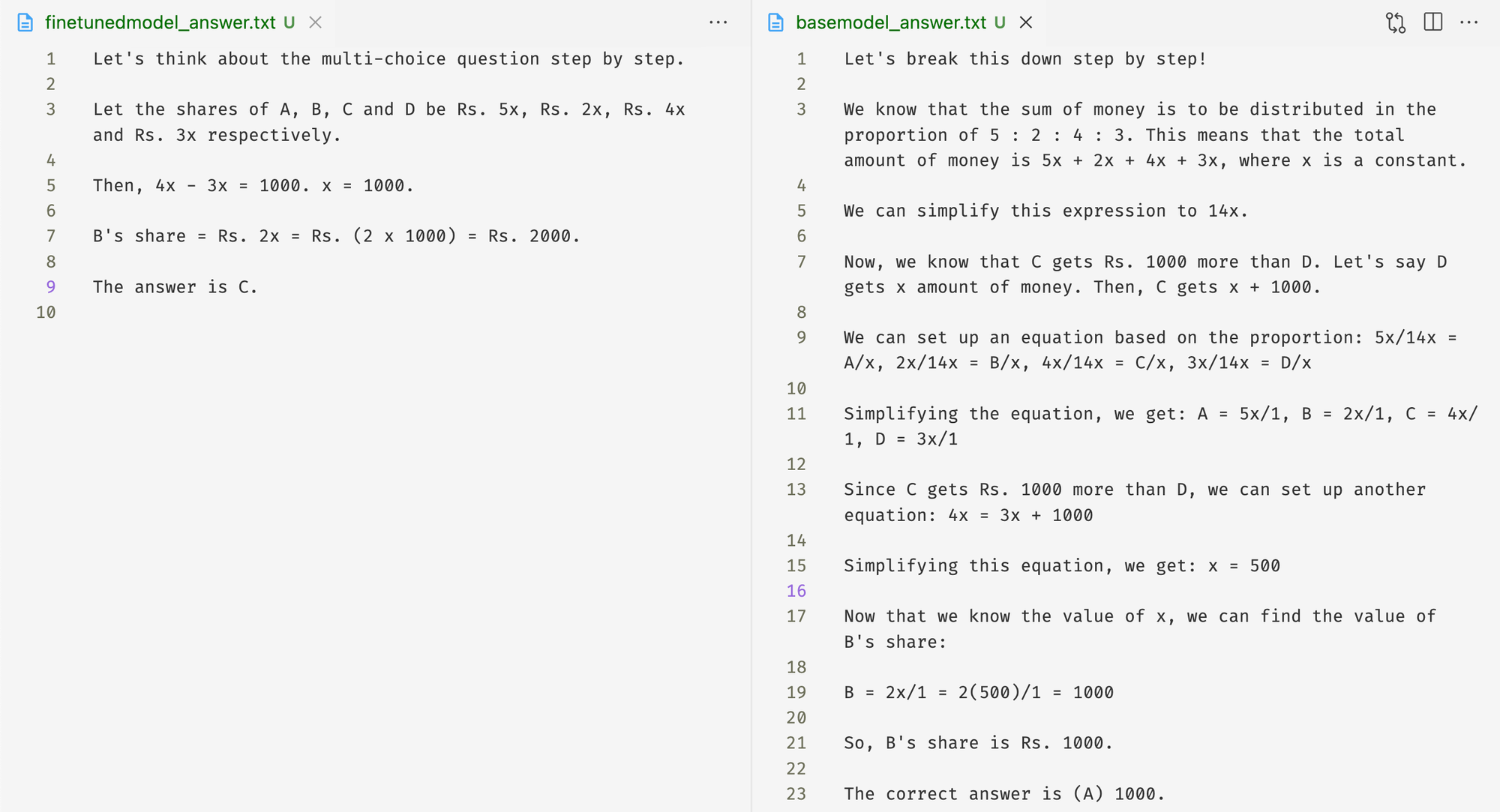
The base model got the answer wrong and took 311 tokens, while the fine-tuned model answered correctly using only 100 tokens.
Conclusion
Our walkthrough shows that fine-tuning small open-source models like Llama-3-8B can result in a custom model that is smaller, faster, cheaper, and more accurate for performing specific tasks. Even more, we didn’t have to compromise flexibility or ownership, meaning we can use our own proprietary data to fine-tune a model, and then either use Together to host it, or download and run it ourselves.
The Llama-3-8B model that we trained on math problems in this blog post outperformed leading OSS models and got close to GPT-4o performance, while only costing <$100 total to fine-tune on Together AI. To learn more, check out our guides on Fine-tuning on Together AI, or get in touch to ask us any questions!

- Lower
Cost20% - faster
training4x - network
compression117x
Q: Should I use the RedPajama-V2 Dataset out of the box?
RedPajama-V2 is conceptualized as a pool of data that serves as a foundation for creating high quality datasets. The dataset is thus not intended to be used out of the box and, depending on the application, data should be filtered out using the quality signals that accompany the data. With this dataset, we take the view that the optimal filtering of data is dependent on the intended use. Our goal is to provide all the signals and tooling that enables this.


article