

Summary
On a production coding agent workload, Together Inference Engine delivers 31% more TPS than the next fastest OSS engine on the same hardware, and maintains 2× better TTFT at saturation. The gains come from full-stack optimization: ThunderMLA, custom kernel rewrites, and end-to-end profiling on real traffic.
Most inference benchmarks measure a single user hitting a dedicated endpoint. The numbers look great. They're also useless for reasoning about production.
In production, you're running dozens or hundreds of concurrent requests. They compete for the same KV cache, the same memory bandwidth, the same GPU cycles. What matters is what happens to every user when the system is under load.
We built this benchmark to answer that question for coding agents. It's a workload that hits inference hard: long inputs, high concurrency, and no tolerance for latency degradation under load.
This is version one. We'll update it as we build.
What a coding agent workload looks like
Coding agent requests carry a lot of context. The file being edited, surrounding code, conversation history, retrieved snippets. Inputs are long. Outputs are meaningful but bounded; you're generating a function, not an essay.
The harder challenge is concurrency. Many users hit the endpoint simultaneously, and those requests interact in ways single-user benchmarks never capture. As traffic increases, KV cache fills. Scheduling pressure mounts. Per-user throughput drops. Time to first token (TTFT) climbs. At some point, the system stops being useful. Different engines reach that point at very different traffic levels.
We designed a high-traffic benchmark to stress-test this, modeled on the request distributions we see serving production coding agent traffic at scale. Prompt lengths range from ~45k to 200k tokens, simulating realistic coding session growth, and generation lengths average around 450 tokens. The key metrics are TPM (input tokens per minute), TPS (tokens per second) per user, and p50 TTFT.
What inference has to get right
For coding agents, TTFT is the metric that determines whether the tool feels fast or broken. A developer who submits a request sees nothing until the first token arrives. That gap — between submit and stream — is where trust is won or lost. Output speed matters, but it's secondary: once tokens are streaming, the experience feels fluid even at moderate generation rates.
The second constraint is concurrency under long context. Coding agent requests aren't just long — they're long and simultaneous. Dozens of developers hitting the same endpoint at once, each carrying 80k+ tokens of context, creates KV cache pressure that single-user benchmarks never surface. As cache fills, the scheduler has less room to maneuver. Prefill latency climbs. TTFT degrades. At high enough traffic, the system stops being useful before it formally fails.
The third constraint is output shape. You're generating a function, not an essay. Generation lengths are bounded — averaging around 450 tokens — which means throughput-at-saturation looks different here than in summarization or document-generation workloads. The system isn't under sustained decode pressure; it's under sustained prefill pressure, with frequent short bursts of decode. Engines optimized for long decode runs won't necessarily win here.
These three constraints — TTFT sensitivity, concurrent long-context load, and prefill-heavy output shape — are what the benchmark is designed to stress.
Methodology
Hardware: 4× NVIDIA B200 per engine (SGLang: 8× B200 — see note below).
Workload: Long prompts, high concurrency, realistic churn. Prompt lengths range from ~45k to 200k tokens, simulating realistic coding session growth. Generation lengths average 450 tokens (p50: 293, p99: 2,230). Difficulty scales with traffic: at higher QPS, longer prompts and growing KV caches create more prefill pressure, more context to maintain, and more KV cache thrashing as session churn increases.
EAGLE speculative decoding: 3 draft tokens. Acceptance rate (~70%) emerges naturally from the realistic synthetic prompt data — we're not forcing it.
Engine configs: TensorRT-LLM is well-tuned for this workload and represents a strong baseline. SGLang was configured to match where possible; we didn't run exhaustive tuning experiments, so there may be marginal room for improvement. All engines are configured for low latency. This is distinct from a throughput-optimized config, which would increase max decode batch size and use prefill-decode disaggregation to trade output TPS for higher input TPM.
What we optimized
Our performance gains came from treating inference as a full-stack problem: profiling end-to-end, identifying the most expensive operations, and eliminating them one by one.
ThunderMLA. Kimi K2.5 uses DeepSeek's Multi-head Latent Attention (MLA) architecture. Standard implementations run two separate kernel launches per decode step. Our ThunderMLA — part of our ThunderKittens kernel library — fuses these into a single megakernel, eliminating launch overhead and the tail effects between them. On representative decode workloads, ThunderMLA is 20–35% faster than DeepSeek's own FlashMLA.
Beyond ThunderMLA, we profiled the full stack — driver behavior, memory layout, kernel execution — and removed every bottleneck we found. Some required configuration changes. Others required writing kernels from scratch. The kernels we wrote outperform TensorRT-LLM's open-source equivalents on this workload.
Here's how that translates to the full system under load.
Results
We compared Together Inference Engine against two baselines on Kimi K2.5 with EAGLE speculative decoding:
- TensorRT-LLM — 4 x NVIDIA B200 GPUs
- SGLang — 8 x NVIDIA B200 GPUs
A note on SGLang: Running Kimi K2.5 with EAGLE on SGLang at TP4 ran out of memory — SGLang's EAGLE implementation requires more memory than TensorRT-LLM's on this model. We used TP8 (8 GPUs) to run it. TensorRT-LLM and Together Inference Engine ran on 4 GPUs.
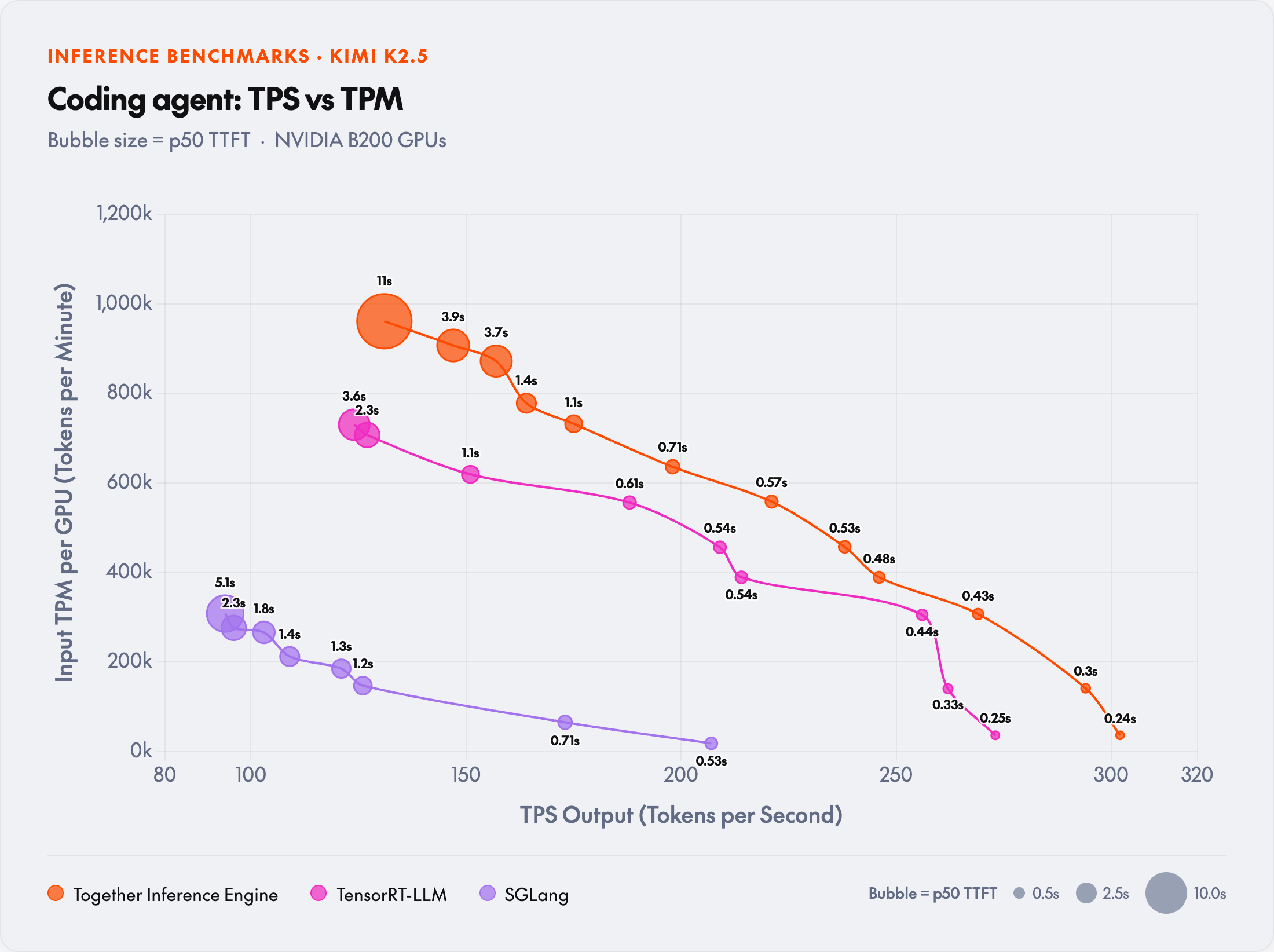
At 625 TPM per GPU (2.5M TPM total), Together Inference Engine delivers 31% more TPS than TensorRT-LLM and is the only engine still under 1s TTFT.
The degradation curve
The shape of the curve matters more than any single data point. Every inference engine eventually saturates: KV cache fills, scheduling pressure increases, TTFT climbs. What differs between engines is when that happens and how fast.
At 2.5M TPM, every engine is past its comfortable range:
At the traffic level where all engines are degrading, Together IE's TTFT is 2× better than TensorRT-LLM's and 3× better than SGLang's. The system has more headroom: functional at loads where other engines are not.
Cost and quality
The performance benchmarks in this post are on Kimi K2.5. Kimi K2.6 is now available on Together, and on coding benchmarks it matches or beats Claude Opus 4.6 across the board.
At that quality level, the cost difference is significant. For a typical request on this workload — ~80k-100k input tokens, ~450 output tokens:
70% cheaper per request. A 150-person engineering team running a coding agent at 7.5M TPM for 5 hours a day (250 working days) saves ~$421K/year on inference costs vs. Claude Opus 4.8.
This is version one
These results reflect where Together Inference Engine stands today, on this workload, on this hardware configuration. We're publishing them because we think benchmarks should be meaningful: based on real workload shapes, transparent about methodology, and honest about where things start to break.
Each update will be additive. The goal is a running record of what optimization actually buys you on a workload you can reason about. When the next one ships, we'll show you exactly what changed and why the numbers moved.
If you're running a coding agent at scale and want to understand what this means for your workload, reach out.