
What’s New
- Tool call fine-tuning: Ensure agents execute structured actions reliably with end-to-end fine-tuning and inference on OpenAI-compatible schema.
- Reasoning fine-tuning: Specialized support for training models on “thinking” tokens in reasoning traces, allowing models to learn complex logic.
- Vision-language model fine-tuning: Native support for vision training to align vision-language models with complex, domain-specific visual data.
- Large model support: train the latest models with up to 1T parameters on our highly optimized and easy-to-use service.
As AI teams move from single-turn prompting to advanced multi-turn workflows, reliability breaks in predictable places: tool calls that don’t match schemas, reasoning that degrades over long interactions, and models that miss domain-specific visual signals. Fixing those issues usually requires post-training, but the workflow is often fragmented, slow to iterate, and hard to plan.
Today, Together AI, the AI Native Cloud, is expanding Together Fine-Tuning with native support for tool call, reasoning, and vision-language model (VLM) fine-tuning. To support frontier-scale post-training, we have also upgraded the training stack to handle 100B+ parameter models more efficiently, delivering up to 6× higher throughput. In addition, we now support fine-tuning on datasets of up to 100GB in size. Finally, we now provide job cost estimations before training and ETA during training, so teams can better plan their experiments.
"Together AI does for fine-tuning and inference what Vercel does for LLM-based apps — it removes the infrastructure layer so we can focus on our product. We fine‑tune and deploy customer‑specific models through simple API calls. That lets our existing team move from weekly to daily iteration, cut costs by 2–3×, and improve accuracy from 77% to 87%." — Lamara De Brouwer, Co-Founder & CTO, XY.AI Labs
Tool Call Fine-tuning
Tool calling is essential to many modern agentic use cases. Yet, out-of-the-box models often struggle with tool calling: hallucinating parameters, selecting incorrect functions, or failing to follow multi-step sequences. In tool calling workflows, even small inconsistencies can cascade into downstream failures.
Our fine-tuning service now delivers an end-to-end solution for reliable, production-grade tool calling, spanning fine-tuning through inference. Tool calls can be included in training data using the OpenAI-compatible schema. Functions are defined in a top-level tools array, and our service validates that every tool_calls entry matches a declared tool, ensuring structurally correct data before training begins.
At inference time, we’ve significantly improved tool call reliability to ensure the benefits of tool call fine-tuning translate into production performance. Enhanced parsing and validation improve correctness across a wide range of real-world use cases, supported by inference tool calling datasets curated from both community contributions and internal research.
Tool-call fine-tuning is available for models from Qwen, Moonshot AI, and Z.AI. See the tool calling documentation to get started. To see an example of tool call functionality in code, take a look at our cookbook.
Reasoning Fine-tuning
Reasoning models generate intermediate thinking traces before producing a final answer, enabling step-by-step reasoning. However, reasoning formats are not standardized across models, introducing complexity into the reasoning fine-tuning process.
Together Fine-tuning now supports fine-tuning directly on thinking traces using a reasoning or reasoning_content field in assistant messages. This lets you train models on domain-specific reasoning patterns while keeping traces structured and reproducible. As with tool calling, we have improved reasoning inference to ensure that fine-tuned capabilities translate into reliable downstream performance.
Reasoning fine-tuning is available for models from Qwen and Z.AI. See our documentation page for supported models and details. For an end-to-end code demo of reasoning fine-tuning, check out our cookbook
Vision-Language Model Fine-tuning
Many AI workflows require models that can interpret image inputs. For domain-specific tasks like medical imaging and eCommerce, vision-language models (VLMs) may need to learn new visual patterns to be effective.
Together Fine-tuning service now supports fine-tuning of vision-language models. Vision training data is provided inline using message content arrays with base64 encoded images. Fine-tuning jobs support hybrid datasets, allowing both image-text examples and text-only examples within the same run.
By default, we freeze the vision encoder and update only the language layers. Setting train_vision=true enables joint training, allowing updates to both the vision encoder and language layers.
VLM fine-tuning is available for models from Qwen, Google, and Meta. See the vision-language documentation for the supported list and usage details. You can also check out our cookbook for vision language fine-tuning here.
Large Model Fine-tuning
As the sizes of open models grow and context windows expand, the underlying training infrastructure has to keep pace. Trillion-parameter models cannot fit on a single node, thus needing careful communication and memory management across multiple machines. Even a single hardware fault during a multi-hour training run can lead to lost progress, and implementing all optimizations and fault tolerance safeguards can be a major investment.
Together Fine-Tuning now supports fine-tuning for the latest open-weights models. Submit a training job, and we handle all necessary optimizations under the hood. New models available for fine-tuning include:
- Qwen 3.5-397B-A17B
- Qwen 3.5-122B-A10B
- Qwen 3.5-35B-A3B
- Qwen 3.5-35B-A3B-Base
- Kimi K2.5
- Kimi K2 (Instruct, Thinking)
- GLM-4.7
- GLM-4.6
View the full list of supported models along with their context lengths in our documentation.
Training Acceleration
In this update, we continued to focus on the highest-impact optimization opportunities in the training stack. Specifically, we targeted mixture-of-experts architectures, as they represent the vast majority of strongest model releases over the past year. To accelerate their training, we integrated a variant of SonicMoE — I/O- and tile-aware optimized kernels that overlap memory operations with computation. Using these kernels in our training workloads significantly reduced the activation memory footprint during training and minimized wasted compute.
We also introduced custom CUDA kernels for loss computation and eliminated several GPU-to-CPU synchronization points in the training loop that were causing unnecessary stalls, significantly improving the overall pipeline efficiency.
As a result, every model saw at least a 2× increase in throughput, with larger models like Kimi-K2 improving by over 6×. Faster training means more experiments per day and a shorter time to production.
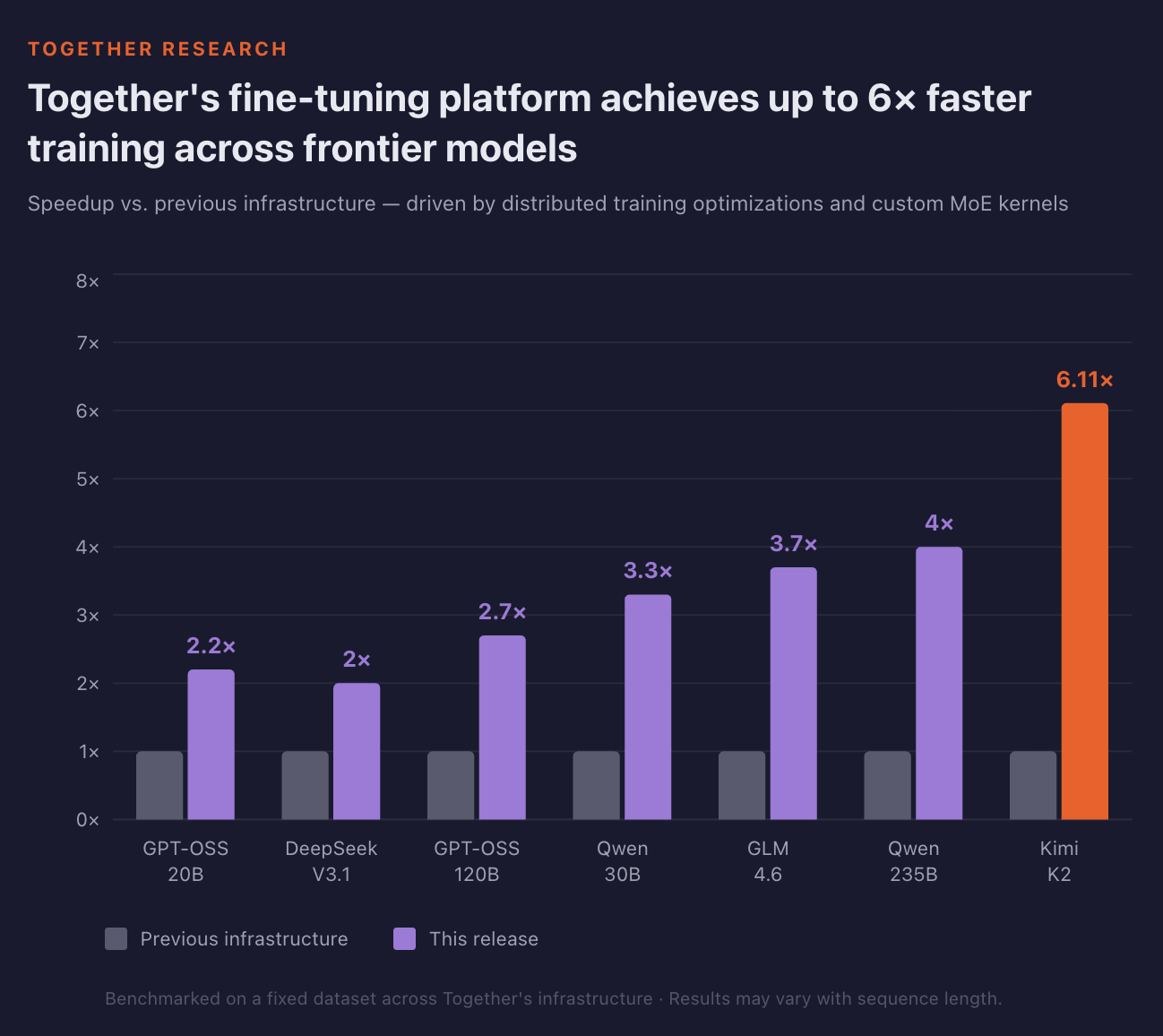
Price and Time Estimation
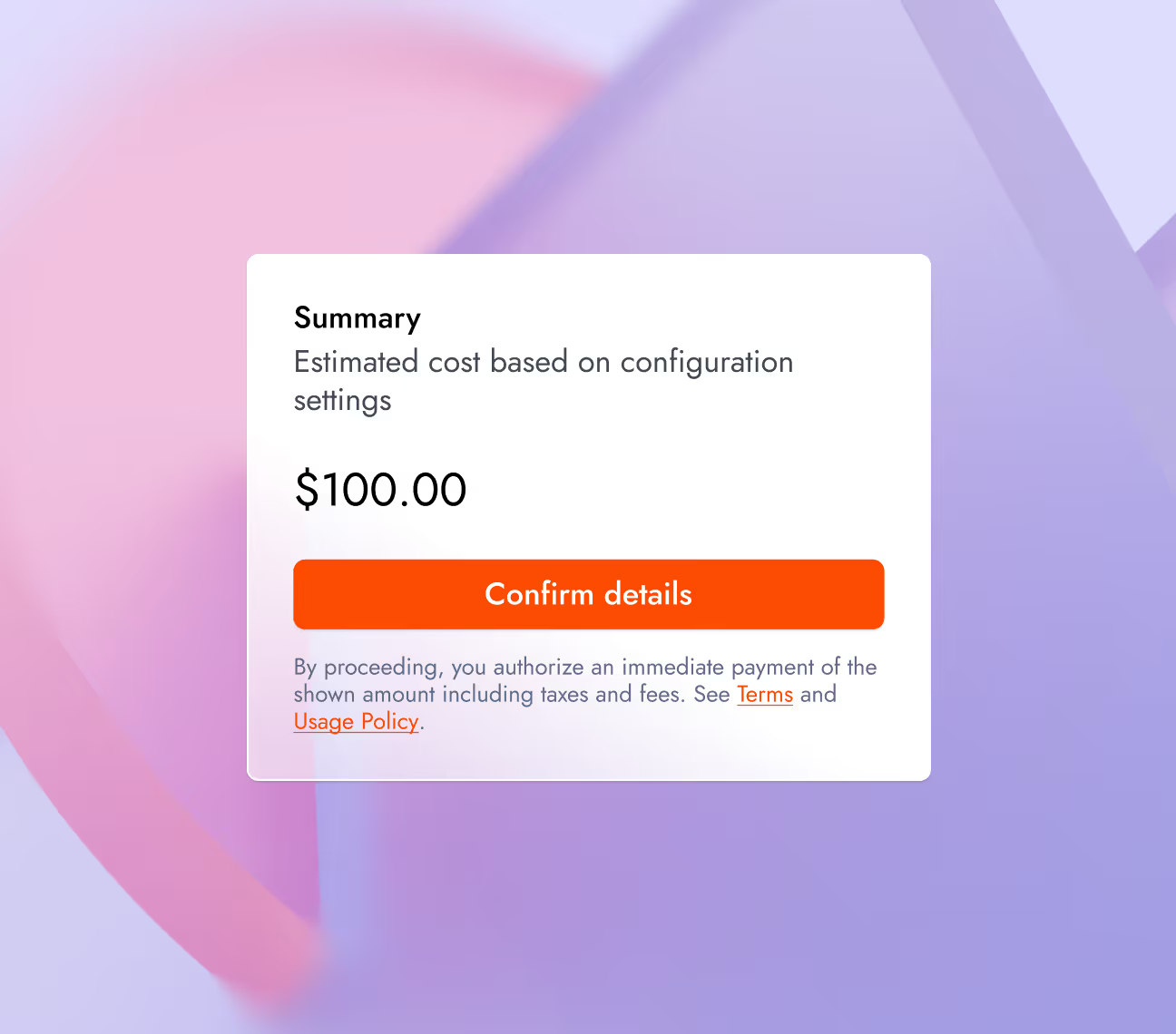
Together Fine-tuning now estimates training costs before a job is executed from the UI or CLI. This price transparency prevents budget surprises.
Cost Estimation: View estimated job price before launching to understand training costs before the cost is incurred.
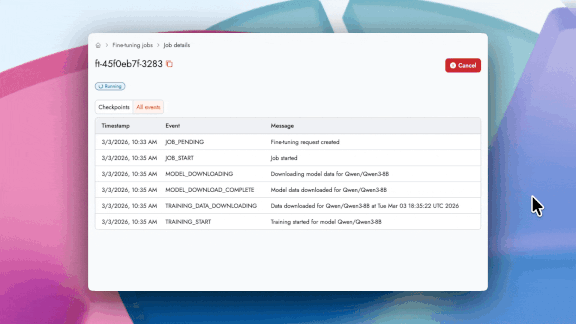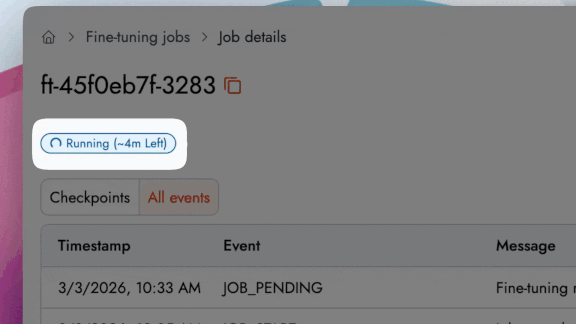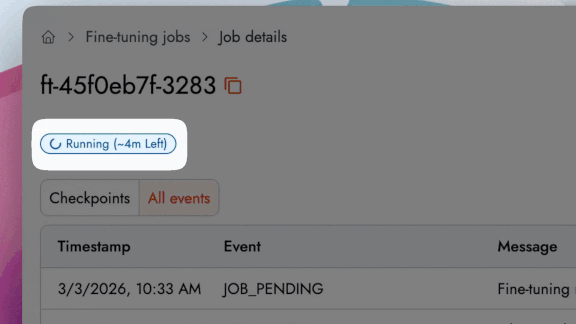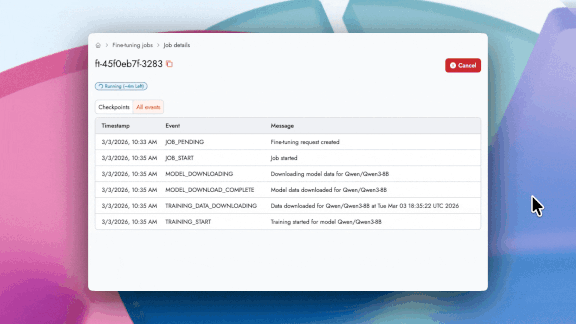
Time Estimation: Track a live progress bar with an estimated completion time that dynamically updates as the job runs.
Get Started
→ Cookbook links:
→ Read Fine-tuning Documentation