

Summary
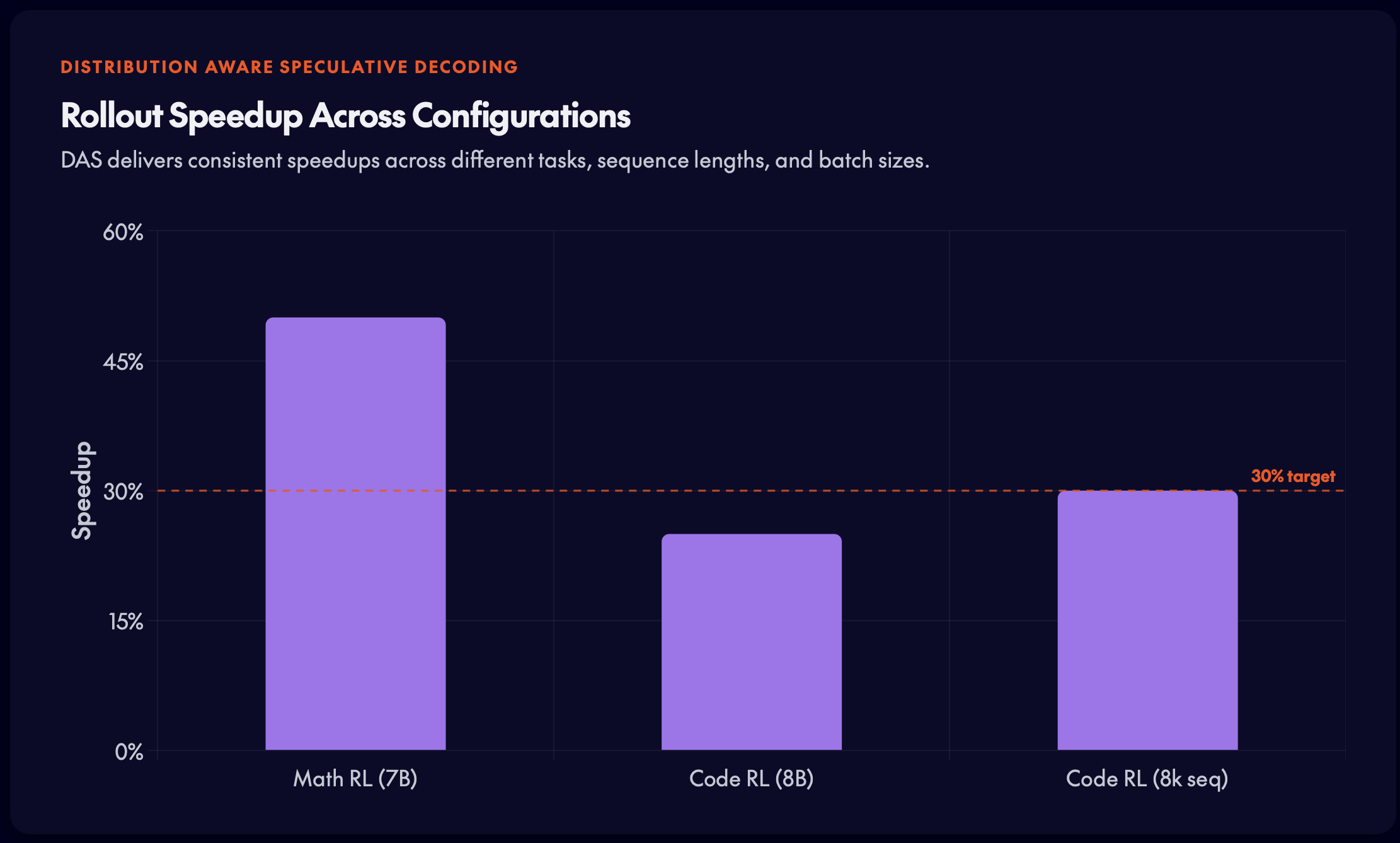
Distribution-aware speculative decoding (DAS) is a novel framework that significantly alleviates the rollout bottleneck in RL post-training — delivering up to 50% speedup without touching model outputs.
The rollout bottleneck
Reinforcement learning has become the cornerstone of modern LLM post-training. Models like DeepSeek-R1 owe their reasoning capabilities to RL fine-tuning. But as models grow larger, a critical bottleneck has emerged: the rollout phase.
In RL training, the model must generate complete responses to every prompt in a batch before the next training step can begin. The slowest generation determines total step time — a textbook long-tail problem.
70% of total training time is consumed by the rollout phase — exceeding the cost of backpropagation and parameter updates combined.
- Synchronous barrier: All rollouts must complete before training proceeds. One slow generation blocks the entire batch.
- Growing lengths: Modern reasoning models generate increasingly long chains of thought, amplifying the long-tail effect.
- GPU idle time: As stragglers run, other GPUs sit idle — wasting thousands of dollars of compute per training run.
Key insights
The rollout phase in RL post-training has three structural properties that set it apart from standard LLM serving workloads. These properties motivate the core design choices in DAS.
- Long-tail rollouts cause GPU underutilization: RL rollouts follow a long-tail distribution: most generations finish quickly, while a few produce extremely long trajectories. Since training steps must wait for all rollouts to complete, these long sequences become stragglers that determine step latency. As shorter requests finish early, GPUs become idle, causing severe hardware underutilization.
- Historical trajectory signal: Unlike serving (unique requests), RL training revisits the same prompts across epochs — creating a rich history of prior generations to exploit.
- Evolving model weights: The model changes after every optimizer step. A static drafter trained on an earlier checkpoint quickly becomes misaligned with the current policy.
The DAS framework
Each of those properties points to a design requirement:
- A drafter that stays current without retraining
- A scheduler that neutralizes stragglers, and
- A system that exploits the prompt reuse unique to RL.
DAS addresses all three through two tightly integrated components. The first is an adaptive suffix tree drafter that accelerates generation and scales gracefully over long training horizons. The second is a length-aware scheduling strategy that reduces rollout stragglers through inter-GPU load balancing and intra-GPU speculation budget allocation.
Adaptive suffix tree drafter
Why suffix trees?
As the policy evolves throughout RL training, a static drafter quickly becomes stale. DAS therefore uses a training-free drafter built from recent rollouts, so it can continuously adapt to the changing policy without any gradient updates.
How it works
DAS constructs a suffix tree from a sliding window of recent trajectories. During decoding, it finds the prefix match between the current context and the indexed history. Candidate next tokens are then scored by their frequency in the matched subtree, and the highest-scoring token is selected as the speculative draft.
WHy it fits RL rollouts
The drafted sequence is verified in parallel by the target model, and newly verified tokens are immediately inserted back into the tree, keeping the drafter synchronized with the latest policy at all times. Since RL rollouts often contain strong trajectory reuse, this nonparametric design can effectively exploit repeated prefixes without requiring a separate neural drafter.
Scalability
Suffix trees are constructed before rollout and released after each training step, so memory does not accumulate over long training horizons. Tree construction and cleanup are parallelized per problem and overlapped with actor updates, leading to less than 5% fluctuation in actor update latency and keeping the overhead off the critical path.
Length-aware scheduling
Inter-GPU balancing
DAS interleaves long requests across ranks. This prevents long generations from concentrating on one worker and reduces rollout stragglers.
Early speculation for long requests
DAS applies speculative decoding to long requests from the start of rollout. Rollout latency is dominated by a few long stragglers that survive into the late stage, where decoding becomes small-batch and strongly memory-bound. Spending extra compute on these requests early is worthwhile — it avoids expensive late-stage model forwards and shortens the rollout tail.
Intra-GPU budget allocation
Within each GPU, requests are dynamically partitioned into Long, Medium, and Shortcategories based on historical rollout statistics. Long requests receive an aggressive speculative decoding budget, medium requests use a moderate budget, and short requests skip speculation entirely — avoiding wasted compute where speculation cannot reduce model forward passes. This classification policy updates dynamically at runtime.
The design is simple enough to describe in a few paragraphs. The results are what validate it.
Experimental results
DAS was evaluated on two RL post-training tasks — math reasoning and code generation. In both cases, the metric that matters is rollout time reduction without any degradation in reward quality.
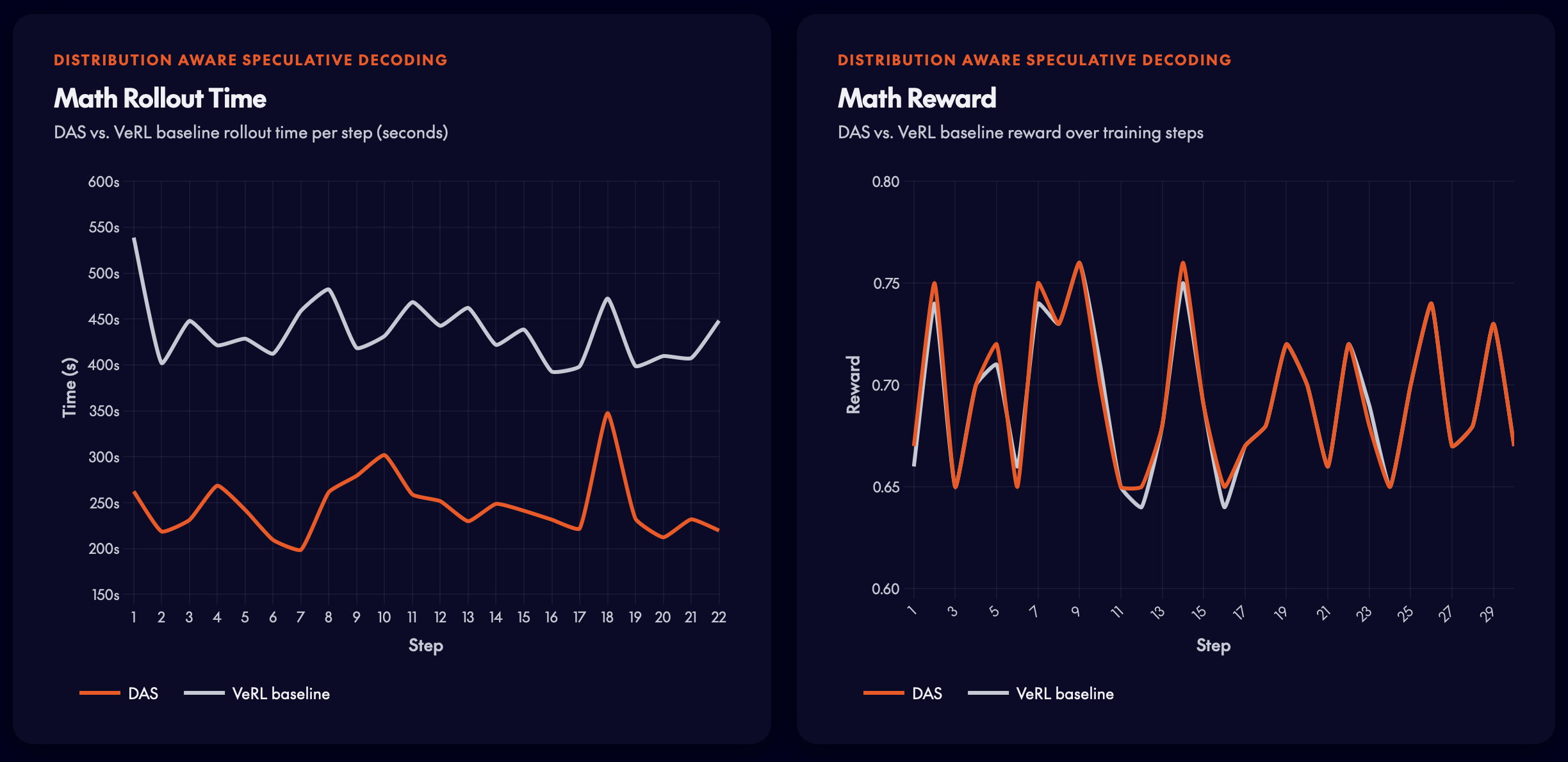
Math RL — DeepSeek-R1-Distill-Qwen-7B
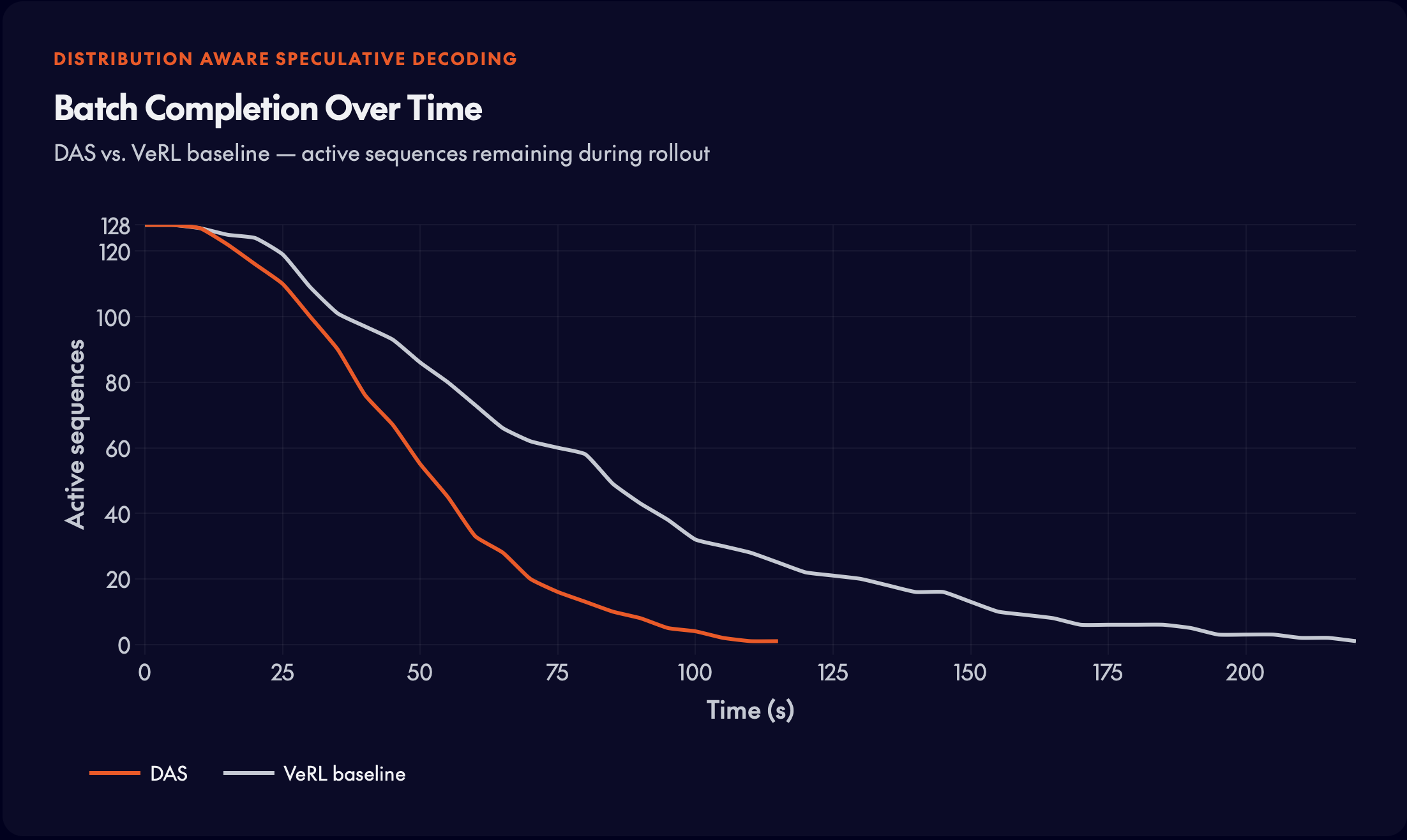
DSR-sub dataset (1,209 examples). DAS achieves over 50% rollout time reduction while matching the baseline reward curve exactly.
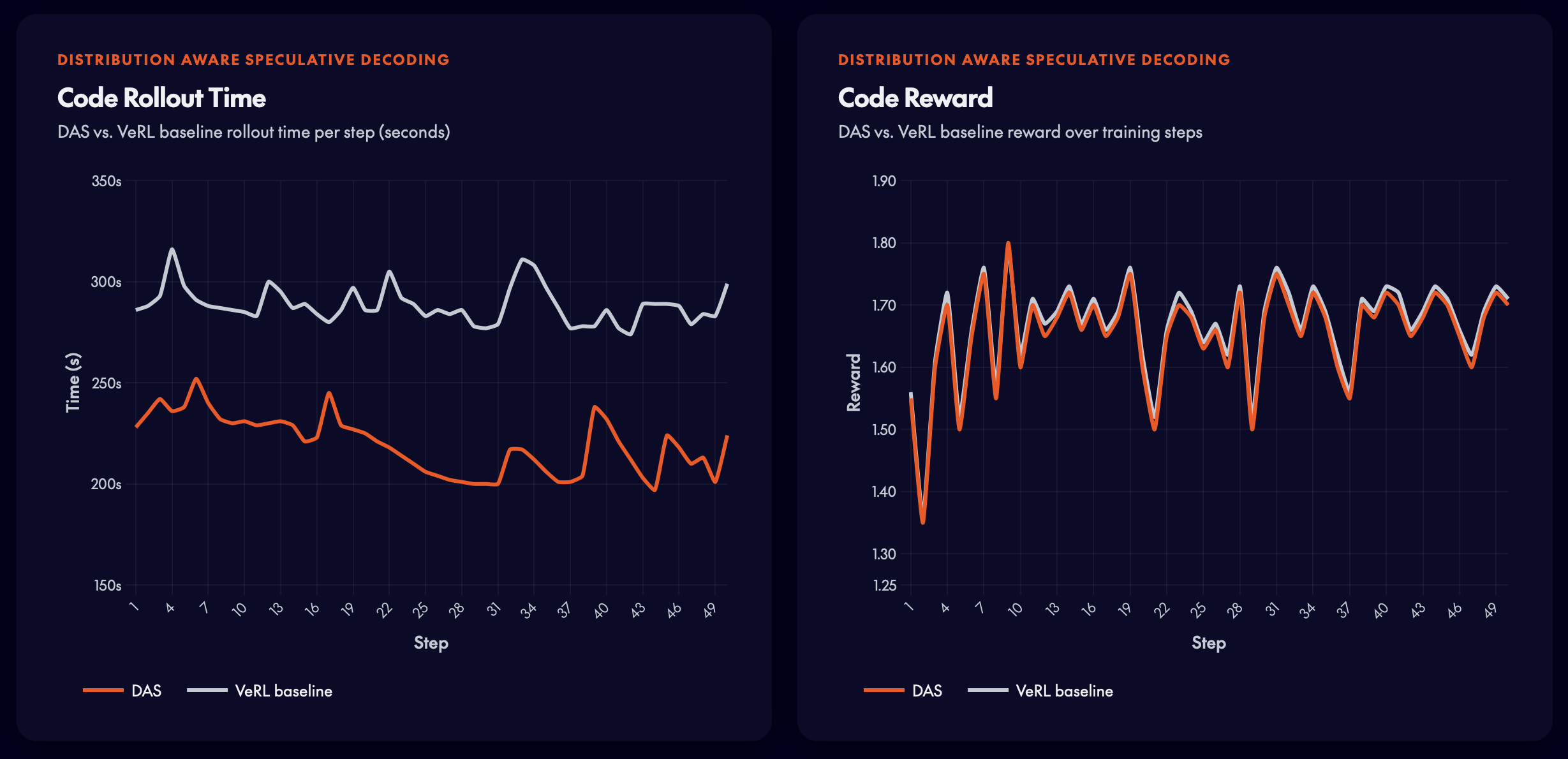
Code RL — Qwen3-8B
Unit-test reward signals. DAS achieves ~25% rollout time reduction while preserving reward quality.
Why this matters
DAS delivers three properties that are rare to find together:
- Lossless acceleration: DAS is distribution-preserving — identical outputs to standard decoding, identical training curves.
- Robust across configurations: Speedup holds across sequence lengths (8k–16k) and batch sizes (16–32).
- Zero-cost adaptation: The suffix tree drafter self-evolves from rollout history. No gradient updates, no maintenance.
As the AI community pushes toward ever-larger models trained with RL on increasingly complex tasks, the rollout bottleneck will only grow more severe. For practitioners running RL post-training at scale, DAS offers a compelling path to cutting compute costs by up to 50% with no degradation in model quality — a rare win-win in the resource-constrained world of large-scale AI training.
Read the paper to learn more.