
.png)
Together Research is announcing FlashAttention-4, Reinforcement Learning API, ThunderAgent, ATLAS-2, and more at AI Native Conf.
The AI Native Cloud is more than a positioning statement. It is a full-stack AI cloud that is purpose-built for AI-natives by researchers and engineers who have delivered foundational AI work such as FlashAttention and ThunderKittens. The same people who published that research are the ones running the production systems our customers, such as Cursor and Decagon, depend on. That proximity is hard to replicate. When a technique comes out of our research program, we can quickly move from research to production and ship these techniques for our customers' immediate benefit.
Today at the first AI Native Conf, we are announcing seven research and product releases across three areas: Kernels, reinforcement learning, and algorithmic inference optimization. Each one represents a massive advancement from our research-to-production pipeline for customers to use.
Kernels
FlashAttention-4
FlashAttention is the attention engine powering many large-scale, frontier language models in production today. The research program led by Chief Scientist Tri Dao continues to push the limits of how fast attention can run. FlashAttention-4 pairs a new algorithm with a kernel co-design tuned for NVIDIA Blackwell GPUs, removing the new bottlenecks so the tensor cores stay busy.
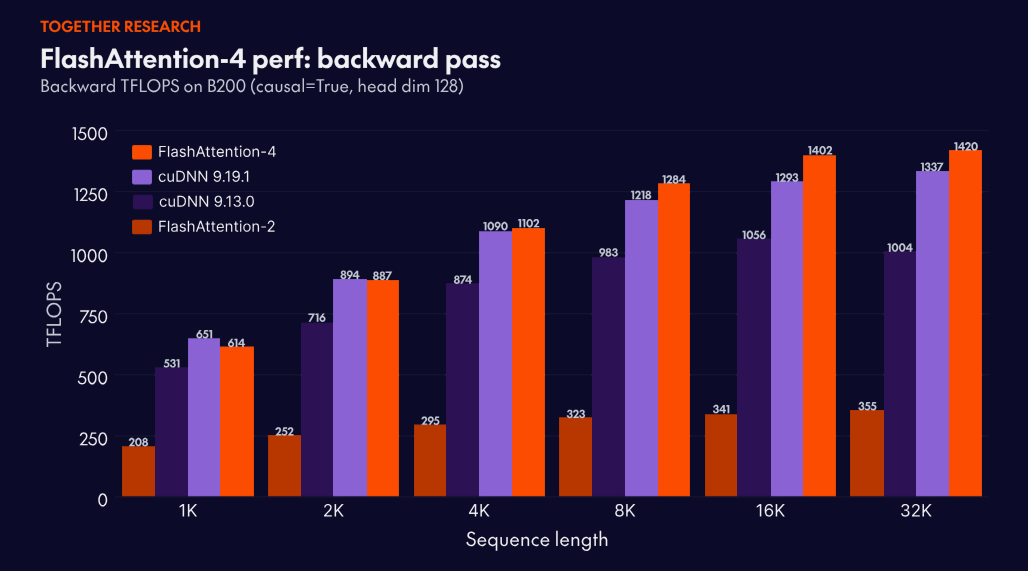
It is 2.7x faster than Triton and 1.3x faster than cuDNN 9.13. For long context workloads like video understanding, coding agents, and test time compute scaling, this enables more intelligent capabilities at a lower cost per token on the latest NVIDIA GPUs.
Read the FlashAttention-4 launch blog.
Together Megakernel
One of the leading real-time voice agent companies came to Together with a hard constraint: time-to-first-64-tokens above roughly 100ms breaks the conversational experience. On their previous setup, deployed on NVIDIA B200 GPUs, they were hitting 281ms. Fast for most workloads, but not fast enough for theirs.
Together's kernels team worked with them to select a model architecture, then hand-optimized a Megakernel implementation that runs an entire model in a single kernel, targeting the HBM bandwidth ceiling of the NVIDIA H100.
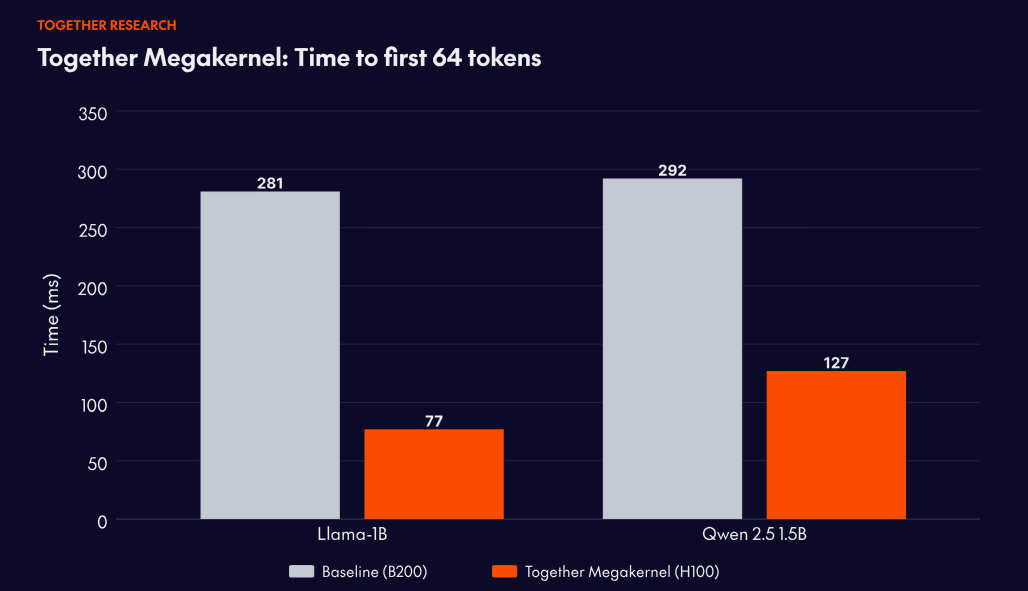
The resulting deployment hit 77ms — a 3.6x performance improvement with 7.2x better unit economics compared to their prior deployment. Together Megakernel is the production implementation of open-source research initially developed with collaborators at Stanford. Backed by the same research lineage as FlashAttention, it's hardware-software co-design that closes the gap between what's theoretically possible and what deployed systems deliver.
together.compile
The kernel optimization that produces results like Together Megakernel has historically required specialists — engineers who understand GPU thread-block mapping, memory bandwidth constraints, and hardware-specific tuning at a depth most teams don't have on staff. together.compile automates much of that process.
An extension of ThunderKittens, together.compile generates an optimized kernel stack at startup with a single function call — no changes to model code required. When applied to Hedra's Omnia video model, together.compile accelerated generation of 200 frames by 25%.
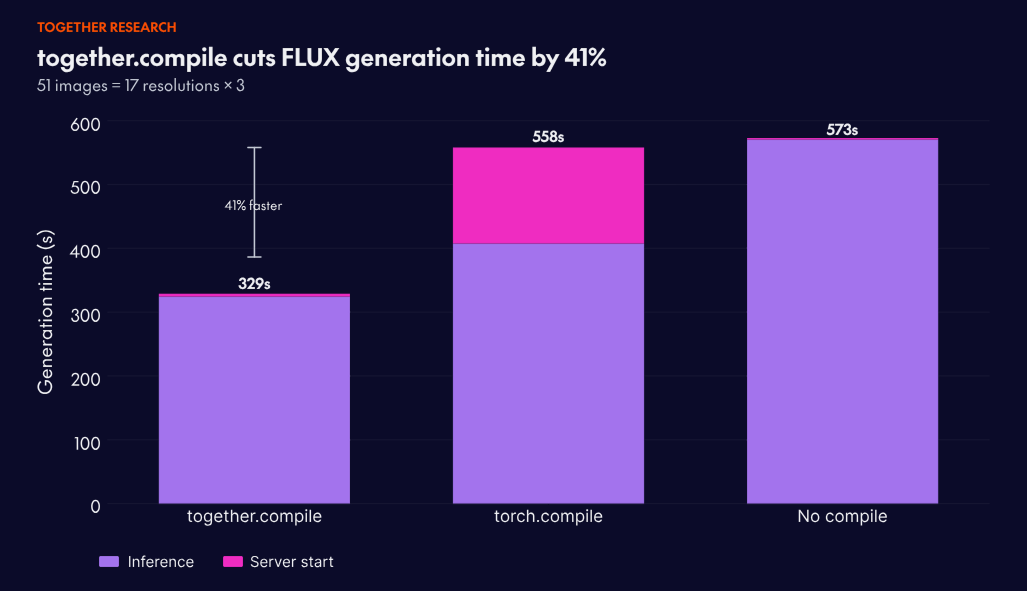
In production Flux Kontext benchmarks, server startup plus generating 51 images across 17 resolutions completes in 329 seconds with together.compile, versus 558 seconds with torch.compile: A 41% improvement. Startup time drops as well, which matters for teams running autoscaled image and video generation at volume.
together.compile is coming soon to Together Dedicated Container Inference. Get in touch if you’d like to join the beta.
Reinforcement Learning
Reinforcement Learning API
Together's Reinforcement Learning API brings the full Together stack to RL training. The kernels, inference optimizations, and research advances that power production inference on Together now apply directly to rollout-heavy workloads — the bottleneck that dominates RL wall-clock time.
The API gives teams control, not a black box. Inference and training are exposed as separate, configurable layers — teams decide rollout configuration, weight push frequency, and where compute runs. Together handles synchronization and scheduling; the decisions about how to run RL remain yours. This level of abstraction lets teams actually optimize their training loop, rather than working around someone else's assumptions about how RL should work.
Over 70% of RL wall-clock time is rollouts — inference — and that's where Together's research program directly applies. Distribution-aware speculative decoding and ThunderAgent both target the throughput and latency characteristics that make rollouts fast, translating each research advance into faster RL training cycles.
The remaining bottleneck is weight distribution: Getting updated weights to inference nodes after each training step. Within a datacenter, Together pushes new weights to all inference nodes in seconds. At global distributed scale — nodes across regions, different GPU types — synchronization completes in under one minute.
ThunderAgent
The Reinforcement Learning API handles the infrastructure layer. ThunderAgent addresses what happens when the workloads being trained and served are themselves agentic — coding agents, scientific discovery agents, multi-step reasoning pipelines running at scale.
Existing inference systems handle agentic workflows as sequences of independent, stateless requests. This creates three compounding problems:
- KV cache thrashing (repeated context recomputation when tool calls interrupt execution)
- Cross-node memory imbalance (some GPU nodes overloaded while others sit idle)
- Tool lifecycle obliviousness (Docker sandboxes and network ports accumulating without being reclaimed)
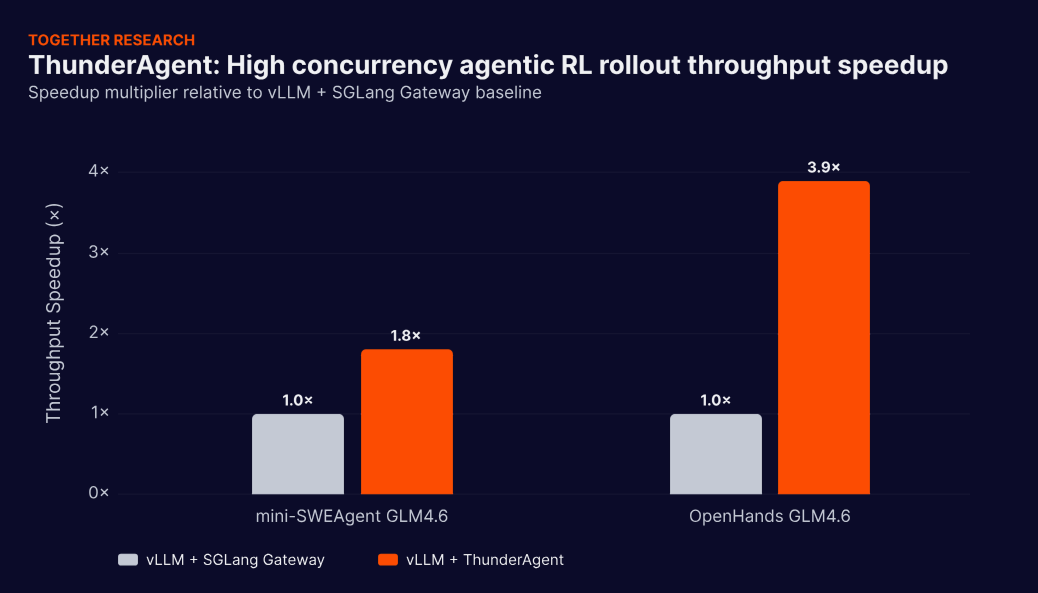
ThunderAgent solves all three by introducing a program-aware abstraction — treating each agentic workflow as a first-class scheduling unit with a view across the full execution. The results: 1.5–3.6x throughput improvements for agentic serving, 1.8–3.9x for RL rollout on distributed GPU clusters, and 4.2x disk memory savings over prior state-of-the-art systems. ThunderAgent is open-sourced today, and is the research foundation for how high-throughput agentic training will be built.
Algorithmic inference optimizations
ATLAS-2
Speculative decoding — using a small draft model to propose tokens that a larger target model verifies — is one of the most effective techniques for reducing inference latency. The problem with how it's deployed today: a speculator is trained offline, shipped as a fixed artifact, and degrades as the target model updates or traffic patterns shift. Retraining requires weeks of pipeline work and large volumes of target model activations.
ATLAS-2 introduces an online training flywheel, using accepted and rejected tokens as signals to continuously update the speculator from live traffic. New speculator versions are hot-swapped into production without service interruption.
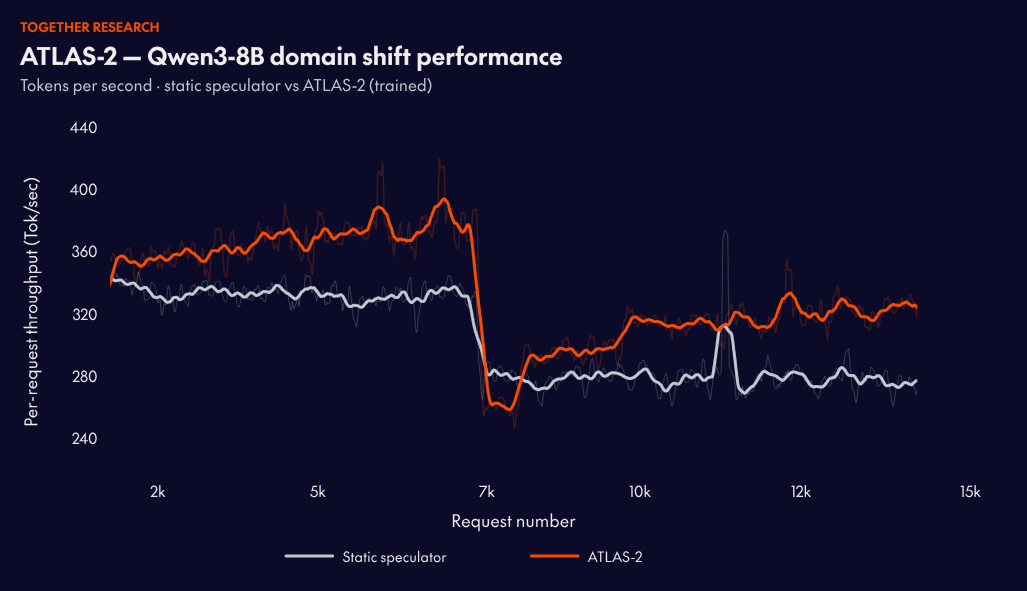
On established models with existing static speculators, ATLAS-2 adds a further 1.2x performance improvement. That gap compounds: static speculators are trained once and, as traffic distributions shift, their acceptance rates decay. ATLAS-2 keeps adapting, so performance improves as distributions change rather than degrading with them.
Read about Aurora, the open source framework behind ATLAS-2.
Cache-aware prefill–decode disaggregation (CPD)
Up to 40% higher sustainable throughput for long-context inference.
Standard prefill–decode disaggregation separates compute-heavy prefill from latency-sensitive decoding. But all prefills — warm and cold — still compete for the same capacity. In real-world traffic, large cold prompts with 100K+ tokens of new context queue alongside multi-turn requests that contain mostly reusable context. TTFT degrades not because warm requests need heavy compute, but because they're stuck behind the requests that do.
CPD adds a third tier to the serving stack. A cache-aware router classifies each incoming request by cache hit rate and routes accordingly:
- Cold requests go to dedicated pre-prefill nodes that compute new context and populate a distributed KV cache
- Warm requests go to prefill nodes that fetch KV blocks via RDMA instead of recomputing them
- Decode nodes remain isolated and latency-focused.
A three-level KV-cache hierarchy — GPU memory, host DRAM, and a cluster-wide distributed cache connected via RDMA — lets frequently accessed contexts migrate toward the GPU over time. The same 100K-token context that required seconds of compute on first request can be served in a few hundred milliseconds once warmed.
Evaluated on NVIDIA B200 GPUs under a coding-agent workload mixing warm and cold long-context requests, CPD improves sustainable QPS by 35–40% over standard disaggregated designs.
What's Next
Each of these announcements will have its own deep dive. But they share a common thread that's worth naming.
The kernel advances in FA4 directly inform future Megakernel implementations. The program-aware scheduling in ThunderAgent shapes how the Reinforcement Learning API handles agentic training workloads. The online learning loop in ATLAS-2 is a template for how we think about any system that should improve under live traffic, not just speculative decoders. Each piece we ship becomes infrastructure for solving the next problem.
This is the flywheel that "AI native" actually refers to. Research advances the platform. The platform attracts workloads that surface the next hard problems. Those problems drive the next research cycle. The compounding is real, and it's why the gap between what's possible and what's available on Together tends to be smaller than anywhere else. Pure infrastructure companies can deploy what the field produces. Pure research labs can advance what the field knows. The combination — research that runs in production, production that informs research — is what we've been building since day one, and what the announcements above represent.
The most demanding AI applications being built today will need infrastructure that expands the frontier of possibility. That's what we're building at Together.